
ホームページ >データベース >mysql チュートリアル >mysqlインデックスが速い理由は何ですか?
mysqlインデックスが速い理由は何ですか?

- PHPz転載
- 2023-05-31 20:58:102059ブラウズ
事前ソートにより、二分探索などの高効率なアルゴリズムを使用してインデックスを検索できます。一般的な逐次探索の複雑さは O(n) ですが、二分探索の複雑さは O(log2n) であり、n が非常に大きい場合、両者の効率の差は大きくなります。
Mysql はインターネット上で非常に人気のあるデータベースです。その基盤となるストレージ エンジンとデータ取得エンジンの設計は非常に重要です。特に、Mysql データの格納形式とインデックスの設計が決まります。 Mysql の全体的なデータの取得パフォーマンス。
インデックスの機能はデータを迅速に取得することであり、高速取得の本質はデータ構造であることはわかっています。さまざまなデータ構造を選択することで、さまざまなデータを迅速に取得できます。データベースには大量のデータが保存されており、効率的なインデックスにより時間を大幅に節約できるため、データベースでは効率的な検索アルゴリズムが非常に重要です。たとえば、次のデータ テーブルでは、Mysql がインデックス アルゴリズムを実装していない場合、id=7 のデータを見つけるには、暴力的シーケンシャル トラバーサルのみを使用できます。id=7 のデータを見つけるには、次のようにします。このテーブルに 1000 万件のデータが格納されている場合、id=1000W のデータを検索するには 1000W 回比較することになり、この速度は許容できません。

