
ホームページ >データベース >mysql チュートリアル >mysql作成時にSpark SQLで更新操作をサポートする方法
mysql作成時にSpark SQLで更新操作をサポートする方法

- PHPz転載
- 2023-06-02 15:19:211929ブラウズ
追加、上書き、ErrorIfExists、Ignore のサポートに加えて、更新操作もサポートします
1. まず背景を理解します
Spark は、ドッキング データのソース操作をサポートする列挙クラスを提供します。モード
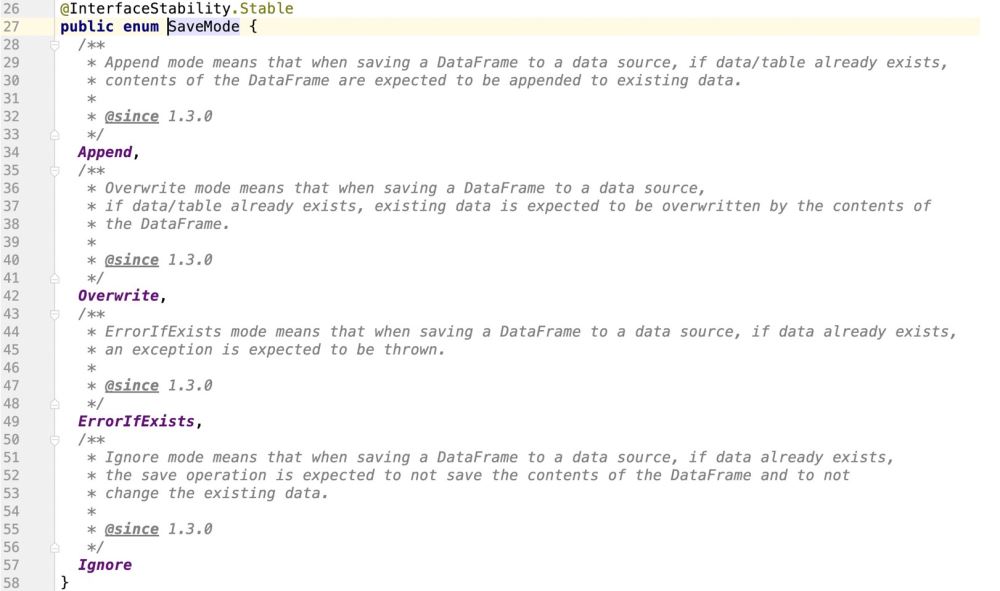
#2.SparkSQL で更新をサポートする方法
重要な知識ポイントは次のとおりです:
通常、sparkSQL で mysql にデータを書き込む場合:
おおよその API は次のとおりです:
dataframe.write
.format("sql.execution.customDatasource.jdbc")
.option("jdbc.driver", "com.mysql.jdbc.Driver")
.option("jdbc.url", "jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=true&characterEncoding=gbk&autoReconnect=true&failOverReadOnly=false")
.option("jdbc.db", "test")
.save()そして、最下層では、spark はJDBC 方言 JdbcDialect を通じて、挿入したいデータは次のように変換されます:
