
ホームページ >データベース >mysql チュートリアル >MySQL で SELECT * を使用することが推奨されないのはなぜですか?
MySQL で SELECT * を使用することが推奨されないのはなぜですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-31 23:10:482222ブラウズ
「SELECT * を使用しない」は MySQL の黄金律になっており、「Alibaba Java 開発マニュアル」にも * の使用は許可されていないと明記されています。クエリのフィールド リストとして使用され、このルールに権威の恩恵が与えられます。

ただし、私は次の 2 つの理由から、開発プロセス中に SELECT * を直接使用することがよくあります。シンプルで、開発効率が非常に高く、後からフィールドを頻繁に追加または変更する場合でも、SQL ステートメントを変更する必要はありません。
時期尚早な最適化は良くないと思います。最初に実際に必要なフィールドを判断し、それらに適切なインデックスを作成できる場合を除き、そうでない場合は、問題が発生したときに SQL を最適化することを選択します (もちろん、問題が致命的でない場合に限ります)。
-
しかし、
SELECT * を直接使用することが推奨されない理由を常に知る必要があります。この記事では、その理由を 4 つの側面から説明します。
1. 不必要なディスク I/OMySQL は基本的にユーザー レコードをディスクに保存するため、クエリ操作はディスク IO を実行する動作であることがわかっています (ただし、クエリされたレコードがメモリにキャッシュされます)。
クエリするフィールドが増えるほど、読み取る必要があるコンテンツも多くなり、ディスク IO オーバーヘッドが増加します。特に一部のフィールドのタイプが
TEXT、
MEDIUMTEXT、または BLOB である場合、その影響は特に顕著です。 SELECT *
理論的にはそうではありません。サーバー層では、完全な結果セットがメモリに保存されてから一度にクライアントに渡されるのではなく、ストレージ エンジンから行が取得されるたびに、これは、net_buffer というメモリ空間への書き込みです。このメモリのサイズは、システム変数
によって制御されます。デフォルトは 16KB で、net_buffer がいっぱいの場合は、ローカル ネットワーク スタック ソケット送信バッファ のメモリ空間に書き込まれたデータがクライアントに送信され、送信が成功すると (クライアントの読み取りが完了すると)、クリアされます net_buffer を実行し、引き続き次の行を読み取り、Enter と書き込みます。 言い換えると、デフォルトでは、結果セットが占有する最大メモリ領域は net_buffer_length のみであり、フィールドがいくつか増えたからといって追加のメモリ領域を占有することはありません。
2. ネットワーク遅延を増やす 前の点に従って、
内のデータが毎回クライアントに送信されますが、データは量は多くありませんが、我慢できません。実際に
TEXT、MEDIUMTEXT、または BLOB 型のフィールドを見つけるために使用した人もいます。 . 総データ量が膨大になり、これはネットワーク通信量の増加に直結します。 MySQL とアプリケーションが同じマシン上にない場合、このオーバーヘッドは非常に明白です。 MySQL サーバーとクライアントが同じマシン上にある場合でも、それらの間の通信には TCP プロトコルを使用する必要があるため、転送時間も長くなります。 3. カバーインデックスは使用できません
この問題を説明するには、テーブルを作成する必要があります
CREATE TABLE `user_innodb` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `gender` tinyint(1) DEFAULT NULL, `phone` varchar(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `IDX_NAME_PHONE` (`name`,`phone`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
