
ホームページ >テクノロジー周辺機器 >AI >Alibaba Cloudの新大型モデルが登場! AIアーティファクト「Tongyi Listening」がパブリックベータ中:長い動画も1秒に要約可能、自動メモ取りや字幕変換も可能|羊毛も収穫可能
Alibaba Cloudの新大型モデルが登場! AIアーティファクト「Tongyi Listening」がパブリックベータ中:長い動画も1秒に要約可能、自動メモ取りや字幕変換も可能|羊毛も収穫可能

- 王林転載
- 2023-06-03 17:23:111339ブラウズ
大規模なモデル機能にアクセスできるグループ会議用のもう 1 つの実用的なツールが、無料のパブリック ベータ版として公開されました。
その背後にある大きなモデルは、アリババの同宜銭文です。これがグループ会議の魔法のツールと言われる理由については -
ほら、これはステーション B の私の講師、李牧先生です。生徒たちを率いて大きなモデル論文を集中的に読んでいます。
残念なことに、この時点で、上司は私にレンガを早く動かすように促しました。仕方なく、黙ってヘッドフォンを外し、「Tongyi Listening」というプラグインをクリックしてページを切り替えた。 ###############何だと思う?私は「グループミーティング」には参加していませんでしたが、Tingwu はグループミーティングの内容を完全に記録するのに協力してくれました。
キーワード、全文要約、学習ポイントをワンクリックで要約するのにも役立ちました。 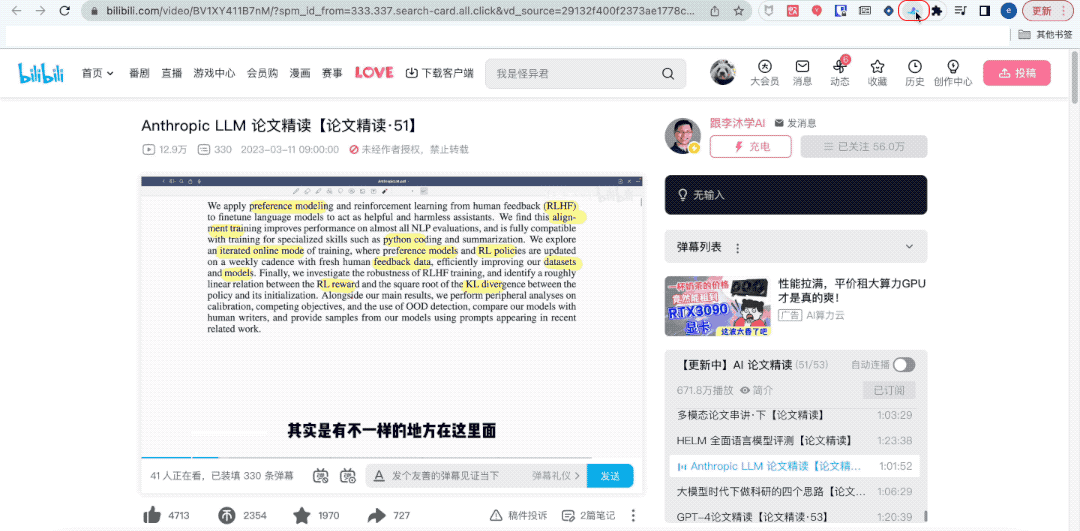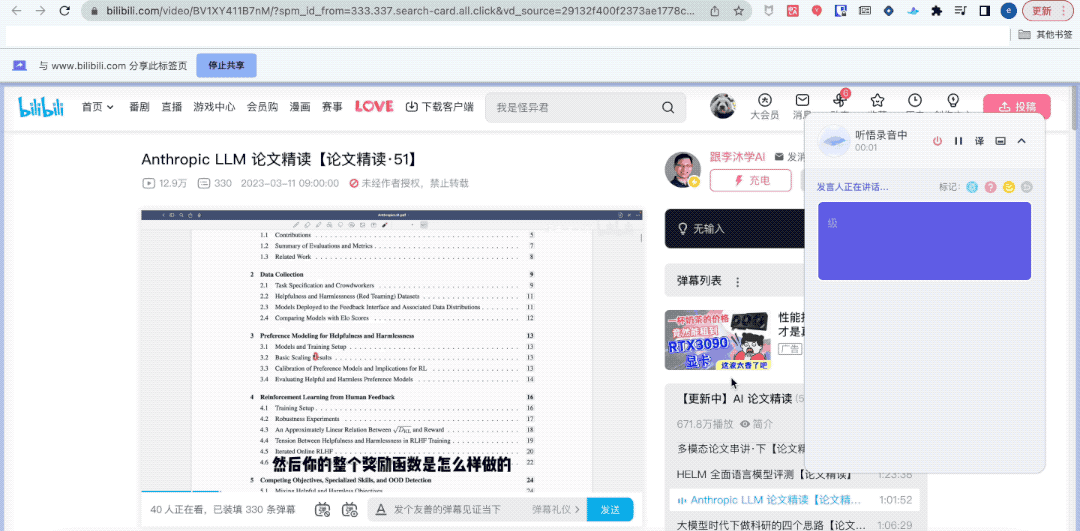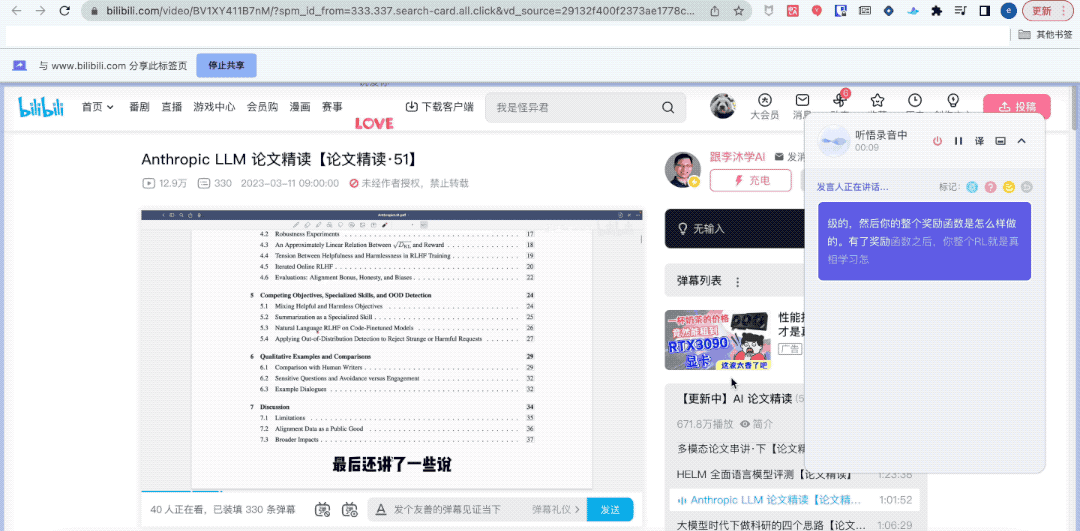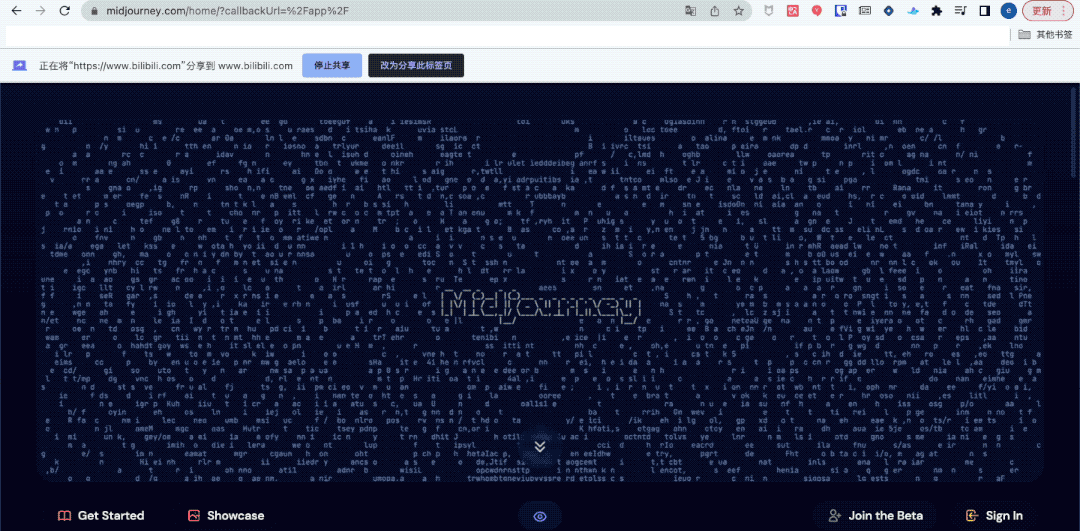
#簡単に言えば、大規模モデル能力にアクセスしたばかりのこの「一般意味聴解」は大規模モデルです。 Focus のバージョン。オーディオおよびビデオ コンテンツ用の仕事と勉強の AI アシスタントです。 
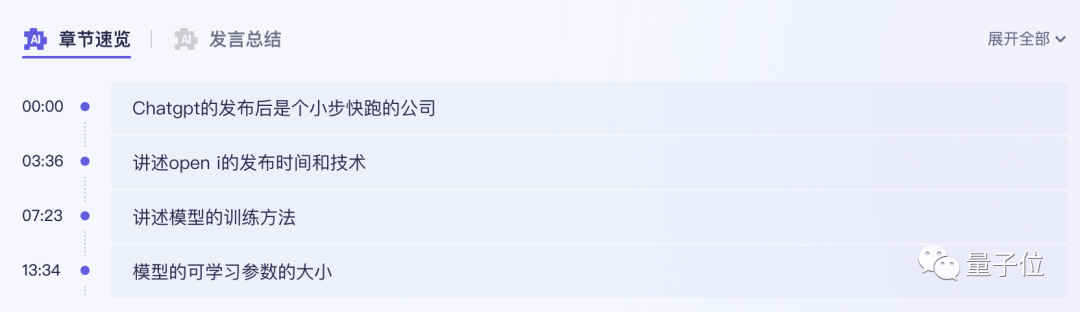
 Tongyi リスニング総合テスト
Tongyi リスニング総合テスト