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
次に、方言を通じて解析された SQL ステートメントが PrepareStatement のexecuteBatch() を通じて mysql に送信され、データが挿入されます。
#上記の SQL ステートメントは明らかです。コードは完全に挿入されており、期待される更新操作はありません。次のようなものです:UPDATE table_name SET field1=new-value1, field2=new-value2しかし、mysql はこのような SQL ステートメントのみをサポートします:
INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';一般的な意味は、データが存在しない場合はデータを挿入し、データが存在する場合は更新操作を実行するということです。したがって、私たちの焦点は、次のような場合に Spark SQL がそのような SQL ステートメントを生成できるようにすることです。 JdbcDialect と内部的にドッキング
INSERT INTO 表名称 (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';3. ソース コードを変換する前に、全体的なコード設計と実行プロセスを理解する必要がありますまず第一に:
dataframe.write
書き込みメソッドクラスを返すために呼び出されます: DataFrameWriter主に、DataFrameWriter は外部データ ソースに接続するためのsparksql のクラスを運ぶエントリであるため、次のコンテンツは DataFrameWriter
に登録された情報を運びます。
次に、save() 操作を開始します。 その後、データの書き込みを開始します。 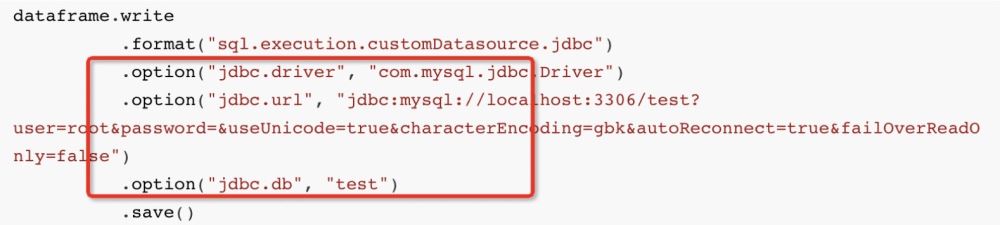
上記のソース コードでは、主に DataSource インスタンスを登録し、次に DataSource の write メソッドを使用してデータを書き込みます。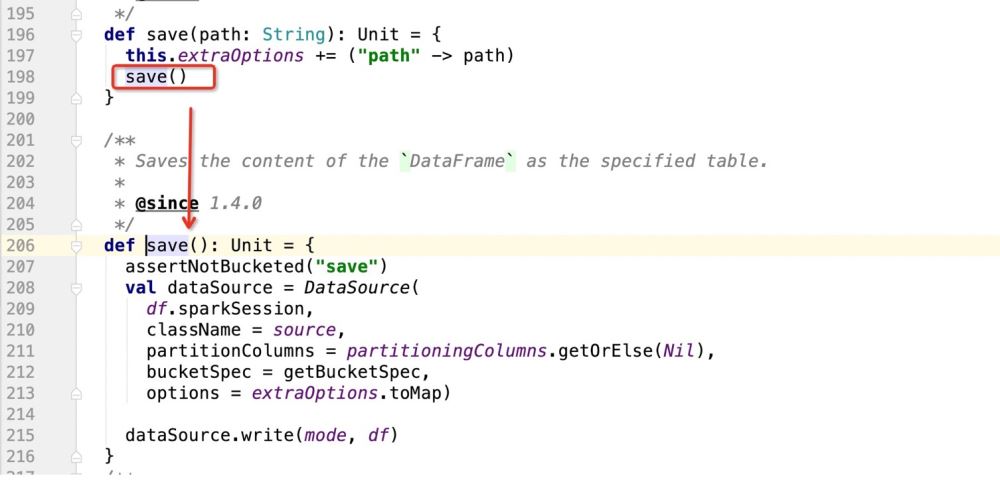
def save(): Unit = {
assertNotBucketed("save")
val dataSource = DataSource(
df.sparkSession,
className = source,//自定义数据源的包路径
partitionColumns = partitioningColumns.getOrElse(Nil),//分区字段
bucketSpec = getBucketSpec,//分桶(用于hive)
options = extraOptions.toMap)//传入的注册信息
//mode:插入数据方式SaveMode , df:要插入的数据
dataSource.write(mode, df)
}次に、 dataSource.write(mode, df) の詳細全体のロジックは次のとおりです:providingClass.newInstance() に基づいてパターン マッチングを実行し、一致する場所でコードを実行します。 ##次に、providingClass が何であるかを見てみましょう:
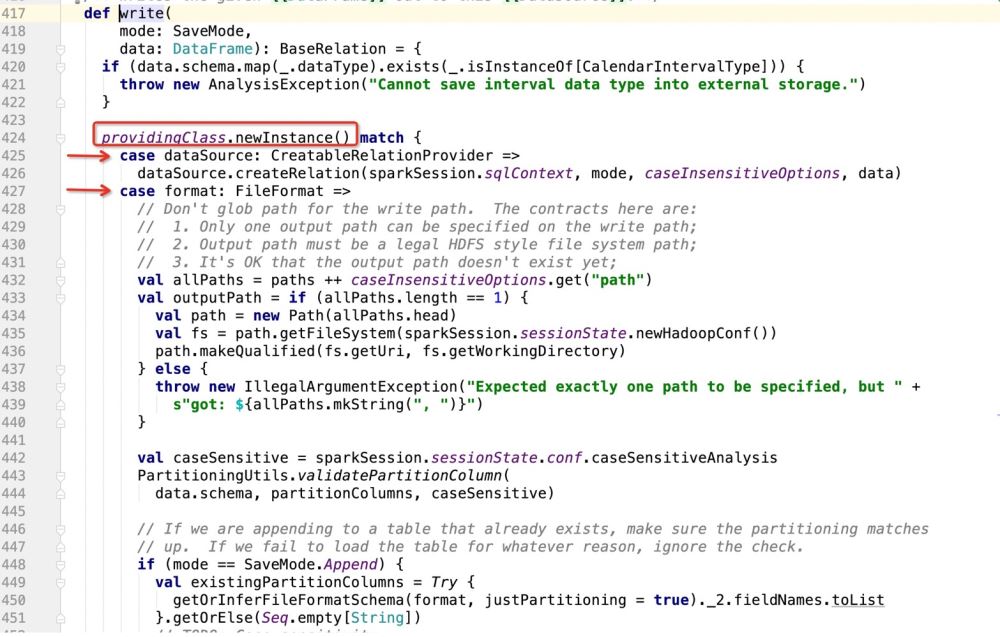
