
ホームページ >データベース >mysql チュートリアル >MySQL の最適化とインデックス作成の方法
MySQL の最適化とインデックス作成の方法

- PHPz転載
- 2023-06-02 13:58:211148ブラウズ
インデックスの簡単な紹介
インデックスの本質:
MySQL インデックスや他のリレーショナル データベースのインデックスの本質は次のとおりです。たった一文で、スペースを時間に置き換えます。
インデックスの役割:
インデックス リレーショナル データベースは、行データの取得を高速化するために使用されます。テーブル (ディスクストレージ) データ構造
インデックスの分類
データ構造上のカテゴリ:
- # #HASH インデックス
- 等しい値の一致は非常に効率的です
- 範囲検索はサポートされていません
- ツリー インデックス
- 二分木、再帰的二分探索法、左が小さく右が大きい
- バランス型バイナリツリー、バイナリ ツリーからバランスのとれたバイナリ ツリーへ。主な理由は左利きと右利きです。
- 欠点 1、IO 回数が多すぎます
- #欠点 2、IO 使用率が高くなく、IO 飽和
- マルチパス分散検索ツリー (B ツリー)
- ツリーの高さを大幅に削減する機能
- B ツリー
- 左の機能を使用した機能クローズド比較方式
- ルート ノード サポート ノードにはデータ領域がなく、リーフ ノードのみにデータ領域が含まれます (端的に言えば、ルート ノードと子ノードが存在していても)
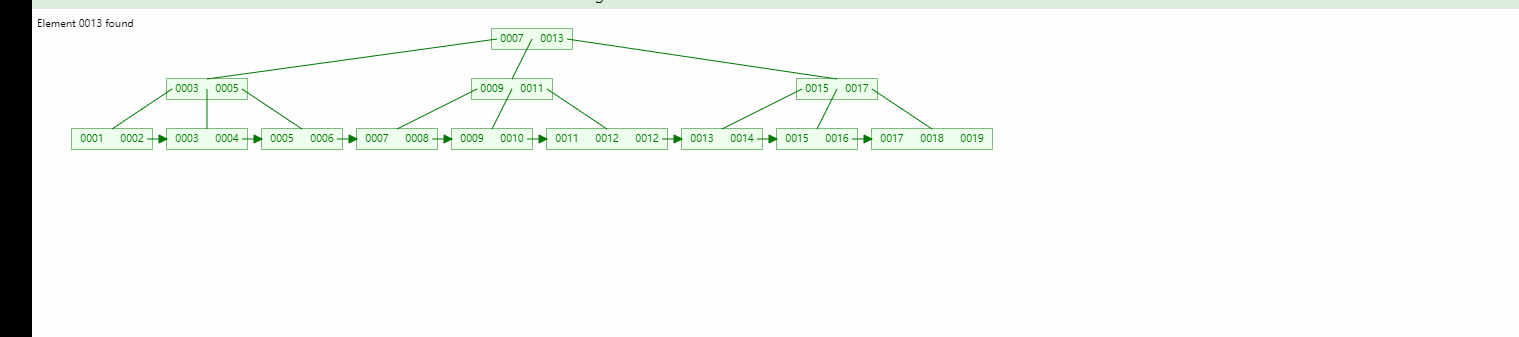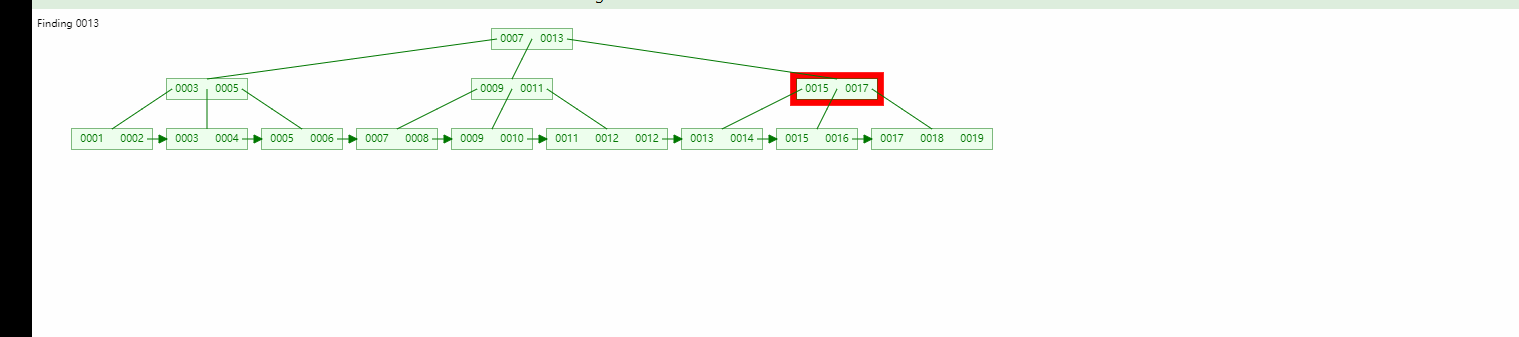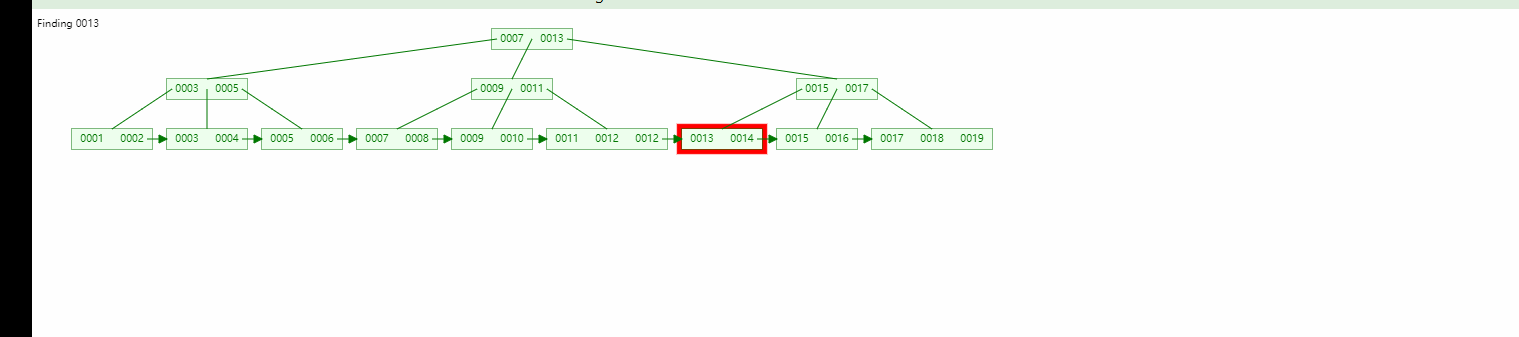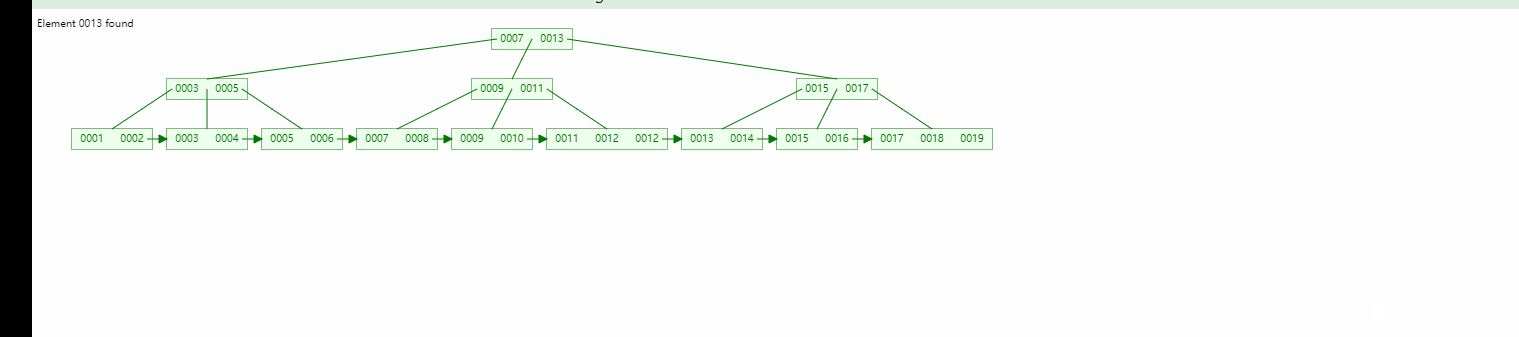
