
ホームページ >データベース >mysql チュートリアル >MySQL クエリのパフォーマンスを最適化するためのインデックス ダイビング インスタンス分析
MySQL クエリのパフォーマンスを最適化するためのインデックス ダイビング インスタンス分析

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-03 12:09:25930ブラウズ
奇妙なことから始めましょう:
問題を再現するためのデータを作成し、ユーザー テーブルを作成しましょう:
CREATE TABLE `user` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID', `name` varchar(100) NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NOT NULL DEFAULT 0 COMMENT '年龄', PRIMARY KEY (`id`), KEY `idx_age` (`age`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
ユーザー年齢のバッチを通じて、この年齢のユーザー情報をクエリし、SQL 実行計画を確認します。
explain select * from user where age in (1,2,3,4,5,6,7,8,9);

ここで、9 は条件パラメータでは、実行計画内の推定スキャン行数 (279 行) に注目します。
ここでは問題ありません。推定は非常に正確です。実際には 279 行です。
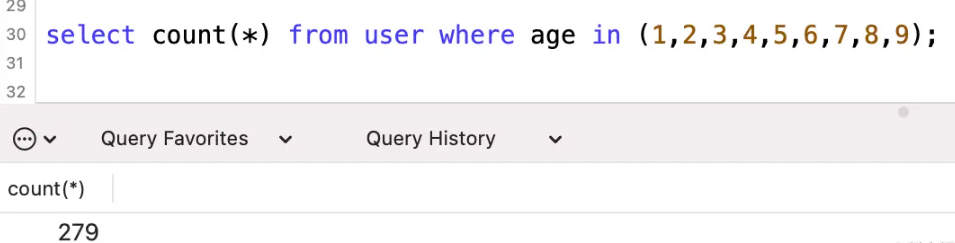
しかし、問題が発生します。where 条件にパラメータを追加すると、パラメータは 10 個になり、スキャンされる行の推定数は増加するはずです。結果は、大幅に削減されました。
explain select * from user where age in (1,2,3,4,5,6,7,8,9,10);

いきなり30行に減りましたが、実際の行数はどのくらいでしょうか?
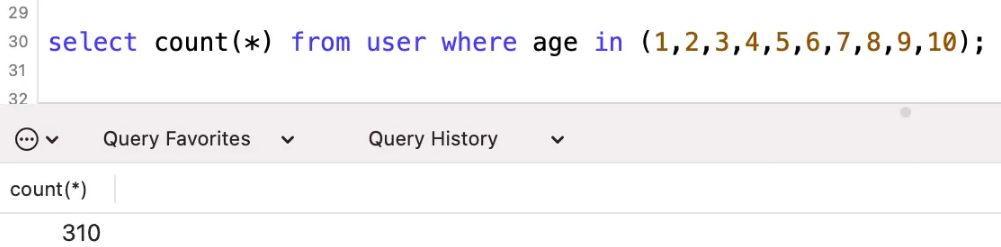
実数は 310 行、スキャンされる予定の行数は 30 行です。本当におばあちゃんの間違いです。
MySQL で何が起こっていますか? まだ推定できますか?
予測できない場合は、他の人を見つけてください。
公式 Web サイトにアクセスして Index dive という文字を目にするまで、誰もが混乱したはずです。
この単語に関連して、設定パラメータ eq_range_index_dive_limit もあります。
MySQL5.7.3以前のバージョンでは、この値はデフォルトで 10 に設定され、それ以降のバージョンでは、この値はデフォルトで 200 に設定されていました。
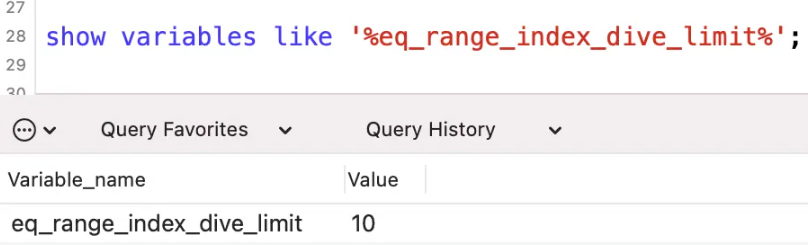
コマンドを使用して、この値のサイズを確認できます:
show variables like '%eq_range_index_dive_limit%';
もちろん、次のこともできます。この値を手動で変更します。 サイズ:
set eq_range_index_dive_limit=200;
この eq_range_index_dive_limit 構成の機能は次のとおりです:
条件内の where ステートメント内のパラメーターの数が以下の場合この値を使用すると、MySQL は Index dive メソッドを使用して、非常に正確なスキャン行数を推定します。
where ステートメントの in 条件内のパラメータの数がこの値以上の場合、MySQL は別の方法を使用します。 インデックス統計 (インデックス統計) スキャンされた行の推定数には大きな誤差があります。
MySQL がこのようなことを行うのはなぜですか?
みんな、Index dive(Index dive)を使って、スキャンした行数を見積もりますよね。
実際、これはコストを考慮したものです。インデックス ダイビング推定コストは比較的高く、少量のデータに適しています。 インデックス統計見積もりコストは低く、大量のデータに適しています。
通常の状況では、where ステートメントの in 条件にはそれほど多くのパラメーターが含まれていないため、スキャンされた行数を見積もるには index dive を使用するのが適切です。
以前のバージョンの MySQL5.7.3 をまだ使用している学生は、index dive 構成パラメータを適切な値に手動で変更することをお勧めします。
プロジェクトの in 条件に最大 500 個のパラメーターがある場合は、構成パラメーターを 501 に変更します。
このように、MySQL はスキャンされた行の数をより正確に推定し、より適切なインデックスを選択できます。
以上がMySQL クエリのパフォーマンスを最適化するためのインデックス ダイビング インスタンス分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。