パッケージ path.DefaultSource を取得した後、プログラムは次のようになります。 : 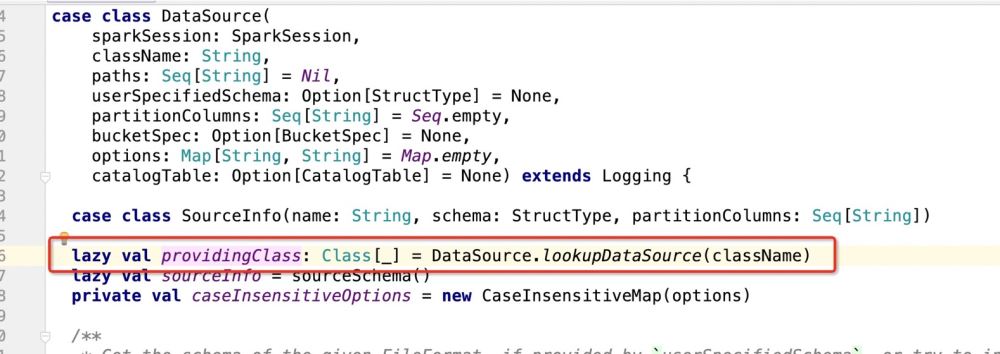
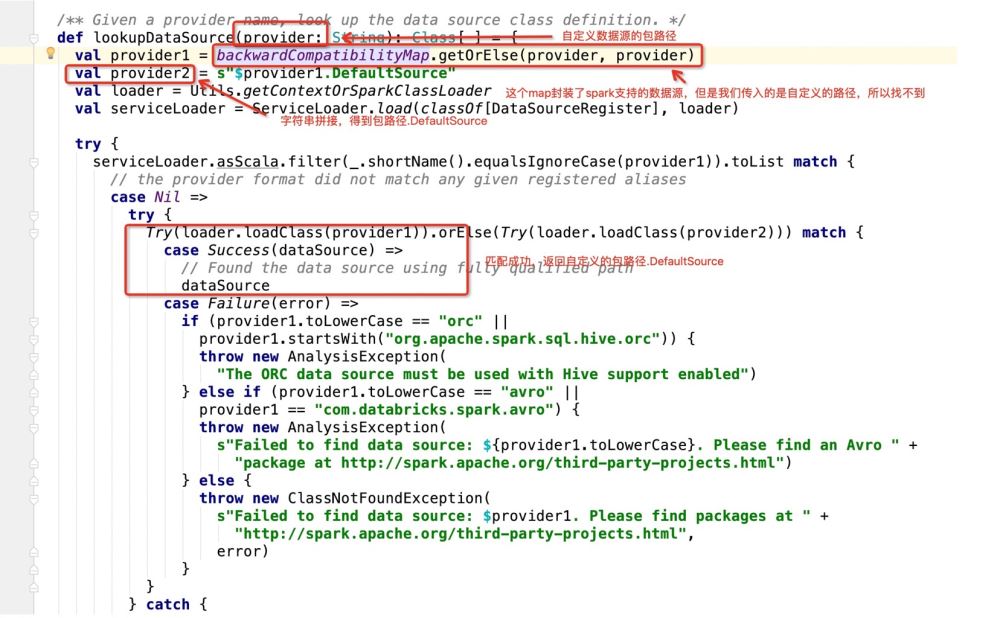
## に直接続きます。
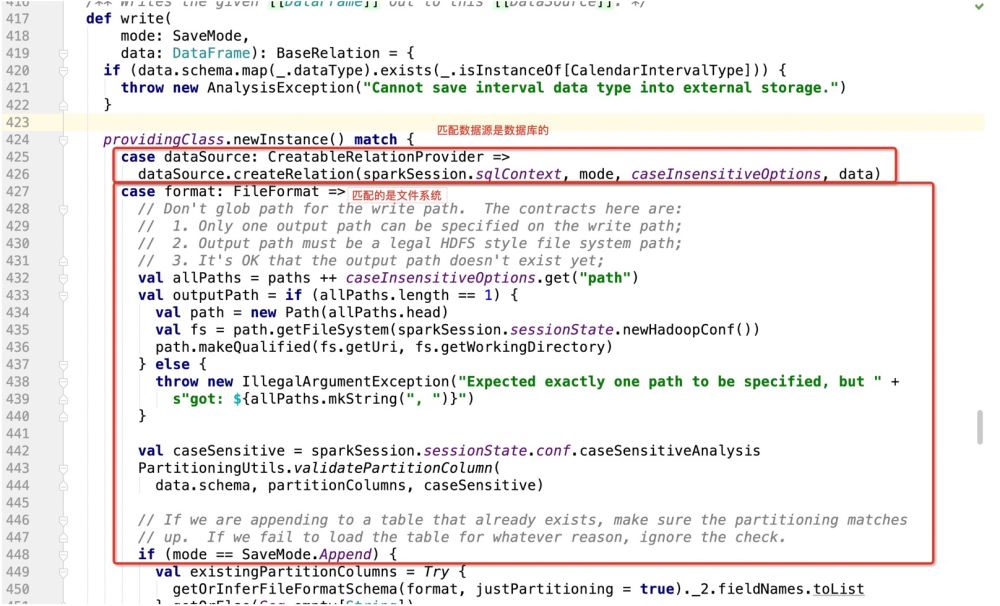 # は明らかに特性であるため、特性が実装される場所はどこでも、プログラムはどこに移動しますか?
# は明らかに特性であるため、特性が実装される場所はどこでも、プログラムはどこに移動しますか?
この機能を実装する場所は、パッケージ パス.DefaultSource です。次に、ここでデータ挿入と更新サポート操作を実装します;
4. ソース コードを変換します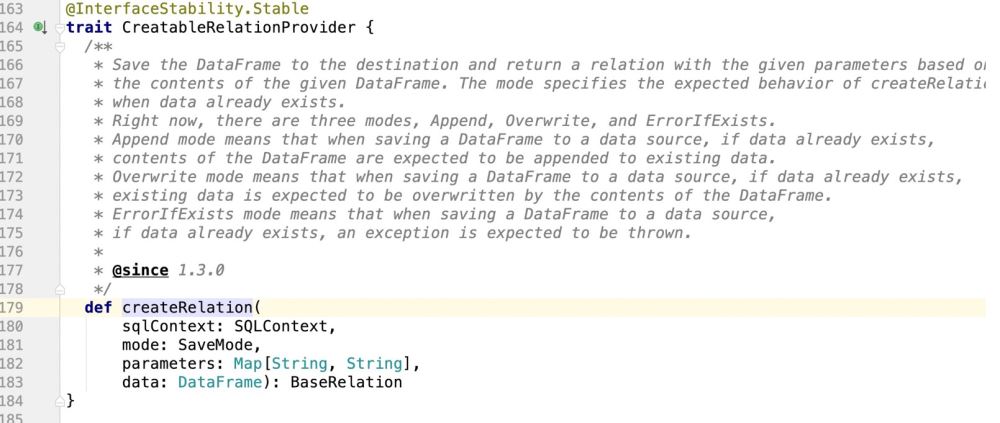
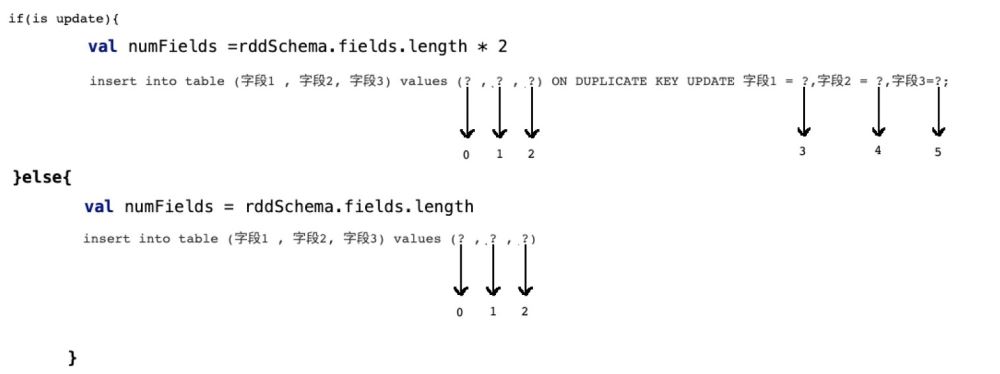
if(isUpdate){
sql语句:INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
}else{
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
}
ただし、Spark Production SQL ステートメントのソース コードでは、次のように書かれています:
判定ロジックはなく、最終的に判定ロジックが生成されるだけです:
INSERT INTO TABLE (字段1 , 字段2....) VALUES (? , ? ...)
