
Gaussian Redis を使用してセカンダリ インデックスを実装する方法

- PHPz転載
- 2023-06-02 18:53:231150ブラウズ
1. 背景
インデックス作成というとデータベースという名詞が第一印象ですが、Gaussian Redis はセカンダリ インデックス作成も実装できます。 ! ! Gaussian Redis のセカンダリ インデックスは通常、zset を使用して実装されます。 Gaussian Redis は、オープンソース Redis よりも高い安定性とコスト上の利点を備えており、Gaussian Redis zset を使用してビジネス セカンダリ インデックスを実装すると、パフォーマンスとコストの面で Win-Win の状況を実現できます。
インデックス作成の本質は、順序付けされた構造を使用してクエリを高速化することです。したがって、数値型および文字型のインデックスは、Zset 構造の Gaussian Redis を通じて簡単に実装できます。
• 数値型インデックス (zset は分数でソートされます):
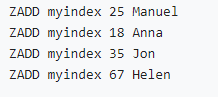

• 文字型インデックス (分数)はソートされます。同時に、zset は辞書順にソートされます):


2 種類の古典的なビジネス シナリオに分けて、その方法を見てみましょう。 Gaussian Redis を使用して、安定した信頼性の高いセカンダリ インデックス システムを構築します。
2. シナリオ 1: 辞書の補完
ブラウザにクエリを入力するとき、ブラウザは通常、可能性に基づいて同じプレフィックスを持つ検索を推奨します。このシナリオでは、Gaussian Redis 2 を使用できます。レベルインデックス機能を実装しました。

2.1 基本的な解決策
最も簡単な方法は、ユーザーの各クエリをインデックスに追加することです。ユーザーに完了プロンプトを提供する必要がある場合は、ZRANGEBYLEX を使用して範囲クエリを実行できます。結果の数を減らすには、LIMIT オプションを使用することが Gaussian Redis でサポートされている方法です。
• ユーザー検索バナナをインデックスに追加します:
ZADD myindex 0 banana:1
• ユーザーが検索フォームに「bit」と入力し、「bit」で始まる検索キーワードを提供したいとします。 「。」
ZRANGEBYLEX myindex "[bit" "[bit\xff"
ZRANGEBYLEX を使用して範囲クエリを実行する場合でも、クエリ範囲はユーザーが現在入力している文字列と、同じ文字列に末尾の 255 バイト (\xff) を加えたものになります。このメソッドを使用すると、ユーザーが入力した文字列が先頭に付くすべての文字列を取得できます。
2.2 頻度に関連した辞書補完
実際のアプリケーションでは、通常、出現頻度に適応して補完エントリを自動的にソートし、人気のなくなったエントリを削除したいと考えます。今後のインプット。この目標を達成するために、引き続き Gaussian Redis の ZSet 構造を使用できますが、インデックス構造では、検索語を保存するだけでなく、それらに関連付けられた頻度も保存する必要があります。
• ユーザー検索バナナをインデックスに追加します
• バナナが存在するかどうかを確認します
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
• バナナが存在しないと仮定して、banana:1 を追加します (1 は )周波数
ZADD myindex 0 banana:1
• バナナが存在すると仮定すると、周波数をインクリメントする必要があります
ZRANGEBYLEX myindex "[banana:" LIMIT 0 1 で返された周波数が 1
の場合1) 古いエントリを削除します:
ZREM myindex 0 banana:1
2) 再参加する頻度に 1 を加えます:
ZADD myindex 0 banana:2
同時更新が行われる可能性があるため、上記の 3 つのコマンドは Lua スクリプトを通じて送信する必要があることに注意してください。 Lua スクリプトを使用して古いカウントを自動的に取得し、スコアを増やした後にエントリを再追加します。
ユーザーが検索フォームに「バナナ」と入力すると、関連する検索キーワードが提供されると考えられます。 ZRANGEBYLEX で結果を取得した後、頻度で並べ替えます。
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 10 1) "banana:123" 2) "banaooo:1" 3) "banned user:49" 4) "banning:89"
• ストリーミング アルゴリズムを使用して、使用頻度の低い入力を消去します。返されたエントリをランダムに選択し、そのスコアから 1 を減算し、更新されたスコアで加算し直します。ただし、新しいスコアが 0 の場合は、リストからエントリを削除する必要があります。
• ランダムに選択されたエントリの頻度が 1 の場合 (bananaoo:1
ZREM myindex 0 banaooo:1
• ランダムに選択されたエントリの頻度が 1 より大きい場合 (banana:123# など) ##
ZREM myindex 0 banana:123 ZADD myindex 0 banana:122長期的には、インデックスには人気の検索が含まれ、時間の経過とともに人気の検索が変化した場合は自動的に適応されます。 3. シナリオ 2: 多次元インデックスGaussian Redis は、単一次元でのクエリをサポートするだけでなく、多次元データでの取得も可能です。たとえば、年齢が 50 ~ 55 歳、給与が 70,000 ~ 85,000 の条件を満たす人を検索します。 2 次元データ エンコーディングを 1 次元データに変換し、ガウス分散型 Redis zset ストレージを使用することは、多次元セカンダリ インデックスを実装するための重要な方法です。 2 次元のインデックスを視覚的な観点から表現します。この空間には、座標 (x, y) で表されるデータ サンプル点がいくつかあり、これらの座標における x 変数と y 変数の最大値は 400 です。画像内の青いボックスはクエリを表します。座標 x が 50 ~ 100、y が 100 ~ 300 であるすべての点を検索したいと考えています。

