
ホームページ >テクノロジー周辺機器 >AI >大きなモデルをカメラに組み込むにはどのような AI チップが必要ですか? Aixin Yuanzhi の答えは AX650N
大きなモデルをカメラに組み込むにはどのような AI チップが必要ですか? Aixin Yuanzhi の答えは AX650N

- 王林転載
- 2023-06-03 10:33:21947ブラウズ

Xinxixi (公開アカウント: aichip001)
作者 |
編集者それを書き換える 1 つの方法は次のとおりです。5 月 30 日のコア レポートによると、AI の大規模モデル競争が前例のないブームを引き起こしている、ChatGPT の台頭がこの競争の重要な原動力となっています。この競争では、モデルのトレーニングから実装まで、スピードが先行者利益を獲得するための鍵となります。より高性能な AI チップが急務となっています。
今年 3 月、AI 視覚認識チップの研究開発および基本的なコンピューティング プラットフォーム企業である Aixin Yuanzhi は、高いコンピューティング能力と高いエネルギー効率を備えた第 3 世代 SoC チップ AX650N を発売しました。 Aixin Yuanzhiの共同創設者兼副社長であるLiu Jianwei氏は、Xinxiおよびその他のメディアとの最近のインタビューで、AX650NチップはTransformerを実行する際に明らかな利点があり、Transformerは現在の大型モデルで一般的に使用されている構造であると述べました。
Transformer は当初、自然言語処理分野のタスクを処理するために使用されていましたが、徐々にコンピューター ビジョンの分野に拡張され、ますます多くの視覚タスクにおいて従来の主流のコンピューター ビジョン アルゴリズム CNN を置き換える可能性を示しました。 Transformer をデバイス側とエッジ側に効率的に導入する方法は、大規模なモデル導入のニーズを持つますます多くのユーザーにとって、プラットフォームを選択する際の中心的な考慮事項となっています。
GPU を使用して Transformer の大規模モデルをクラウドに展開するのと比較して、Aixin Yuanzhi は、Transformer をエッジ側とエンド側に展開する際の最大の課題は消費電力にあると考えています。これにより、Aixin Yuanzhi は高性能と低消費電力の混合精度を実現できます。消費 NPU は、エンド側とエッジ側に Transformer を導入するための推奨プラットフォームとなっています。
データによると、Aixin Yuanzhi AX650N プラットフォームで主流のビジュアル モデル Swin Transformer (SwinT) を実行すると、パフォーマンスは 361FPS と高く、精度は 80.45% と高く、消費電力は 199FPS/W と低いことがわかります。着陸展開において非常に競争力があります。
1. 高い演算能力と高いエネルギー効率を兼ね備え、さまざまな変圧器モデルに適応していますAX650N チップは、AX620 および AX630 シリーズの後に Aixin Yuanzhi によって発売されたもう 1 つの高性能インテリジェント ビジョン チップです。
この SoC はヘテロジニアス マルチコア設計を採用しており、8 コア A55 CPU、43.2TOPs@INT4 または 10.8TOPs@INT8 の高い演算能力 NPU、8K@30fps、H.264 および H をサポートする ISP を統合しています。 265 コーデック。インターフェイスに関しては、AX650N は 64 ビット LPDDR4x、複数の MIPI 入力、ギガビット イーサネット、USB および HDMI 2.0b 出力をサポートし、32 チャンネルの 1080p@30fps デコードをサポートします。
エッジ側とエンド側に大規模なモデルを導入する場合、AX650N には高性能、高精度、低消費電力、導入の容易さという利点があります。
具体的には、Aixin Yuanzhi AX650N が SwinT を実行する場合、361 フレームの高性能は、自動車自動運転分野のハイエンド GPU ベースのドメイン制御 SoC に匹敵し、80.45% という高精度は市場平均よりも高くなります。 199FPS/W の速度は、消費電力が低く、現在のハイエンド GPU ベースのドメイン コントロール SoC よりも数倍有利であることを反映しています。
Aixin Yuanzhi 氏は、初期のエッジサイドとエンドサイドの顧客は、何テラバイトのコンピューティング能力があるかにもっと注目していましたが、これは間接的なデータであり、ユーザーが最終的に気にしているのは、モデルが実際のビジネスでどれだけ高速に実行できるかであると説明しました。導入コストと使用コストがどの程度低いかについても説明します。