したがって、最初のタスクは現在のコードをサポートする方法です: ON DUPLICATE KEY UPDATE
大胆な設計です。つまり、insertStatement メソッドで次の判断を行います。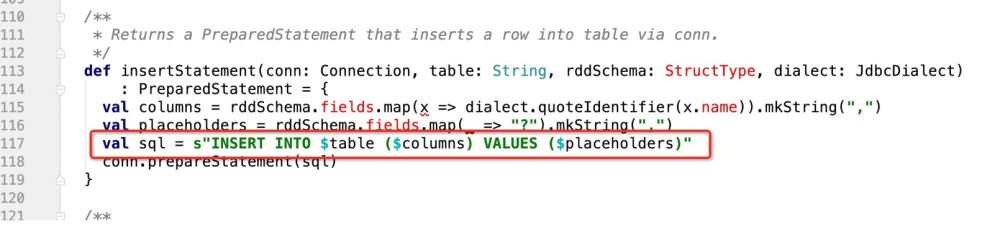
def insertStatement(conn: Connection, savemode:CustomSaveMode , table: String, rddSchema: StructType, dialect: JdbcDialect)
: PreparedStatement = {
val columns = rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",")
val placeholders = rddSchema.fields.map(_ => "?").mkString(",")
if(savemode == CustomSaveMode.update){
//TODO 如果是update,就组装成ON DUPLICATE KEY UPDATE的模式处理
s"INSERT INTO $table ($columns) VALUES ($placeholders) ON DUPLICATE KEY UPDATE $duplicateSetting"
}esle{
val sql = s"INSERT INTO $table ($columns) VALUES ($placeholders)"
conn.prepareStatement(sql)
