
ホームページ >データベース >mysql チュートリアル >mysqlギャップロックのロックルールは何ですか?
mysqlギャップロックのロックルールは何ですか?

- PHPz転載
- 2023-06-03 20:41:491630ブラウズ
mysql ギャップ ロック ロックに関する 11 のルール
ギャップ ロックは反復読み取り分離レベルでのみ有効です:ネクストキー ロックは、実際にはギャップ ロックと行ロックによって実装されます。 read-committed分離レベル(read-committed)で説明すると分かりやすいですが、途中でギャップロック部分が削除され、ロウロック部分だけが残ります。読み取りコミット分離レベルではギャップ ロックが存在しないため、データとログ間の不一致を解決するには、バイナリ ログ形式を行に設定する必要があります。つまり、多くの企業の構成は、読み取りコミット分離レベルに binlog_format=row を加えたものになります。ビジネスでは繰り返し読み取りの保証は必要ないため、読み取りサブミット時の操作データのロック範囲が狭い (ギャップ ロックがない) ことを考慮すると、この選択は合理的です。
原則 1: ロックの基本単位はネクストキーロックです。 next-key ロックは、開いた間隔と閉じた間隔です。
原則 2: 検索プロセス中にアクセスされたオブジェクトのみがロックされます。セカンダリ インデックスのロック、またはインデックスのない列のロックは、最終的には主キーまで遡り、ロックは主キーにも追加されます。
最適化 1: インデックスに対する同等のクエリの場合、一意のインデックスをロックすると、ネクストキー ロックは行ロックに縮退します。つまり、InnoDB が主キーまたは一意のインデックスをスキャンする場合、InnoDB は行ロックのみを使用してロックします。
最適化 2: インデックス (必ずしも一意のインデックスである必要はありません) に対する同等のクエリを、右トラバーサル中および最後の値が取得されたときに実行します。が等価条件を満たさない場合、next-keylock はギャップ ロックに縮退します。
バグ: 一意のインデックスに対する範囲クエリは、条件を満たさない最初の値にアクセスします。
CREATE TABLE `test` ( id` int(11) NOT NULL, col1` int(11) DEFAULT NULL, col2` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`col1`) ) ENGINE=InnoDB; insert into test values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);ケース 1: 一意インデックス等しい値クエリ ギャップ ロック
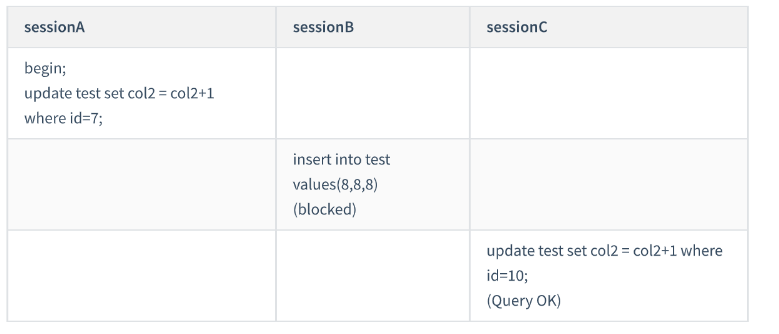

#実行を開始するとき、id=10 の最初の行を見つける必要があるため、ネクスト キー ロック(5, 10]。最適化 1 では、主キー 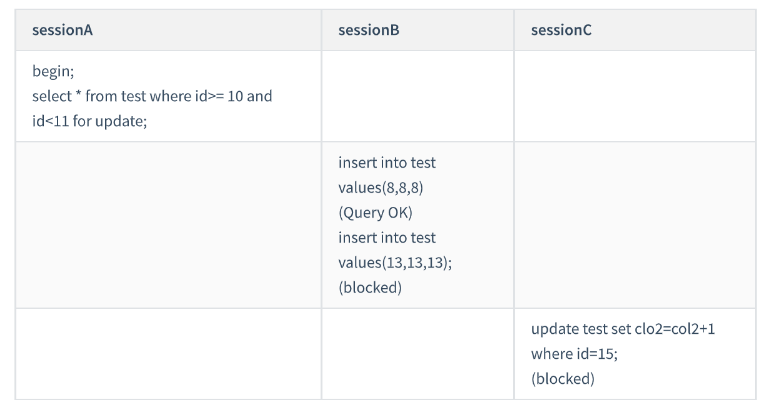 id の等価条件を行ロックに縮退し、行 id=10 の行ロックのみを追加します。
id の等価条件を行ロックに縮退し、行 id=10 の行ロックのみを追加します。
next-key lock( 10,15].
セッション A この時点で、ロックのスコープは主キー インデックス、行ロック ID=10 およびネクスト キー ロック (10,15] です。セッション A が ## で行を見つけたとき#id=10 で初めて同等クエリと判定され、id=15 まで右にスキャンする場合は範囲クエリ判定が使用されます。
ケース 4: 非一意のインデックス範囲クエリ ロック