バイナリ ツリー バランス型バイナリ ツリー、B ツリーの比較:
画像は、次の場合の状況を示しています。これは自動増加する主キーです 次:
バイナリ ツリーは明らかにリレーショナル データベース インデックスには適していません (テーブル全体のスキャンと変わりません)。 バランスのとれたバイナリ ツリーに関しては、この状況は解決されますが、ツリーが細くて高くなってしまい、前述の IO クエリが多すぎて IO 使用率が低下する原因にもなります。 B-tree はこれら 2 つの問題を明らかに解決しています。したがって、MySQL がこの場合でも B-tree を使用し、これらの機能強化を行った理由を以下で説明します。


IO 効率が高くなります (B ツリーの各ノードはデータ領域を保持しますが、B ツリーは保持しません。データの一部をクエリするために 3 つのレイヤーをトラバースする必要がある場合、明らかに B ツリー クエリの IO 消費量は小さくなります)
範囲検索の効率が高くなります (図に示すように、B ツリーは自然なリンク リスト形式であり、最後のチェーン構造に従って検索するだけで済みます)
 インデックスベースのデータ スキャンの方が効率的です。
インデックスベースのデータ スキャンの方が効率的です。
インデックス タイプの分類
インデックス タイプは 2 つのカテゴリに分類できます:
- 主キー インデックス
- 複合インデックス
- 通常のインデックス
- カバード インデックス
- 一意のインデックス
B ツリーはストレージ エンジン レベルで実装されます
- 2 つのテーブルをそれぞれ作成します
- test_innodb
(InnoDB をストレージ エンジンとして使用) test_myisam (ストレージ エンジンとして MyISAM を使用) 次の図は、2 つのテーブル ディスク実装に関連するファイルを示しています。2 つのストレージ エンジンは、B ツリー ディスク実装では完全に異なります。
