
ホームページ >データベース >mysql チュートリアル >Mysql ストアド プロシージャを使用して数百万のデータを作成する方法
Mysql ストアド プロシージャを使用して数百万のデータを作成する方法

- WBOY転載
- 2023-06-03 19:40:011236ブラウズ
1. 準備
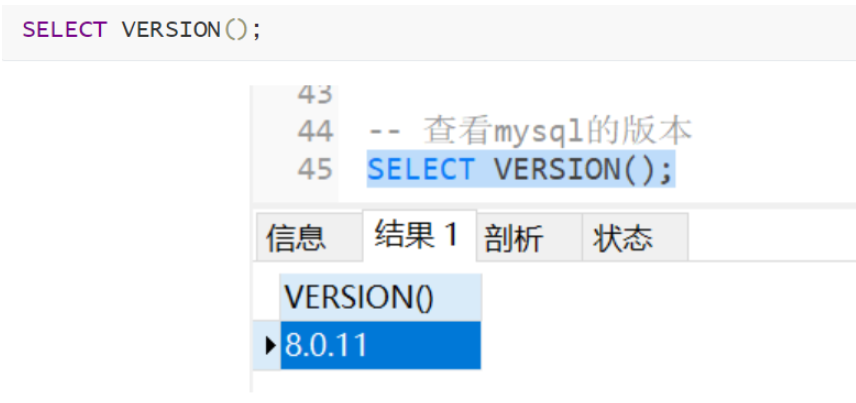
(1) ストアドプロシージャを使用するため、mysql はバージョン 5.0 からストアドプロシージャをサポートするため、mysql のバージョンは 5.0 以降である必要があります。 mysql のバージョンを確認する方法は、次の SQL ステートメントを使用して確認します。
(2) 以下に示すように、同じテーブル構造で異なるストレージ エンジンを持つ 2 つのテーブルを作成します。 , 通常のテーブルは、mysql5.5 バージョン以降のデフォルトの INNODB ストレージ エンジンを使用し、メモリ テーブルは MEMORY ストレージ エンジンを使用します。
MEMORY ストレージは一般的には使用されないため、その特徴を簡単に紹介します。MEMORY エンジンのテーブル構造はディスク上に作成され、すべてのデータはメモリ上に配置され、アクセス速度は高速ですが、 MySQL が再起動されるか、システムがクラッシュすると、データは消えますが、構造はまだ存在します。
# 创建普通表
CREATE TABLE `user_info` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` VARCHAR ( 30 ) NOT NULL COMMENT '用户名',
`phone` VARCHAR ( 11 ) NOT NULL COMMENT '手机号',
`status` TINYINT ( 1 ) NULL DEFAULT NULL COMMENT '用户状态:停用0,启动1',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY ( `id` ) USING BTREE
) ENGINE = INNODB AUTO_INCREMENT = 10001 CHARACTER
SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户信息表';
# 创建内存表
CREATE TABLE `memory_user_info` (
`id` INT ( 11 ) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` VARCHAR ( 30 ) NOT NULL COMMENT '用户名',
`phone` VARCHAR ( 11 ) NOT NULL COMMENT '手机号',
`status` TINYINT ( 1 ) NULL DEFAULT NULL COMMENT '用户状态:停用0,启动1',
`create_time` datetime NOT NULL COMMENT '创建时间',
PRIMARY KEY ( `id` ) USING BTREE
) ENGINE = MEMORY AUTO_INCREMENT = 10001 CHARACTER
SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户信息内存表';2. 主な実装手順
(1) データを自動生成する関数を作成し、挿入時に使用します;
(2) データを挿入するためのストレージ プロシージャを作成しますメモリテーブルに格納し、作成したデータ生成関数を呼び出す;
(3) メモリテーブルのデータを作成し、通常のテーブルストアドプロシージャに挿入する;
(4) ストアドプロシージャを呼び出す。
(5) データの閲覧と検証
3. データを自動生成する関数の作成
(1) n 個の乱数の生成
DELIMITER //
DROP FUNCTION
IF
EXISTS randomNum // CREATE FUNCTION randomNum (
n INT,
chars_str VARCHAR ( 10 )) RETURNS VARCHAR ( 255 ) BEGIN
DECLARE
return_str VARCHAR ( 255 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = concat(
return_str,
substring( chars_str, FLOOR( 1 + RAND()* 10 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
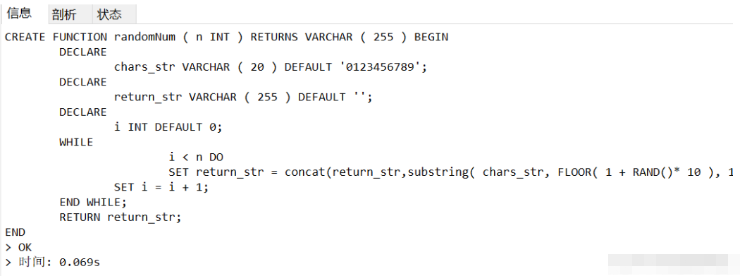
DELIMITER;関数の実行スクリーンショット :
スクリプトで使用される mysql 関数とその機能は次のとおりです:
a.concat(): 複数の文字列を 1 つの文字列に連結します。
b.Floor(): 切り捨て。
c.substring(string, location, length)
最初のパラメータ: string は、インターセプトする必要がある元の文字列を指します。
2 番目のパラメータ: 位置は、部分文字列をインターセプトする位置を指します。ここでの文字の位置エンコード シーケンス番号は 1 から始まります。位置が負の数の場合、位置は右から左に数えられます。 。
3 番目のパラメータ: 長さは、インターセプトする必要がある文字列の長さを指します。書かれていない場合は、位置の先頭から最後の文字までのすべての文字がデフォルトでインターセプトされます。
d.RAND(): 0 から 1 までのランダムな小数のみを生成できます。
(2) 携帯電話番号をランダムに生成する関数を作成します。
DELIMITER //
DROP FUNCTION
IF
EXISTS getPhone // CREATE FUNCTION getPhone () RETURNS VARCHAR ( 11 ) BEGIN
DECLARE
head CHAR ( 3 );
DECLARE
phone VARCHAR ( 11 );
DECLARE
bodys VARCHAR ( 65 ) DEFAULT "130 131 132 133 134 135 136 137 138 139 186 187 189 151 157";
DECLARE
STARTS INT;
SET STARTS = 1+floor ( rand()* 15 )* 4;
SET head = trim(
substring( bodys, STARTS, 3 ));