}
}このようにして、ユーザーによって渡された savemode モードを検証します。更新操作の場合は、対応する SQL ステートメントが返されます。 ! したがって、上記のロジックに従って、コードは次のように記述されます:
このようにして、対応する SQL ステートメントを取得します。 #ただし、この SQL ステートメントだけはまだ機能しません。これは、jdbc prepareStatement 操作が Spark で実行され、カーソルが関与するためです。
つまり、jdbc がこの SQL を走査すると、ソース コードは次のようになります:
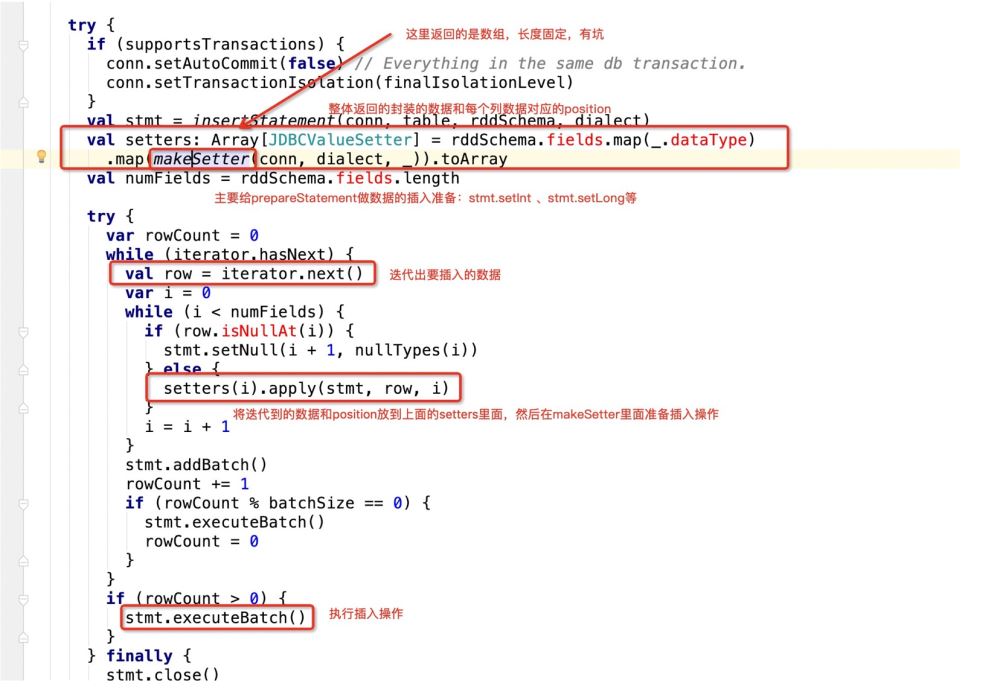
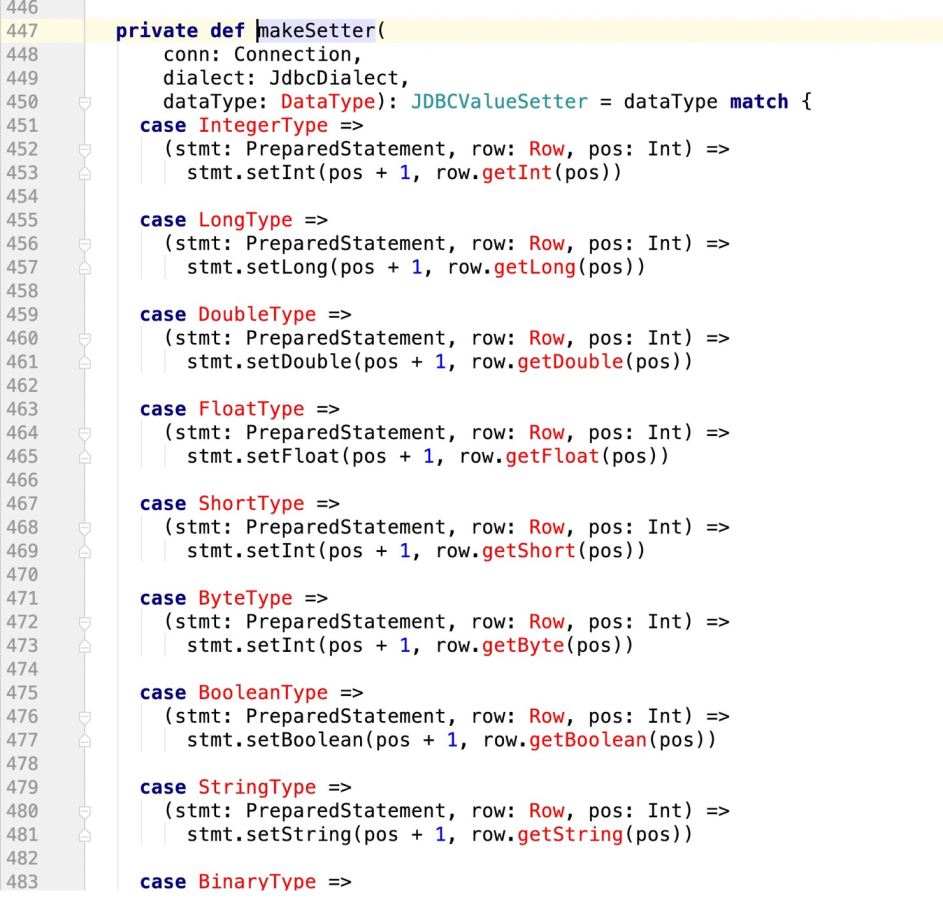
看下makeSetter:

所谓有坑就是:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?)
那么当前在源码中返回的数组长度应该是3:
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray但是如果我们此时支持了update操作,既:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?) ON DUPLICATE KEY UPDATE 字段1 = ?,字段2 = ?,字段3=?;
那么很明显,上面的sql语句提供了6个? , 但在规定字段长度的时候只有3
这样的话,后面的update操作就无法执行,程序报错!