音声コンテンツの整理と分析において最も基本的かつ重要なことは、文字起こしの正確さです。
ラウンド 1 では、まず約 10 分の中国語ビデオをアップロードして、Tingwu が同様のツールと比較して精度の点でどのように機能するかを確認します。
基本的に、AI はこの中程度の長さの音声とビデオを非常に高速に処理し、2 分以内に文字起こしできます。
まず、Tingwu のパフォーマンスを見てみましょう:


一般に、これらの AI ツールでは中国語の認識は難しくありません。では、英語の教材に直面した場合、彼らはどのようにパフォーマンスを発揮できるのでしょうか?
OpenAI との過去の論争に関するマスク氏の最新インタビューをアップロードしました。
まず、Tingwu による結果を見てみましょう。マスク氏の回答では、ラリー・ペイジ氏の名前を除いて、華武氏は基本的に他の全員を正しく特定した。
Tingwu は、英語の音訳結果を直接中国語に翻訳し、二か国語の比較を表示できることを言及する価値があり、翻訳の品質も非常に優れています。
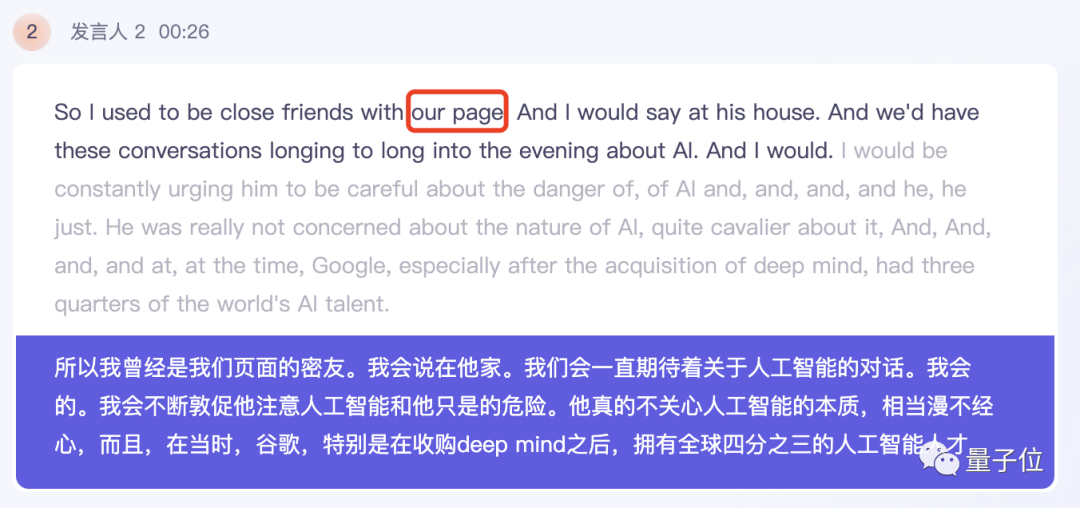