SET phone = trim(
concat(
head,
randomNum ( 8, '0123456789' )));
RETURN phone;
END //
DELIMITER;関数実行時のスクリーンショット:

(3)ユーザー名をランダムに生成する関数
DELIMITER //
DROP FUNCTION
IF
EXISTS randName // CREATE FUNCTION randName ( n INT ) RETURNS VARCHAR ( 255 ) CHARSET utf8mb4 DETERMINISTIC BEGIN
DECLARE
chars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE
return_str VARCHAR ( 30 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = concat(
return_str,
substring( chars_str, FLOOR( 1 + RAND() * 62 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END //
DELIMITER;関数実行中のスクリーンショット:

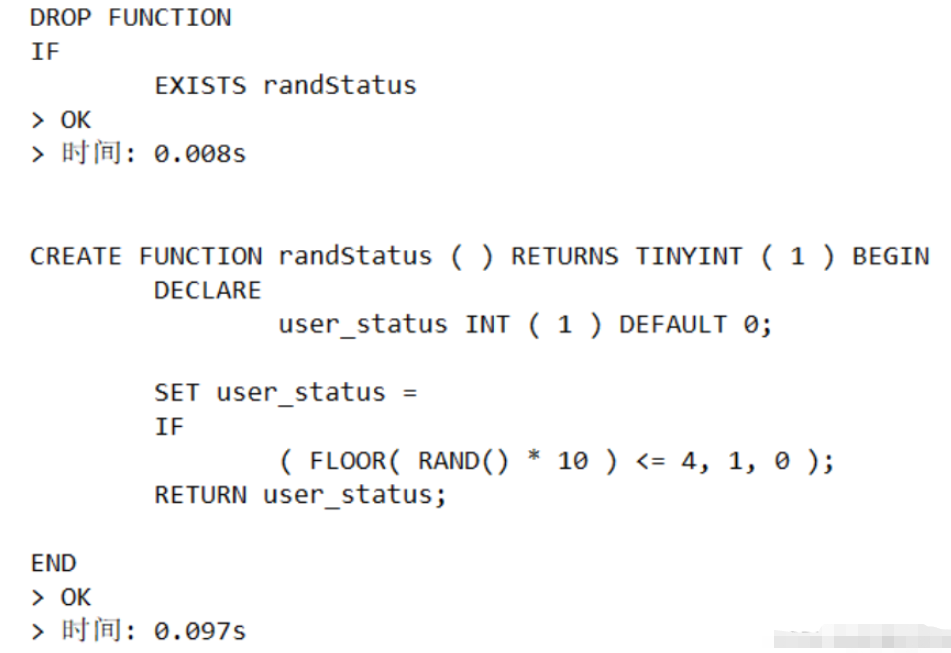
# (4) ユーザー ステータスをランダムに生成する関数
DELIMITER //
DROP FUNCTION
IF
EXISTS randStatus // CREATE FUNCTION randStatus ( ) RETURNS TINYINT ( 1 ) BEGIN
DECLARE
user_status INT ( 1 ) DEFAULT 0;
SET user_status =
IF
( FLOOR( RAND() * 10 ) <= 4, 1, 0 );
RETURN user_status;
END //
DELIMITER;関数実行中スクリーンショット:
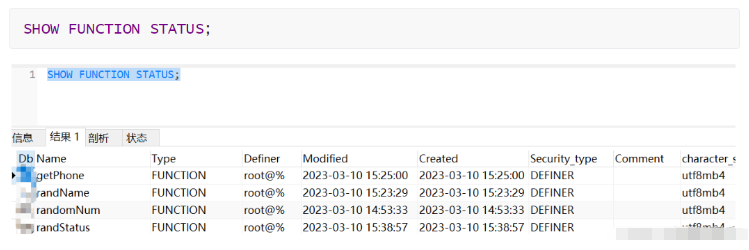
(5) データベース内のすべてのカスタム関数情報の表示
4. ストアド プロシージャの作成
(1) メモリ テーブルにデータを挿入するストアド プロシージャを作成する
DELIMITER //
DROP FUNCTION
IF
EXISTS randStatus // CREATE FUNCTION randStatus ( ) RETURNS TINYINT ( 1 ) BEGIN
DECLARE
user_status INT ( 1 ) DEFAULT 0;
SET user_status =
IF
( FLOOR( RAND() * 10 ) <= 4, 1, 0 );
RETURN user_status;
END //
DELIMITER;入力パラメータ n は、メモリ テーブルに挿入されるデータの数を示します。memory_user_info
スクリーンショット

(2) メモリ テーブル データを作成し、通常のテーブル ストアド プロシージャを挿入します
DELIMITER //
DROP PROCEDURE
IF