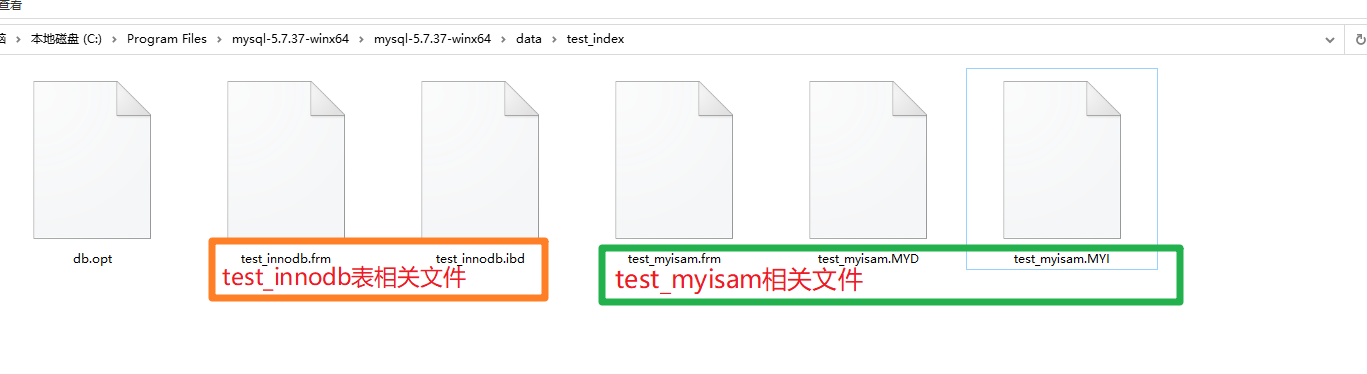
- .frm ファイルこのテーブルの ID フィールドや名前フィールドなどのテーブル スケルトン ファイルはここに保存されます *.MYD (D=data) はデータを保存します
-
##*.MYI (I=index) はインデックスを格納します

-
うわぁぁぁぁぁぁぁぁぁぁぁぁぁぁぁぁぁぁぁぁぁん
如果
test_myisam表中,id为主键索引,name也是一个索引,那么在test_myisam.MYI中则会有两个平级的B+树,这也导致MyISAM引擎中主键索引和二级索引是没有主次之分的,是平级关系。因为这种机制在MyISAM引擎中,有可能使用多个索引,在InnoDB中则不会出现这种情况。
B+树在InnoDB落地:

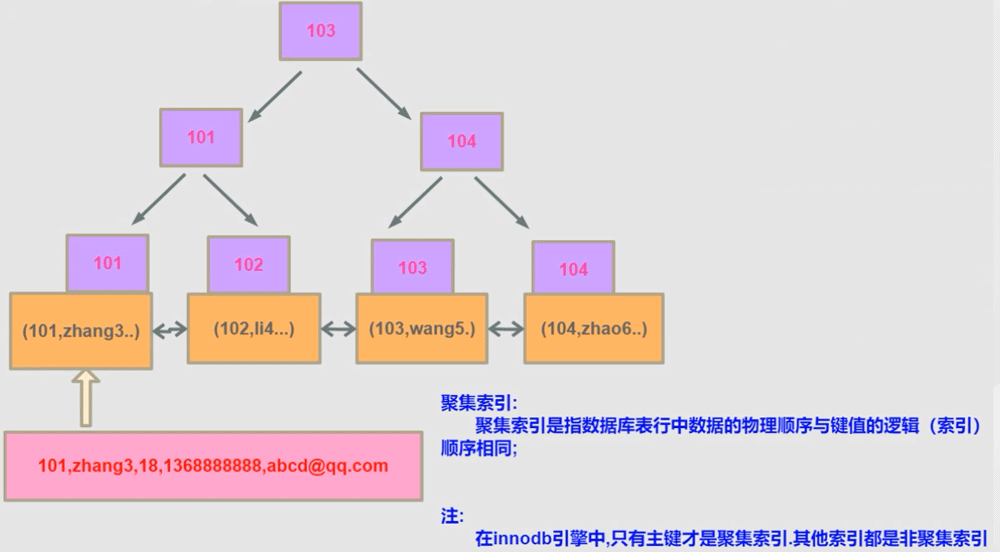
InnoDB不像MyISAM来独立一个MYD 文件来存储数据,它的数据直接存储在叶子结点关键字对应的数据区在这保存这一个id列所有行的详细记录。
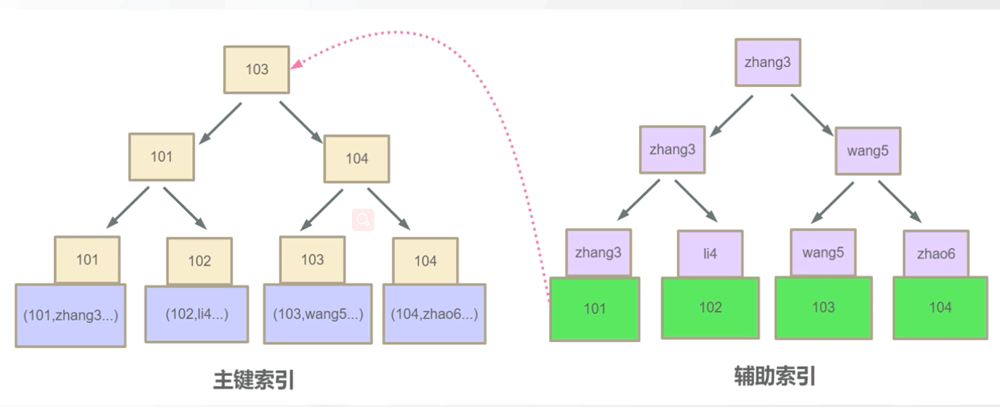
InnoDB 主键索引和辅助索引关系
我们现在执行如下SQL语句,他会先去找辅助索引,然后找到辅助索引下101的主键,再去回表(二次扫描)根据主键索引查询103这条数据将其返回。
SELECT id,name from test_myisam where name ='zhangsan'
这里就有一个问题了,为什么不像MyISAM在辅助索引下直接记录磁盘地址,而是要多此一举再去回表扫描主键索引,这个问题在下面相关面试题中回答,记一下这个问题是这里来的。
相关面试题
为什么MySQL选择B+树作为索引结构