Feishu Miaoji はラリー ペイジの名前を認識することに成功しましたが、Listening と同様に、Musk の全体的な話す速度が速く、口語的なところもあります。表現にはいくつかの小さな間違いがあります。 「この家と言う」の代わりに「彼の家に泊まる」と書く。

ここで iFlytek が聞いたところによると、名前と発音の詳細はうまく処理されていますが、マスクの口語的な表現、たとえば「夕方まで」などに誤解されるケースもあります。 「夕方への憧れ」として。

AI ツールは、音声認識の基本能力に関しては非常に高い精度に達しているようですが、非常に効率が高い一方で、いくつかの小さな問題は解決されています。 . 欠点が長所を隠すことはありません。
次に、難易度をラウンド 2 に上げて、約 1 時間のビデオを要約する能力をテストします。
テスト ビデオは、中国における AIGC の新たな機会をテーマにした 40 分間のラウンドテーブル ディスカッションです。ラウンドテーブルディスカッションには計5名が参加しました。
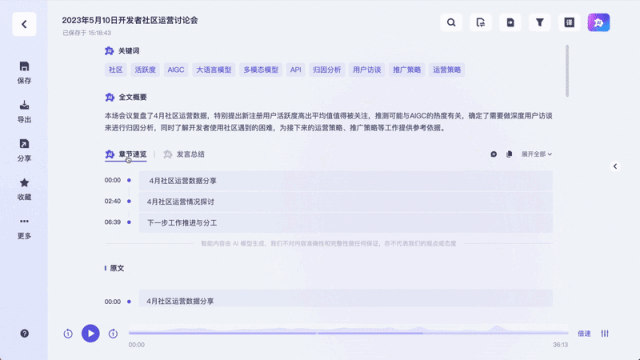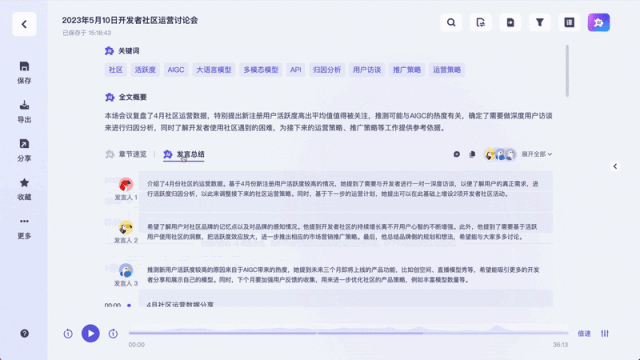