EXISTS add_user_info // CREATE PROCEDURE `add_user_info` ( IN n INT, IN count INT ) BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
( i <= n ) DO
CALL add_memory_user_info ( count );
INSERT INTO user_info SELECT
*
FROM
memory_user_info;
DELETE
FROM
memory_user_info;
SET i = i + 1;
END WHILE;
END //
DELIMITER;これがメイン ストアド プロシージャであり、入り口です。 . メモリテーブルの循環挿入と削除を使用して、バッチでデータを生成します. mysql のデフォルトの max_heap_table_size 値を変更する必要はありません (デフォルト値は 16M). max_heap_table_size の機能は、一時メモリのサイズを設定することですユーザーが作成したテーブルで、設定値が大きいほど、より多くのデータをメモリテーブルに保存できます。
ストアド プロシージャの実行スクリーンショット:
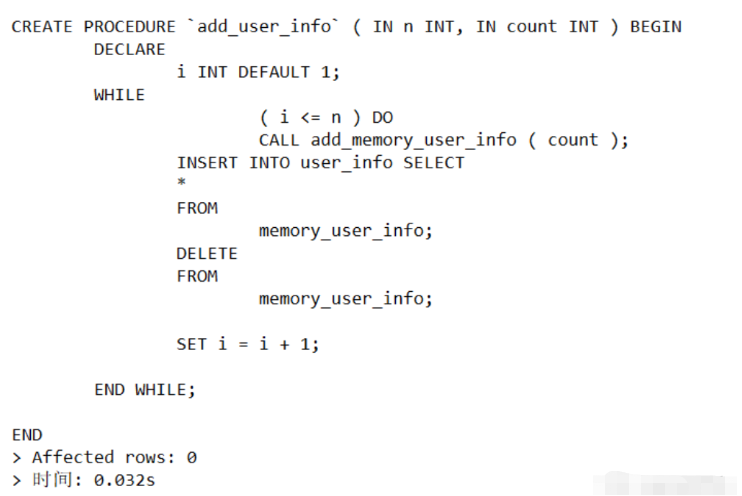
(3) ストアド プロシージャのステータスの表示
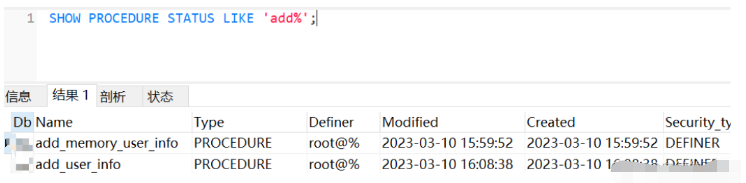
-- 查看数据库所有的存储过程 SHOW PROCEDURE STATUS; -- 模糊查询存储过程 SHOW PROCEDURE STATUS LIKE 'add%';
ファジー クエリの結果:
5. ストアド プロシージャの呼び出し
mysql はストアド プロシージャの実行を呼び出しと呼ぶため、mysql がストアド プロシージャを実行するために使用するステートメントは CALL です。 CALL は、ストアド プロシージャの名前と、それに渡す必要があるパラメータを受け入れます。
add_user_info ストアド プロシージャを呼び出すことで、メモリ テーブルのメモリ ユーザ情報をループ内で連続的に挿入し、メモリ テーブルからデータを取得して通常のテーブル user_info に挿入し、メモリ テーブルのデータを削除します。サイクルはサイクルが終了するまで継続します。 100 回ループし、毎回 10,000 個のデータ、合計 100 万個のデータを生成します。
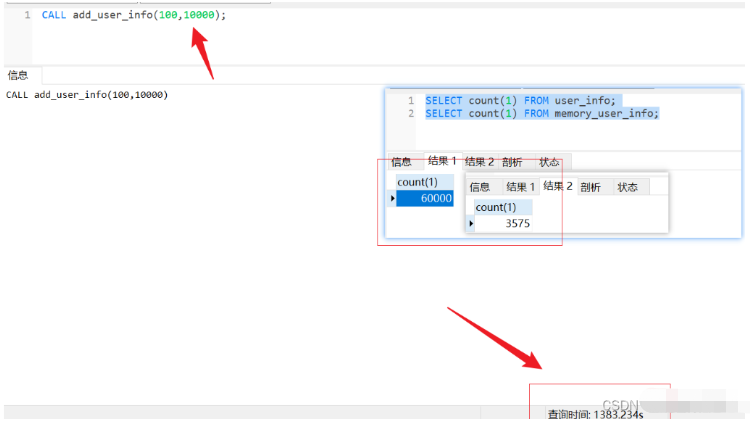
CALL add_user_info(100,10000);
6. データの閲覧と検証
通常のテーブルデータが60,000件になると約23分かかりますが、この時間から1件生成するのに6時間かかると試算されます。約100万件のデータ。時間がかかるのは主に、フィールド データをランダムに生成する 4 つの関数です。フィールド データにランダム性が必要ない場合は、はるかに高速になります。
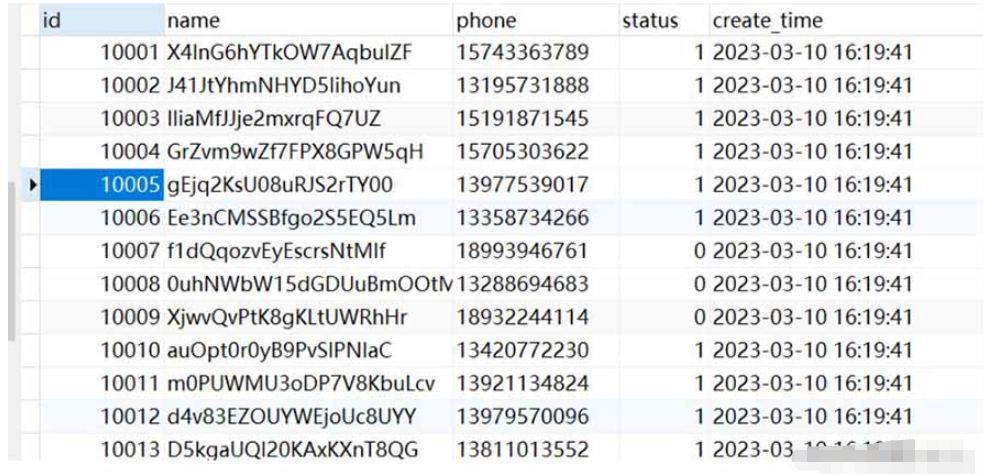
データは次のように記録されます:
以上がMysql ストアド プロシージャを使用して数百万のデータを作成する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。