这个就不说了,上文应该讲清楚了。
B+树在MyISAM和InnoDB落地区别。
这个可以总结一下,MyISAM落地数据储存会有三个类型文件 ,.frm文件是表骨架文件,.MYD(D=data)则储存数据 ,.MYI (I=index)则储存索引,MyISAM引擎中主键索引和二级索引平级关系,在MyISAM引擎中,有可能使用多个索引,InnoDB则相反,主键索引和二级索有严格的主次之分在InnoDB一条语句只能用一个索引要么不用。
如何判断一条sql语句是否使用了索引。
可以通过执行计划来判断 可以在sql语句前explain/ desc
set global optimizer_trace='enabled=on' 打开执行计划开关他将会把每一条查询sql执行计划记录在information_schema 库中OPTIMIZER_TRACE表中
为什么主键索引最好选择自增列?
自增列,数据插入时整个索引树是只有右边在增加的,相对来说索引树的变动更小。
为什么经常变动的列不建议使用索引?
和上一个问题原因一样,当一个索引经常发生变化,那么就意味这,这个缩印树也要经常发生变化。4
为什么说重复度高的列,不建议建立索引?
这个原因是因为离散性,比如说,一张一百万数据的表,其中一个字段代表性别,0代表男1代表女,把这字段加了索引,那么在索引树上,将会有大量的重复数据。而我们常见的索引建立一般都是驱动型的。其目的是,尽可能的删减数据的查询范围,这个显然是不匹配的。
什么是联合索引
联合索引是一个包含了多个功效的索引,他只是一个索引而不是多个,
其次,单列索引是一种特殊的联合索引
联合索引的创立要遵循最左前置原则(最常用列>离散度>占用空间小)
什么是覆盖索引
通过索引项信息可直接返回所需要查询的索引列,该索引被称之为覆盖索引,说白了就是不需要做回表操作,可以从二级索引中直接取到所需数据。
什么是ICP机制