 この点で、AX650N は低ビット混合精度をサポートしており、ユーザーが INT4 を採用すると、メモリと帯域幅の使用量が大幅に削減され、エンドサイドとエッジサイドの導入コストを効果的に制御できます。
この点で、AX650N は低ビット混合精度をサポートしており、ユーザーが INT4 を採用すると、メモリと帯域幅の使用量が大幅に削減され、エンドサイドとエッジサイドの導入コストを効果的に制御できます。
現在、AX650N は ViT/DeiT、Swin/SwinV2、DETR などの Transformer モデルに適応されており、DINOv2 で 30 フレームを超えて実行することもできるため、検出、分類、セグメンテーション、その他の操作がユーザーにとってより便利になります。 AX650N ベースの製品は、スマート シティ、スマート教育、インテリジェント製造などの重要なコンピューター ビジョン シナリオにすでに適用されています。
2. 大規模なモデルのデプロイが簡単で、GitHub オリジナルのモデルを実行できます
Aixin Yuanzhi は、新世代の AI ツール チェーン Pulsar2 も作成しました。このツール チェーンには、モデル変換、オフライン定量化、モデル コンパイル、異種スケジューリングの 4 つを 1 つにまとめた機能が含まれており、NPU アーキテクチャを徹底的に最適化すると同時に、オペレーターとモデルのサポートも拡張します。 . 機能と範囲、および Transformer 構造ネットワークのサポート。
Aixin Yuanzhi 氏は、SwinT を実行できるチップを市場に出す企業は、通常、モデルに何らかの変更を加える必要があることを実際に発見しました。その変更により、一連の問題が発生し、ユーザーにさらなる不便をもたらす可能性があります。
以前は、GPU が MHA 構造計算のサポートに適しているため、SwinT に似たビジュアル Transformer モデルのほとんどがクラウド サーバーにデプロイされていました。その反対に、エッジ側/デバイス側の AI チップは CNN 構造モデルが確実にサポートされるようにする必要がありました。アーキテクチャ上の制限により、基本的にパフォーマンスの最適化はあまり行われておらず、やむなく展開する前にネットワーク構造を変更する必要さえあります。
AX650N は導入が簡単です。 GitHub 上の Aixin Yuanzhi プラットフォーム上の元のモデルを、変更したり QAT を再トレーニングしたりすることなく、効率的に実行できます。
「当社のユーザーは、当社のプラットフォームが現時点で Transformer をサポートするのに最適なプラットフォームであると報告しています。また、当社のプラットフォームに大規模なモデルを実装する可能性も考えています。顧客は AX650N を AI の最終実装として評価できると述べています。」コンピューティング パワー プラットフォームはより実用的で、使いやすく、シナリオへの適応性が高く、開始までの時間が短縮されるため、ユーザーの効率が大幅に向上し、量産サイクルが短縮されます。
Aixin Yuanzhi が収集した顧客のフィードバックによると、Aixin Yuanzhi の開発ボードとドキュメントを入手した後、デモの再現を完了してプライベート ネットワーク モデルを実行するまでに基本的に 1 時間かかることがわかります。
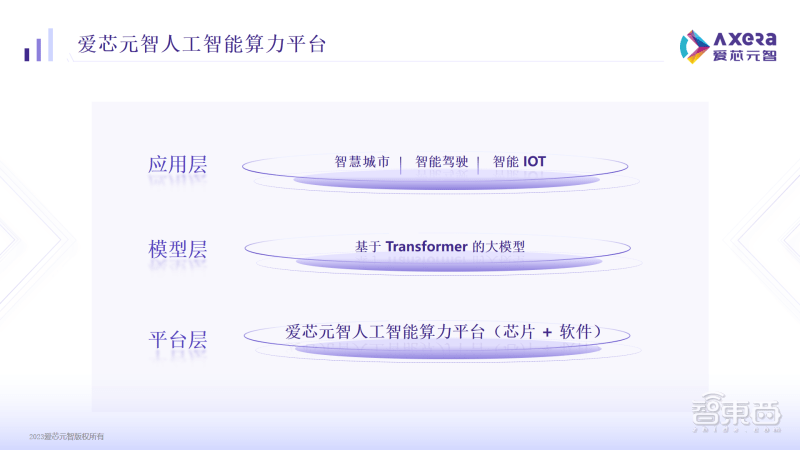
AX650N チップは、ハードウェアおよびソフトウェア設計におけるある程度の柔軟性とプログラマビリティの維持のおかげで、新たなネットワーク構造に迅速に適応できます。次に、Aixin Yuanzhi AX650N はトランス構造の最適化を継続し、マルチモーダル大型モデルなどのより大型のトランス モデルを検討します。
Aixin Yuanzhi は、AX650N ベースの AXera-Pi Pro 開発ボードも発売し、開発者がより豊富な製品アプリケーションを迅速に探索できるように、より多くの情報と AI サンプルを GitHub に掲載します。
3. ビジュアル アプリケーション シナリオでは、Transformer モデルの緊急のニーズが生じています