Col1=10 を使用して初めてレコードを検索する場合、(5,10] が追加されます) to インデックス c この次のキー ロックの後、インデックス Col1 は非専用インデックスであるため、最適化ルールはありません。つまり、行ロックに変換されません。したがって、セッション A に追加される最終ロックは (5 ,10] のインデックス c. と
(10,15] これら 2 つの次のキーロック。
InnoDB は、それを知る前に、col1=15 までスキャンする必要があるため、スキャンを停止する前に、col1=15 までスキャンするのが合理的です。続行する必要はありません。
見つかりました。

が一意のキーであるため、ループは id= の行に到達したときに停止する必要があります。 15.
ただし、実装の観点から、InnoDB は条件を満たさない最初の動作、つまり id=20 までスキャンします。また、これは範囲スキャンであるため、(15,インデックス ID の 20] もロックされます。論理的に言えば、ここで id=20 行をロックする動作は、実際には
不要です。id=15 をスキャンした後は、確認する必要がないことが確認できるためです。
ケース 6: 一意でないインデックスに対する " " 同等の " " の例
ここでは、テーブル t に新しいレコードを挿入します。 ,30); つまり、テーブルには c=10
の行が 2 つありますが、主キー値 ID が異なるため (それぞれ 10 と 30)、c= の 2 つのレコードの間にギャップが生じます。 10.
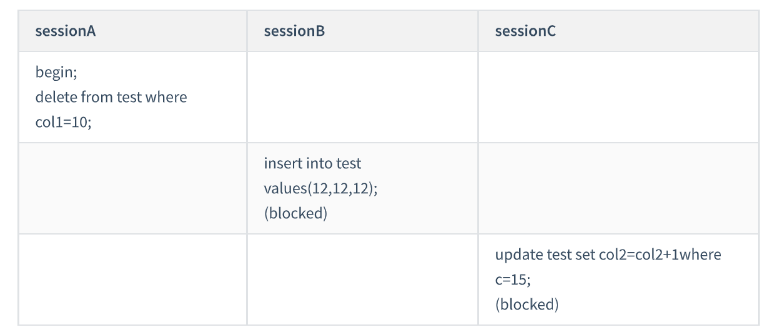 今回は、delete ステートメントを使用して検証します。delete ステートメントのロック ロジックは、実際には select ... for update,
今回は、delete ステートメントを使用して検証します。delete ステートメントのロック ロジックは、実際には select ... for update,
このとき、セッション A は、トラバース時に最初のcol1=10 レコードに最初にアクセスします。同様に、原則に従って1 、ここで追加されるのは、
(col1=5,id=5) から (col1=10,id=10) までのネクストキー ロックです。
c は通常のインデックスなので、検索を続けます。突き当たるまで右へ ループは(col1=15,id=15)の行で終了します。最適化 2 によると、これは
と同等のクエリですが、条件を満たさない行が右側にあるため、(col1=10,id=10) から (col1=15,) までの隙間に縮退します。 id=15)
ロックします。
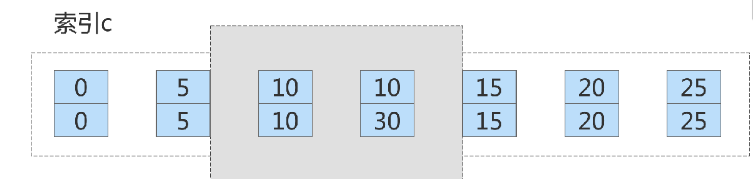 インデックス c 上のこの削除ステートメントのロック範囲は、上図の青い領域で覆われた部分です。この青い領域の左右に
インデックス c 上のこの削除ステートメントのロック範囲は、上図の青い領域で覆われた部分です。この青い領域の左右に
ケース 7: 制限ステートメントがロックされている
 セッション A の削除ステートメントは制限 2 でロックされています。テーブル t には実際には c=10 のレコードが 2 つしかないことがわかっているため、制限 2 を追加または削除しても効果は同じです。ただし、ロックの効果は異なります。
セッション A の削除ステートメントは制限 2 でロックされています。テーブル t には実際には c=10 のレコードが 2 つしかないことがわかっているため、制限 2 を追加または削除しても効果は同じです。ただし、ロックの効果は異なります。
は条件を満たします。すでに 2 つのステートメントがあり、ループは終了します。したがって、インデックス Col1 のロック範囲は、次の図に示すように、(col1=5,id=5)
から (col1=10,id=30) までのフロントオープンおよびバッククローズの範囲になります。
これにより、削除されるデータの数が制御され、操作が安全になるだけでなく、ロックの範囲も縮小されます。 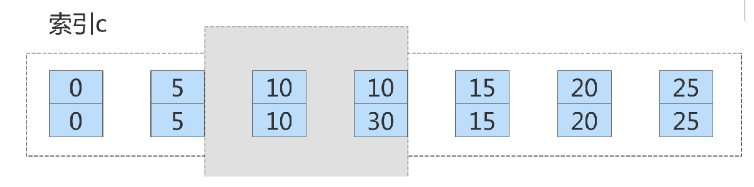
gap lock(10,15) (右へのインデックス トラバーサルはギャップ ロックに縮退します); 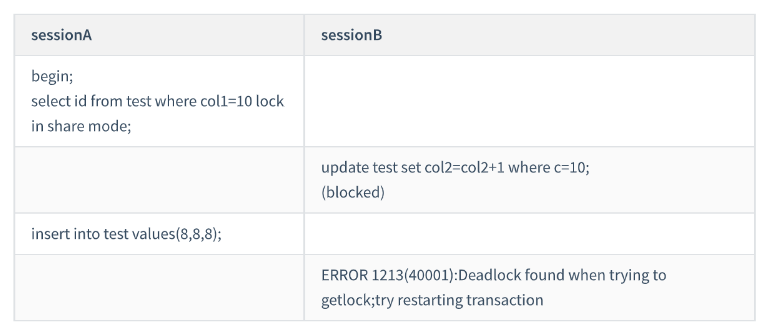 セッション B の更新ステートメントにも next-key lock( 5 ,10]、ロック待機に入ります。これは実際には 2 つのステップに分かれています。
セッション B の更新ステートメントにも next-key lock( 5 ,10]、ロック待機に入ります。これは実際には 2 つのステップに分かれています。
lock is locked. この時点で、デッドロック アプリケーションはブロックされます
次に、セッション A は、行 (8,8,8) を再度挿入しようとしますが、これは、セッション B のギャップ ロック。デッドロックのため、InnoDB は
セッション B をロールバックします
ケース 9: インデックスソートギャップロックによる順序 1
次のようなステートメント
次の図は、このテーブルのインデックス ID の概略図です。
begin;
select * from test where id>9 and id