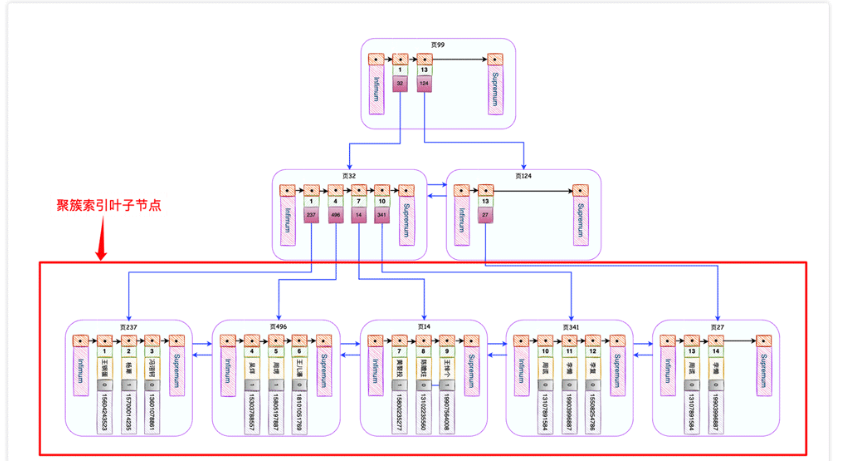
ストレージ エンジン InnoDB を使用してテーブルを作成しました
user_innodb、主キーとして
id を設定し、name と phone の結合インデックスを作成し、最後に 500W のデータをランダムに初期化しましたテーブルに。 InnoDB は、主キー id の主キー インデックス (クラスター化インデックスとも呼ばれる) と呼ばれる B ツリーを自動的に作成します。この B ツリーの最も重要な機能は、リーフ ノードには完全なユーザー レコードが含まれます。
SELECT * FROM user_innodb WHERE name = '蝉沐风';
 EXPLAIN
EXPLAINを使用してステートメントの実行計画を表示します:
IDX_NAME_PHONE インデックスを使用することがわかりました。セカンダリ インデックスのリーフ ノードは次のようになります。
インデックスを使用することがわかりました。セカンダリ インデックスのリーフ ノードは次のようになります。
name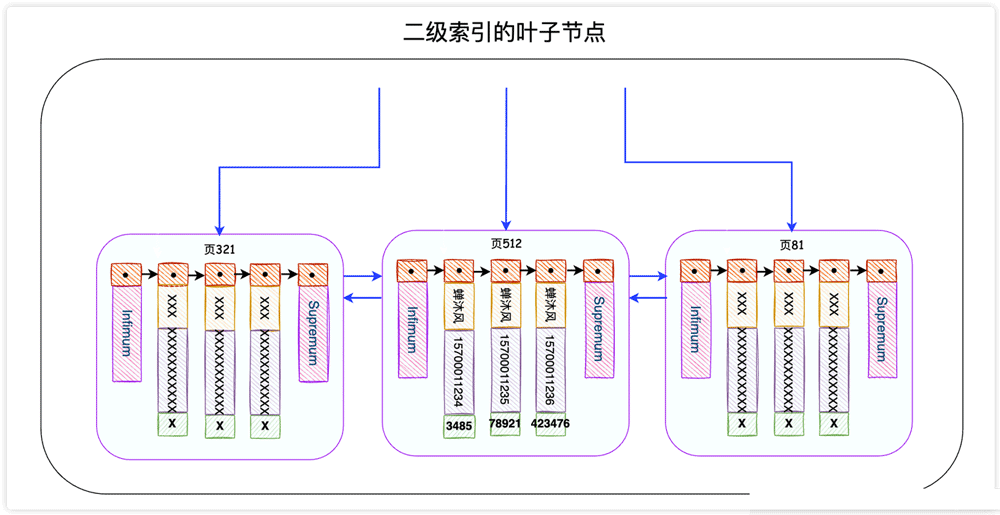 を見つけます。検索条件。
を見つけます。検索条件。
のレコードですが、name、phone、および主キー id フィールドのみがセカンダリ インデックスに記録されます (使用を依頼したのは SELECT *)、そのため、InnoDB は主キー id を取得して、主キー インデックス内のこの完全なレコードを検索する必要があります。このプロセスは と呼ばれます。テーブルに戻ります。 考えてみて、セカンダリ インデックスのリーフ ノードに必要なデータがすべて含まれている場合、テーブルを返す必要はないでしょうか。はい、それは カバーインデックスです。
たとえば、name、
phone、および主キー フィールドを検索したいだけです。 <pre class="brush:sql;">SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";</pre><p>使用<code>EXPLAIN查看一下语句的执行计划:

可以看到Extra一列显示Using index,表示我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是使用了覆盖索引,能够直接摒弃回表操作,大幅度提高查询效率。
4. 可能拖慢JOIN连接查询
我们创建两张表t1,t2进行连接操作来说明接下来的问题,并向t1表中插入了100条数据,向t2中插入了1000条数据。
CREATE TABLE `t1` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT; CREATE TABLE `t2` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT;
如果我们执行下面这条语句
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.m = t2.m;
这里我使用了STRAIGHT_JOIN强制令
t1表作为驱动表,t2表作为被驱动表
对于连接查询而言,驱动表只会被访问一遍,而被驱动表却要被访问好多遍,具体的访问次数取决于驱动表中符合查询记录的记录条数。现在,我们来讲一下两个表连接的本质,因为驱动表和被驱动表已经被强制确定
t1作为驱动表,针对驱动表的过滤条件,执行对t1表的查询。因为没有过滤条件,也就是获取t1表的所有数据;对上一步中获取到的结果集中的每一条记录,都分别到被驱动表中,根据连接过滤条件查找匹配记录
用伪代码表示的话整个过程是这样的:
// t1Res是针对驱动表t1过滤之后的结果集
for (t1Row : t1Res){
// t2是完整的被驱动表
for(t2Row : t2){
if (满足join条件 && 满足t2的过滤条件){
发送给客户端
}
}
}这种方法最简单,但同时性能也是最差,这种方式叫做嵌套循环连接(Nested-LoopJoin,NLJ)。怎么加快连接速度呢?