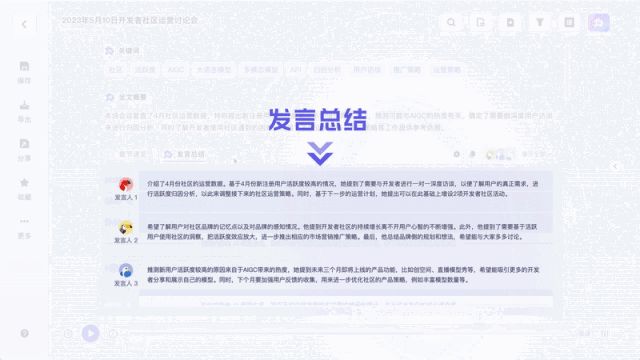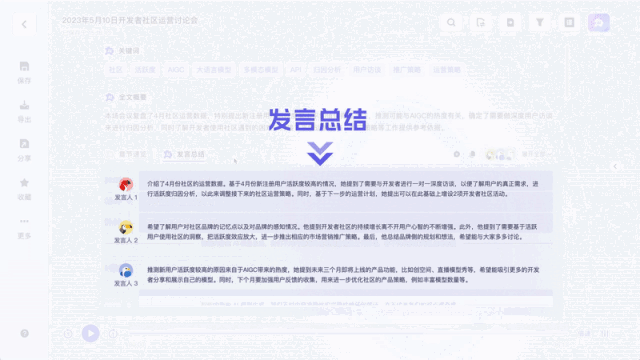
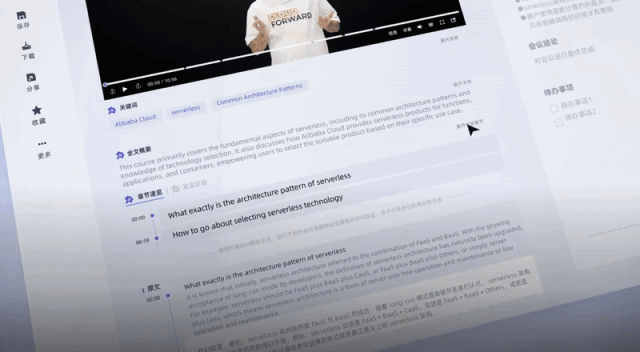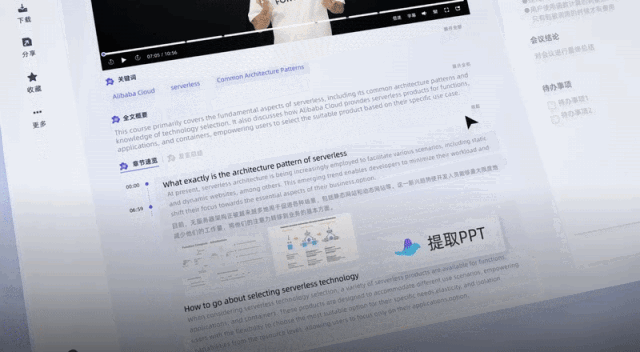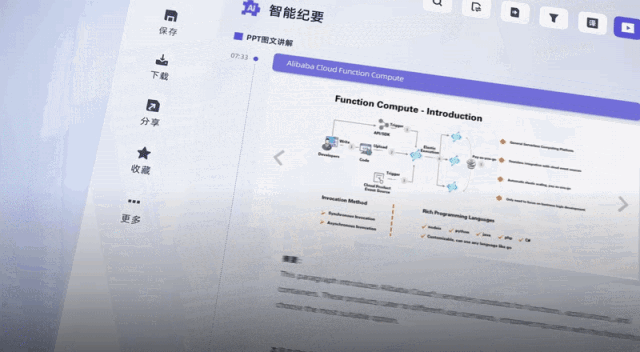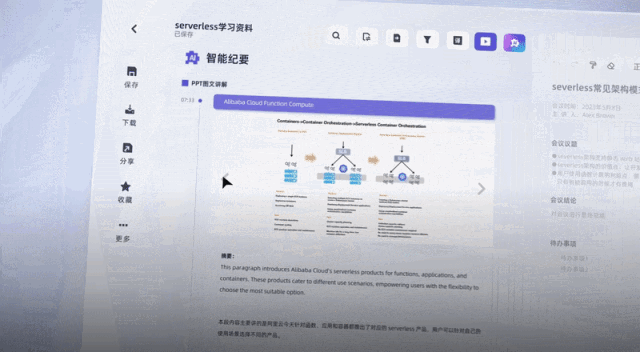
リスニング側では、文字起こし完了からAIがキーワードを抽出して全文要約を提供するまで、合計5分もかかりませんでした。
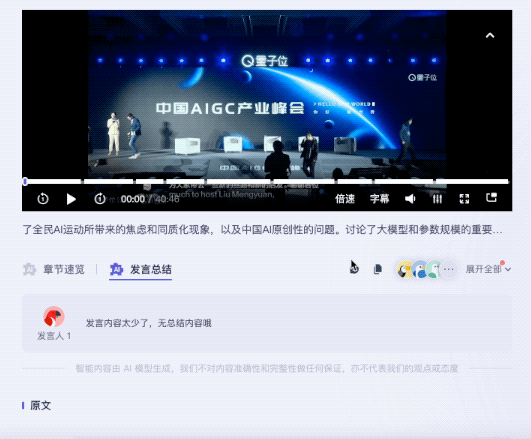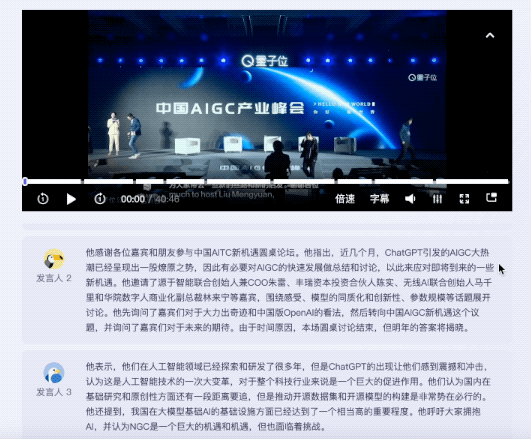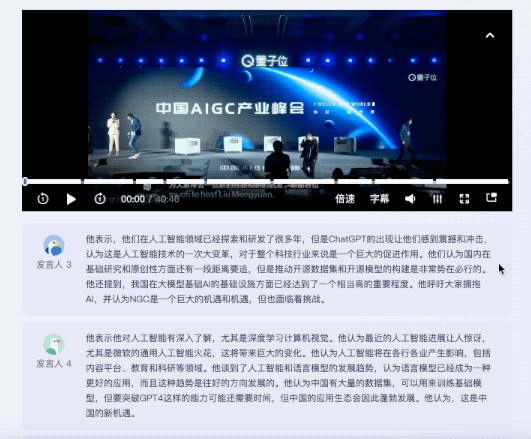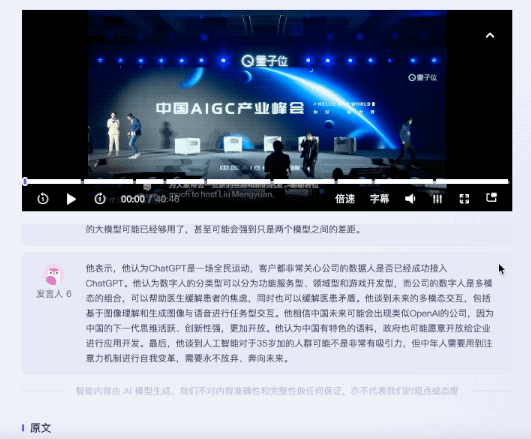
結果は江おばさんの:


キーワードを与えるだけでなく、ラウンドテーブルの内容も要約します。非常に正確で、ビデオの重要なポイントも分割しています。
人間の編集者が抜粋した論点を比較すると、危機の兆しを感じました...

特筆すべきは、さまざまなゲストのスピーチについてです。 , ウーの話を聞いて、対応するスピーチの要約を提供できます。
同じ質問がフェイシュ・ミアオジにも投げられました。現在、コンテンツの概要に関して、フェイシュ ミアオジはキーワードのみを提供できます。



しかし、この実際のテストで、Tongyi Tingwu について最も驚くべき点は、実際には「小さな」設計です。
Chrome プラグイン機能です。
英語のビデオを見ている場合でも、ライブ放送を見ている場合でも、授業中の会議に参加している場合でも、リスニング プラグインをクリックすることで、音声とビデオのリアルタイムの書き起こしと翻訳を実現できます。
冒頭で紹介したように、低遅延、高速翻訳、二か国語比較機能を備えたリアルタイム字幕として利用できると同時に、録音と文字起こししたテキストをワンクリックで保存できます。今後の使用のために。
お母さんは、私が英語のビデオ教材を咀嚼できないことを心配する必要はもうありません。
さらに、大胆なアイデアがあります...