所以我们需要有一个 识别机制,既:
if(isupdate){
val numFields = rddSchema.fields.length * 2
}else{
val numFields = rddSchema.fields.length
}
row[1,2,3] setter(0,1) //index of setter , index of row setter(1,2) setter(2,3) setter(3,1) setter(4,2) setter(5,3)
所以在prepareStatment中的占位符应该是row的两倍,而且应该是类似这样的一个逻辑
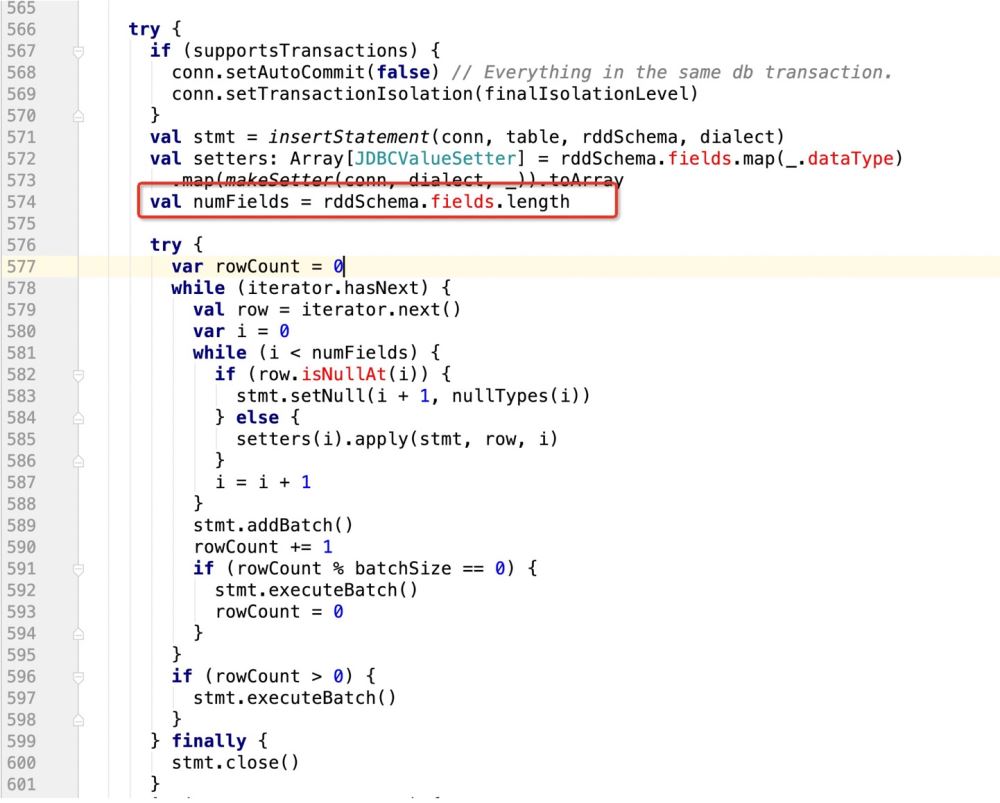
因此,代码改造前样子:
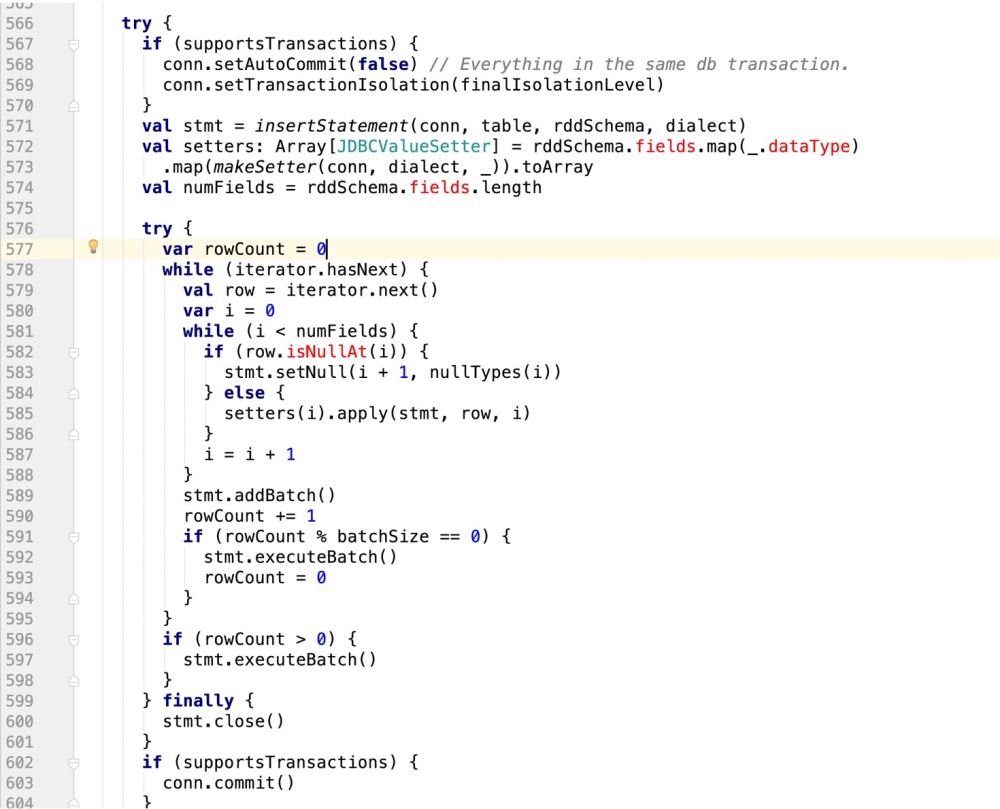
改造后的样子:
try {
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
// val stmt = insertStatement(conn, table, rddSchema, dialect)
//此处采用最新自己的sql语句,封装成prepareStatement
val stmt = conn.prepareStatement(sqlStmt)
println(sqlStmt)
/**
* 在mysql中有这样的操作:
* INSERT INTO user_admin_t (_id,password) VALUES ('1','第一次插入的密码')
* INSERT INTO user_admin_t (_id,password)VALUES ('1','第一次插入的密码') ON DUPLICATE KEY UPDATE _id = 'UpId',password = 'upPassword';
* 如果是下面的ON DUPLICATE KEY操作,那么在prepareStatement中的游标会扩增一倍
* 并且如果没有update操作,那么他的游标是从0开始计数的
* 如果是update操作,要算上之前的insert操作
* */
//makeSetter也要适配update操作,即游标问题
val isUpdate = saveMode == CustomSaveMode.Update
val setters: Array[JDBCValueSetter] = isUpdate match {
case true =>
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
Array.fill(2)(setters).flatten
case _ =>
rddSchema.fields.map(_.dataType)
val numFieldsLength = rddSchema.fields.length
val numFields = isUpdate match{
case true => numFieldsLength *2
case _ => numFieldsLength
val cursorBegin = numFields / 2
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if(isUpdate){
//需要判断当前游标是否走到了ON DUPLICATE KEY UPDATE
i < cursorBegin match{
//说明还没走到update阶段
case true =>
//row.isNullAt 判空,则设置空值
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
//说明走到了update阶段
case false =>
if (row.isNullAt(i - cursorBegin)) {
//pos - offset
stmt.setNull(i + 1, nullTypes(i - cursorBegin))
setters(i).apply(stmt, row, i, cursorBegin)
}
}else{
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i ,0)
}
//滚动游标
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
if (rowCount > 0) {
stmt.executeBatch()
} finally {
stmt.close()
conn.commit()
committed = true
Iterator.empty
} catch {
case e: SQLException =>
val cause = e.getNextException
if (cause != null && e.getCause != cause) {
if (e.getCause == null) {
e.initCause(cause)
} else {