2)交织数字,以x表示最左边的数字,以y表示最左边的数字,依此类推,以便创建一个编码
027050
若使用00和99替换最后两位,即027000 to 027099,map回x和y,即:
x = 70-79
y = 200-209
因此,针对x=70-79和y = 200-209的二维查询,可以通过编码map成027000 to 027099的一维查询,这可以通过高斯Redis的Zset结构轻松实现。

同理,我们可以针对后四/六/etc位数字进行相同操作,从而获得更大范围。
3)使用二进制
如果将数据表示为二进制,就可以获得更细的粒度,而在数字替换时,每次都将搜索范围扩大两倍。如果我们使用二进制表示法数字,每个变量最多需要9位(表示最多400个值),那么我们将得到:
x = 75 -> 001001011
y = 200 -> 011001000
交织后,000111000011001010
让我们看看在交错表示中用0s ad 1s替换最后的2、4、6、8,...位时我们的范围是什么:

3.2 添加新元素
若插入数据点为x = 75和y = 200
x = 75和y = 200二进制交织编码后为000111000011001010,
ZADD myindex 0 000111000011001010
3.3 查询
查询:x介于50和100之间,y介于100和300之间的所有点
从索引中替换N位会给我们边长为2^(N/2)的搜索框。因此,我们要做的是检查搜索框较小的尺寸,并检查与该数字最接近的2的幂,并不断切分剩余空间,随后用ZRANGEBYLEX进行搜索。
下面是示例代码:
def spacequery(x0,y0,x1,y1,exp)
bits=exp*2
x_start = x0/(2**exp)
x_end = x1/(2**exp)
y_start = y0/(2**exp)
y_end = y1/(2**exp)
(x_start..x_end).each{|x|
(y_start..y_end).each{|y|
x_range_start = x*(2**exp)
x_range_end = x_range_start | ((2**exp)-1)
y_range_start = y*(2**exp)
y_range_end = y_range_start | ((2**exp)-1)
puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"
# Turn it into interleaved form for ZRANGEBYLEX query.
# We assume we need 9 bits for each integer, so the final
# interleaved representation will be 18 bits.
xbin = x_range_start.to_s(2).rjust(9,'0')
ybin = y_range_start.to_s(2).rjust(9,'0')
s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")
# Now that we have the start of the range, calculate the end
# by replacing the specified number of bits from 0 to 1.
e = s[0..-(bits+1)]+("1"*bits)
puts "ZRANGEBYLEX myindex [#{s} [#{e}"
}
}
end
spacequery(50,100,100,300,6)以上がGaussian Redis を使用してセカンダリ インデックスを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。