グループミーティングを行うときにリスニングをオンにすると、講師に突然チェックされる心配がなくなります。
現在、Tingwu は Alibaba Cloud Disk に接続されており、クラウド ディスクに保存されている音声およびビデオ コンテンツをワンクリックで文字起こしでき、クラウド ディスクのビデオをオンラインで再生すると字幕が自動的に表示されます。将来的には、AI 処理されたオーディオ ファイルとビデオ ファイルをエンタープライズ バージョンで社内で迅速に共有できるようになります。

Tingwu 関係者は、Tingwu が将来的に画像の直接抽出などの新しい大規模モデル機能を追加し続けることも明らかにしました。ビデオから。PPT スクリーンショットを使用すると、オーディオおよびビデオ コンテンツについて AI に直接質問できます...



さらに、Wu の研究開発チームは、中国の超大規模文書会話データセット Doc2Bot もリリースしました。モデルの質問応答機能を向上させるチームの Re3G メソッドが ICASSP 2023 に選択されました。このメソッドは、Retrieve (取得)、Rerank (再ランキング)、Refine (微調整)、Generate (その理解、知識の検索、および応答生成の機能は、Doc2Dial と Multi Doc2Dial の 2 つの主要なドキュメント ダイアログ リストで 1 位にランクされています。
Tingwu は、大規模モデルの機能に加えて、アリババの音声テクノロジーの達人でもあります。
その背後にある音声認識モデル Paraformer は Alibaba Damo Academy から提供されており、産業レベルのアプリケーション レベルでエンドツーエンドの認識効果と効率のバランスをとるという問題を初めて解決します:
推論効率が向上するだけでなく、パフォーマンスの点で従来のモデルよりも 10 倍優れており、また、最初の発売時に多くの信頼できるデータセットの記録を破り、音声認識の SOTA 精度を更新しました。専門的なサードパーティのフルネットワーク パブリック クラウドの中国語音声認識評価 SpeechIO TIOBE ホワイト ボックス テストでは、Paraformer-large が依然として最高の精度を備えた中国語音声認識モデルです。
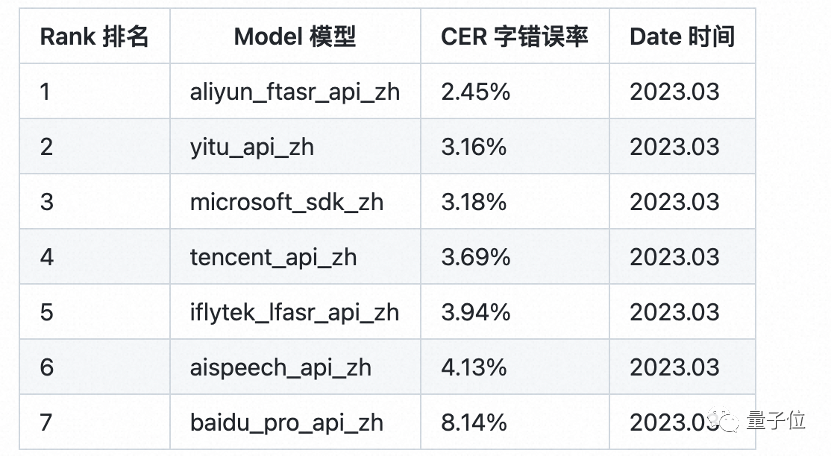
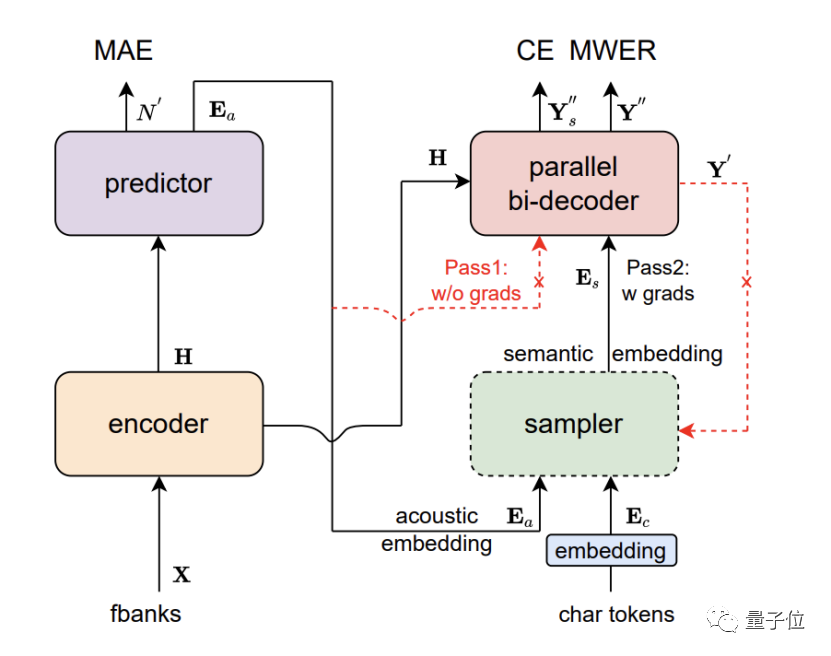
Paraformer は、エンコーダー、予測子、サンプラー、デコーダー、損失関数の 5 つの部分で構成されるシングルラウンドの非自己回帰モデルです。
Paraformer は、予測子の革新的な設計により、ターゲット単語の数と対応する音響潜在変数の正確な予測を実現します。