Aixin Yuanzhi 氏の見解では、大規模なビジュアル モデルをエッジ側または端末側にデプロイすることで、ロングテール シナリオにおける AI インテリジェント アプリケーションへの投資が高すぎる問題の解決に役立つ可能性があります。これまでの河川ゴミモニタリングの手法では、河川でゴミを発見した後、まずデータ収集とラベル付けが必要となり、その後モデルトレーニングが行われました。これまでデータ アノテーションやトレーニングされたモデルでカバーされていなかった河道に新しいゴミが出現した場合、モデルはそれを識別できない可能性があります。ゼロから再トレーニングするには時間と労力がかかります。
Transformer の大規模モデルは、セマンティック理解機能を備えており、従来の CNN モデルよりも汎用性があり、複雑な視覚的シーンをすべて事前に知らなくても、幅広い下流タスクを理解して実行できます。教師なしトレーニングによる事前トレーニング済みの大規模モデルを使用すると、これまでに見たことのない新しいガベージを識別できます。
Aixin Yuanzhi 氏は、現在、カメラを使用して画像をキャプチャするすべてのアプリケーション シナリオで、Transformer の大型モデルに対する緊急の需要が生じ始めていると述べました。具体的な実装速度は、各セグメントの顧客の研究開発とリソース投資に依存します。
チップ アーキテクチャ設計の観点から見ると、Transformer モデルをエッジまたはエンド側でより高速にデプロイできるようにするには、一方では大規模なモデルの帯域幅使用量を削減するように努める必要があり、他方では、次のことを行う必要があります。トランスの構造を最適化。 Aixin Yuanzhi の関連担当者は、AX650N の実際の展開で蓄積されたエンジニアリングの経験が次世代チップ プラットフォームに反復され、Transformer モデルがより高速かつより適切に実行できるようになり、従来の AX650N と比較して一定の先行者優位性が得られると述べました。他の仲間たち。
「これが、Aixin のチップ プラットフォームが Transformer の実装に最適な選択肢である理由です。誰もがモデルを小さくするとき、エンド側での実行の効果を確認したいと考えているはずです。当社には、そのようなことができるプラットフォームがあります。」閉ループ実験だ」と彼は語った。
Transformer の推論効果をさらに最適化するために、Aixin Yuanzhi は、ハードウェアが離散データを効率的に読み取る方法と、データの読み取りに一致するサポート計算を可能にする方法に焦点を当てます。さらに、Aixin Yuanzhi は、大規模なモデル パラメーターの問題を解決するために 4 ビットを使用しようとしているほか、一部のスパースまたは混合エキスパート システム (MOE、Mixture of Experts) モデルのサポートを検討しています。
結論: 高性能 AI チップが大規模モデル展開の基礎を形成します
2020年の最初の高性能AIビジョンチップAX630Aの量産から、2021年の第2世代自社開発エッジサイドスマートチップAX620A、そして新たにリリースされた第3世代AX650Nチップに至るまで、Aixin Yuanzhiは継続的に生産を行ってきました。コンピューティング能力と高いエネルギー効率比を備えたハイエンド AI ビジョン チップを発売し、エンド側とエッジ側の両方で AI アプリケーションのニーズを満たします。Aixin Yuanzhi の創設者兼会長兼 CEO である Qiu Xiaoxin 博士は、人工知能技術の発展は、これまでのテクノロジーの波により、視覚処理や自動車エレクトロニクスなどのチップ技術の開発を促進してきたと述べました。進歩、最近の大型モデルの爆発的な増加により、ここ数年でアイシンのエンドサイドとエッジサイドの継続的な探求に新たな機会が生まれました。
Aixin の関連する研究開発と実装計画はすべて 1 つの目標を目指しています。つまり、ユーザーまたは潜在的なユーザーが Transformer について考えるとき、Aixin Yuanzhi を思い浮かべ、さらに Aixin Yuanzhi の AI コンピューティング プラットフォームで Transformer ベースのモデルをさらに開発できるということです。最終的には、エンド側とエッジ側での大規模モデルとインテリジェント アプリケーションの実装が加速されます。
さらに、より多くの導入経験を蓄積することで、より高性能で使いやすいツールを提供することで、Aixin Yuanzhi のチップとソフトウェアの継続的な進化も促進され、アルゴリズム エンジニアが Transformer モデルの革新的なアプリケーションをさらに推進できるようになります。想像力への扉。
以上が大きなモデルをカメラに組み込むにはどのような AI チップが必要ですか? Aixin Yuanzhi の答えは AX650Nの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。