e.addSuppressed(cause)
throw e
} finally {
if (!committed) {
// The stage must fail. We got here through an exception path, so
// let the exception through unless rollback() or close() want to
// tell the user about another problem.
if (supportsTransactions) {
conn.rollback()
conn.close()
} else {
// The stage must succeed. We cannot propagate any exception close() might throw.
try {
conn.close()
} catch {
case e: Exception => logWarning("Transaction succeeded, but closing failed", e)// A `JDBCValueSetter` is responsible for setting a value from `Row` into a field for
// `PreparedStatement`. The last argument `Int` means the index for the value to be set
// in the SQL statement and also used for the value in `Row`.
//PreparedStatement, Row, position , cursor
private type JDBCValueSetter = (PreparedStatement, Row, Int , Int) => Unit
private def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int,cursor:Int) =>
stmt.setInt(pos + 1, row.getInt(pos - cursor))
case LongType =>
stmt.setLong(pos + 1, row.getLong(pos - cursor))
case DoubleType =>
stmt.setDouble(pos + 1, row.getDouble(pos - cursor))
case FloatType =>
stmt.setFloat(pos + 1, row.getFloat(pos - cursor))
case ShortType =>
stmt.setInt(pos + 1, row.getShort(pos - cursor))
case ByteType =>
stmt.setInt(pos + 1, row.getByte(pos - cursor))
case BooleanType =>
stmt.setBoolean(pos + 1, row.getBoolean(pos - cursor))
case StringType =>
// println(row.getString(pos))
stmt.setString(pos + 1, row.getString(pos - cursor))
case BinaryType =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - cursor))
case TimestampType =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - cursor))
case DateType =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - cursor))
case t: DecimalType =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos - cursor))
case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase.split("\\(")(0)
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos - cursor).toArray)
stmt.setArray(pos + 1, array)
case _ =>
(_: PreparedStatement, _: Row, pos: Int,cursor:Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}以上がmysql作成時にSpark SQLで更新操作をサポートする方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。