さらに、研究者らは機械翻訳の分野にブラウジング言語モデル (GLM) のアイデアを導入し、GLM に基づいてサンプラーを設計し、文脈セマンティクスのモデルのモデリングを強化しました。
同時に、Paraformer は豊富なシナリオをカバーする超大規模産業データセットで数万時間のトレーニングを行い、認識精度をさらに向上させました。
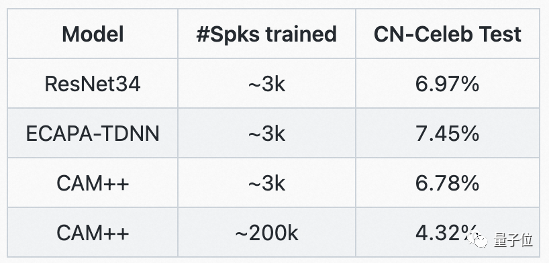
複数人でのディスカッションにおける発言者の正確な識別には、DAMO アカデミーの CAM 発言者認識基本モデルの恩恵を受けます。このモデルは、密な接続に基づく遅延ネットワーク D-TDNN を使用します。各層の入力は、前のすべての層の出力から接続されます。この階層的な機能の多重化と遅延ネットワークの 1 次元畳み込みにより、遅延ネットワークの計算効率が大幅に向上します。ネットワーク。
業界の主流である中国語と英語のテスト セット VoxCeleb および CN-Celeb で、CAM は最高の精度を更新しました。
大規模なモデルの開始、ユーザーの利益
中国科学技術情報研究院の報告書によると、未完統計によると、現在国内で発売されている大型モデルは79モデル。
この大規模モデル開発の流れのもと、AIアプリケーションの進化のスピードは再びスプリント段階に入りました。
ユーザーの視点から見ると、歓迎すべき状況が徐々に形になりつつあります。
大規模モデルの「連携」のもと、アプリケーション側でもさまざまなAI技術が開花し、ツールがより便利になり、より人気があり、より効率的かつスマートになります。
スラッシュを使用して作業計画を自動的に作成できるスマート ドキュメントから、要素をすばやく要約するのに役立つ音声およびビデオの記録および分析ツールまで、AGI の火花である生成大規模モデルは、より多くの機能を実現し、より多くの人 AI の魔法を感じる人が増えています。
同時に、テクノロジー企業にとっては、間違いなく新たな課題と新たな機会が生じています。
あらゆる製品が大型モデルの嵐にさらされるという課題があり、技術革新は避けて通れない重要な課題となっています。
既存の市場構造は、新たなキラーアプリケーションのために書き換えられるチャンスの瞬間に達しました。誰が主導権を握ることができるかは、誰がより技術的に準備ができているか、誰のテクノロジーがより速く進化するかによって決まります。
何があっても、技術開発は最終的にはユーザーに利益をもたらします。
以上がAlibaba Cloudの新大型モデルが登場! AIアーティファクト「Tongyi Listening」がパブリックベータ中:長い動画も1秒に要約可能、自動メモ取りや字幕変換も可能|羊毛も収穫可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。