其中一个办法就是创建索引,最好是在被驱动表(t2)连接条件涉及到的字段上创建索引,毕竟被驱动表需要被查询好多次,而且对被驱动表的访问本质上就是个单表查询而已(因为t1结果集定了,每次连接t2的查询条件也就定死了)。
既然使用了索引,为了避免重蹈无法使用覆盖索引的覆辙,我们也应该尽量不要直接SELECT *,而是将真正用到的字段作为查询列,并为其建立适当的索引。
但是如果我们不使用索引,MySQL就真的按照嵌套循环查询的方式进行连接查询吗?当然不是,毕竟这种嵌套循环查询实在是太慢了!
在MySQL8.0之前,MySQL提供了基于块的嵌套循环连接(Block Nested-Loop Join,BLJ)方法,MySQL8.0又推出了hash join方法,这两种方法都是为了解决一个问题而提出的,那就是尽量减少被驱动表的访问次数。
这两种方法都用到了一个叫做join buffer的固定大小的内存区域,其中存储着若干条驱动表结果集中的记录(这两种方法的区别就是存储的形式不同而已),如此一来,把被驱动表的记录加载到内存的时候,一次性和join buffer中多条驱动表中的记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价,大大减少了重复从磁盘上加载被驱动表的代价。使用join buffer的过程如下图所示:
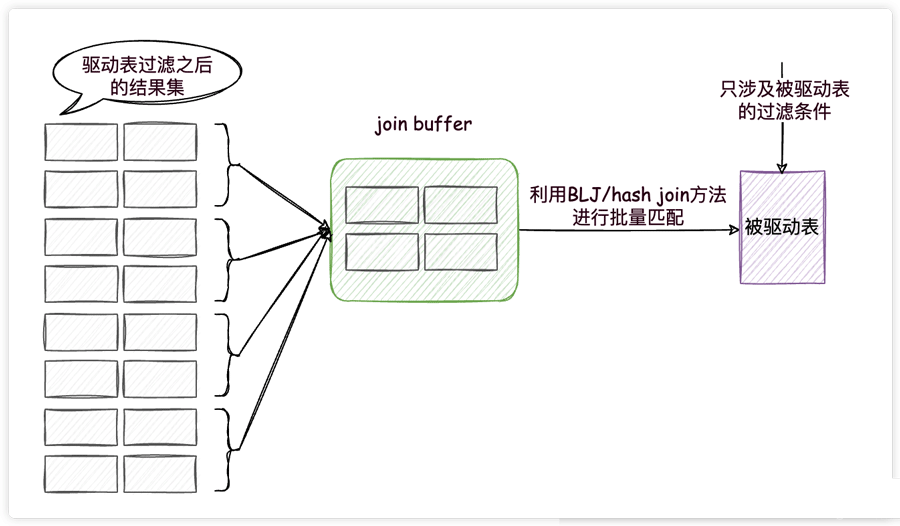
我们看一下上面的连接查询的执行计划,发现确实使用到了hash join(前提是没有为t2表的连接查询字段创建索引,否则就会使用索引,不会使用join buffer)。

最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。我们可以使用join_buffer_size这个系统变量进行配置,默认大小为256KB。如果还装不下,就得分批把驱动表的结果集放到join buffer中了,在内存中对比完成之后,清空join buffer再装入下一批结果集,直到连接完成为止。
重点来了!并不是驱动表记录的所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录,减少分批的次数,也就自然减少了对被驱动表的访问次数
以上がMySQL で SELECT * を使用することが推奨されないのはなぜですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。