索引下推,简单点来说就是,在sql执行过程中,面对where多条件过滤时,通过一个索引,完成数据搜索和过滤条件其,特点能减少io操作。
在InnoDB表中不可能没有主键对还是不对原因是什么?
首先这句话是对的,但是情况有三种:
つまり、このフィールドを主キーとして手動で指定すると、このフィールドはクラスター化インデックスとして使用されます。
主キーが明示的に指定されていない場合は、次の 2 つの状況が考えられます。
彼は、最初の UK (一意のキー) を検索します。主キーインデックス インデックス作成を整理します。
主キーも UK も指定されていない場合、rowId (InnoDB テーブルの各レコードには非表示 (6 バイト) rowId があります) がクラスター化インデックスとして使用されます。
- #テーブルリターン操作とは
InnoDB の補助インデックスに基づくクエリの内容、補助インデックスから直接取得することはできず、主キー インデックスに基づく二次スキャンが必要な操作はテーブル リターン操作と呼ばれます。
- InnoDB の補助インデックスのリーフ ノード データ領域は、MyISAM のようにディスク アドレスを記録するのではなく、主キー インデックスの値を記録するのはなぜですか。
理由は実は非常に単純で、主キーインデックスのデータ構造が頻繁に変化するためで、補助インデックスデータ領域にディスクアドレスが記録されているとします。 10 個の補助インデックスがある場合、主キーのインデックス構造が変更されると、補助インデックスに 1 つずつ通知する必要があり、主キーのインデックス構造は頻繁に変更され、追加と削除はその
データ構造に影響を与える可能性があります。
以上がMySQL の最適化とインデックス作成の方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。