# まず第一に、このクエリのセマンティクスステートメントは id desc 順に並べられているため、条件を満たすすべての行を取得するには、オプティマイザーはまず「
番目の ID この処理はインデックスツリーの検索処理で得られるもので、エンジン内では本当はid=12の値を見つけたいのですが、最終的に
は見つからず、ギャップ(10,15)が発生してしまいました。 ) 発見された。 (id=15 は条件を満たさないため、ネクストキー ロックはギャップ ロック (10,
15) に縮退します。)
次に、左にトラバースします。トラバース プロセス中に、同等のクエリは存在せず、 id=5 の行でスキャンされ、間隔が左側で開き、右側で閉じているため、ネクスト キー ロック (0,5] が追加されます。つまり、実行プロセス中に、レコードはツリー検索によって検索されます
、「等価クエリ」メソッドが使用されます。
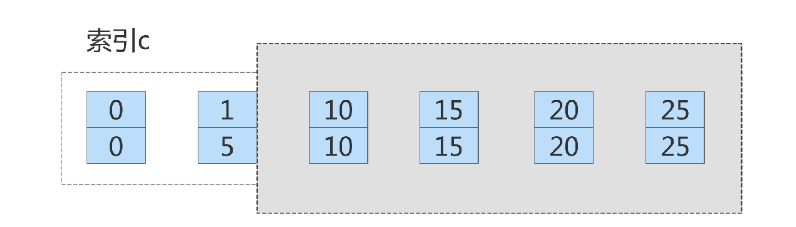
Indexcol1 on (5, 25) となります。 ;
主キーインデックス id=15 と 20 に対する 2 つの行ロック

セッション A のロック範囲は (5) ,10]、(10,15]、(15,20]、(20,25] インデックス Col1 および (25、最高値)。
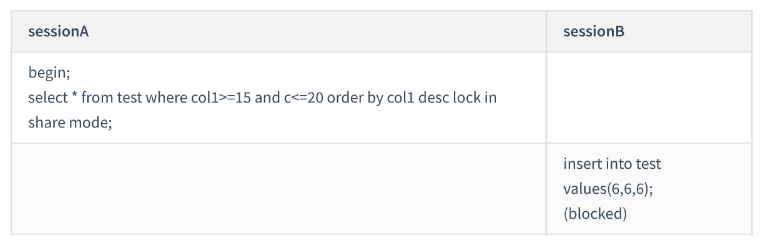
セッション B の最初の更新ステートメントの後、col1=5 を変更する必要があります。
このレコードを挿入 (col1=1, id=5 );
レコードを削除 (col1=5, id=5) という 2 つのステップとして理解できます。
この操作により、セッション A のロック範囲は図 7 のようになります。
レコードの挿入 (col1=5, id=5);
レコードの削除 (col1=1, id=5)。最初のステップは、ギャップ ロックが設定されている (1,10) にデータを挿入しようとしたため、ブロックされました
。
以上がmysqlギャップロックのロックルールは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。