1. Mysql インデックスの基礎となるデータ構造の選択
ハッシュ テーブル (ハッシュ)
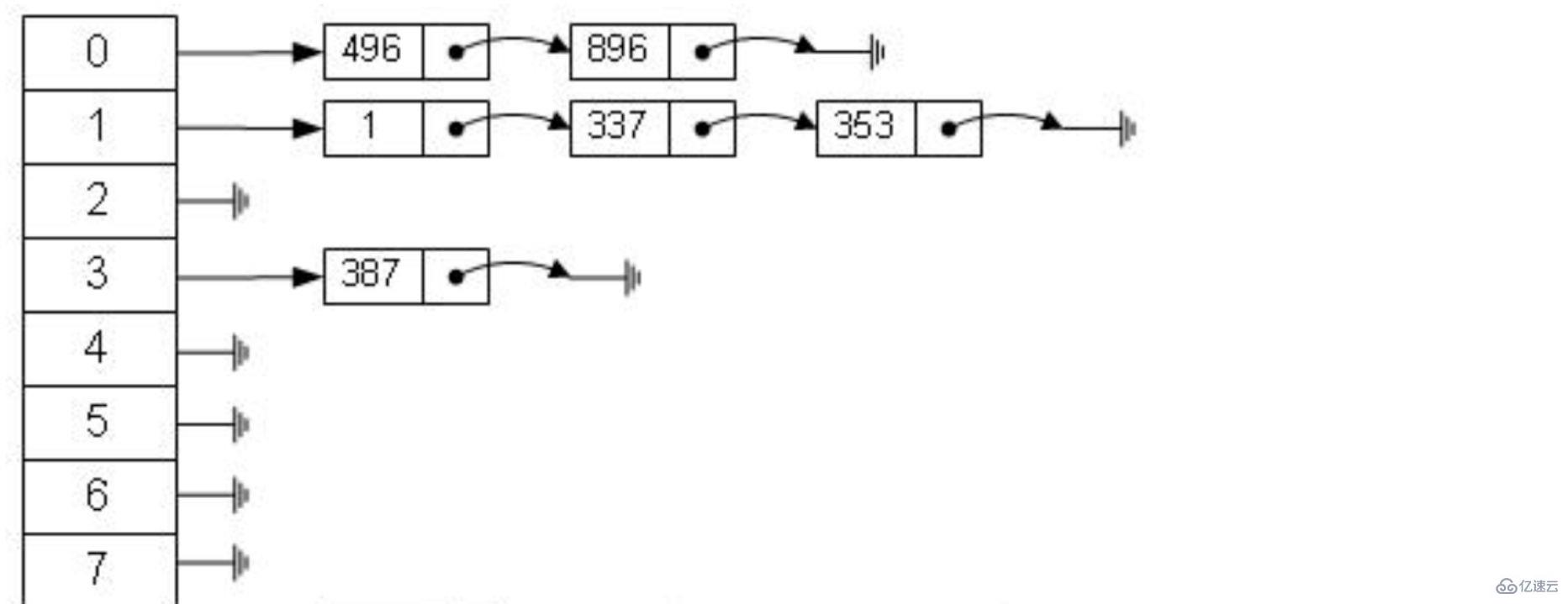
ハッシュ テーブルは、データを高速に取得するための効果的なツールです。 ハッシュ アルゴリズム: ハッシュ アルゴリズムとも呼ばれ、ハッシュ関数を通じて任意の値 (キー) を固定長のキー アドレスに変換し、このアドレスを使用して特定のデータのデータ構造を作成します。 #このデータベース テーブル ユーザーについて考えてみましょう。テーブルには 7 つのデータがあります。id= を使用してデータを取得する必要があります。 7. SQL 構文は次のとおりです。
#このデータベース テーブル ユーザーについて考えてみましょう。テーブルには 7 つのデータがあります。id= を使用してデータを取得する必要があります。 7. SQL 構文は次のとおりです。 select * from user where id=7;
ハッシュ アルゴリズムは、最初に物理アドレス addr=hash(7)=4231 を計算して、id=7 のデータを保存します。4231 によってマップされた物理アドレスは 0x77 であり、 0x77 は id=7 が格納される場所です データの物理アドレス user_name='g' に対応するデータはこの独立したアドレスから見つけることができます。これは、データを迅速に取得するためにハッシュ アルゴリズムで使用される計算プロセスです。
しかし、ハッシュ アルゴリズムにはデータ衝突の問題があります。つまり、ハッシュ関数は異なるキーに対して同じ結果を計算する可能性があります。たとえば、hash(7) は hash(199) と同じ結果を計算する可能性があります。つまり、異なるキーが同じ結果にマッピングされており、これは衝突の問題です。衝突問題を解決する一般的な方法は、リンク リストを使用して衝突するデータを接続するチェーン アドレス法です。ハッシュ値を計算した後、ハッシュ値がデータ リンク リスト内で衝突しているかどうかも確認する必要があります。衝突している場合は、実際のキーに対応するデータが見つかるまで、リンク リストの最後まで走査されます。
 ##アルゴリズムの時間計算量から分析の場合、ハッシュ アルゴリズムの時間計算量は O(1) で、検索速度は非常に高速です。たとえば、id=7 のデータを検索する場合、対応するデータを取得するためにハッシュ インデックスを 1 回計算するだけでよく、検索速度が非常に高速です。しかし、Mysql は基礎となるアルゴリズムとしてハッシュを使用しません。これはなぜでしょうか?
##アルゴリズムの時間計算量から分析の場合、ハッシュ アルゴリズムの時間計算量は O(1) で、検索速度は非常に高速です。たとえば、id=7 のデータを検索する場合、対応するデータを取得するためにハッシュ インデックスを 1 回計算するだけでよく、検索速度が非常に高速です。しかし、Mysql は基礎となるアルゴリズムとしてハッシュを使用しません。これはなぜでしょうか? select * from user where id \>3;上記のステートメントの場合、私たちがやりたいことは、id> を持つデータを見つけることです。 ;3、これは非常に典型的な範囲検索です。ハッシュ アルゴリズムによって実装されたインデックスを使用する場合、範囲検索を行うにはどうすればよいですか?簡単なアイデアは、すべてのデータを一度に検索してメモリにロードし、メモリ内の対象範囲内のデータをフィルタリングすることです。しかし、この範囲検索方法は非常に煩雑であり、まったく効率的ではありません。 したがって、ハッシュ アルゴリズムを使用して実装されたインデックスは、データを高速に取得できますが、データの効率的な範囲検索を行うことができないため、ハッシュ インデックスは Mysql の基礎となるインデックスとして適したデータ構造ではありません。
二分探索ツリー (BST)
二分探索ツリーは、次の図に示すように、高速なデータ検索をサポートするデータ構造です。

 #データベースでは、データの自動インクリメントは非常に一般的な形式です。たとえば、テーブルの主キーなどです。主キーは通常、デフォルトで自動インクリメントされますが、二分木のようなデータ構造をインデックスとして使用すると、上記で紹介したアンバランス状態による線形探索の問題が必然的に発生します。したがって、単純な二分探索木には不均衡による検索パフォーマンスの低下という問題があり、Mysql の基礎となるインデックスの実装に直接使用することはできません。
#データベースでは、データの自動インクリメントは非常に一般的な形式です。たとえば、テーブルの主キーなどです。主キーは通常、デフォルトで自動インクリメントされますが、二分木のようなデータ構造をインデックスとして使用すると、上記で紹介したアンバランス状態による線形探索の問題が必然的に発生します。したがって、単純な二分探索木には不均衡による検索パフォーマンスの低下という問題があり、Mysql の基礎となるインデックスの実装に直接使用することはできません。 二分探索木には不均衡の問題があるため、学者たちは、二分探索木を自動回転と調整によって作成することを提案しました。ツリー ノード 基本的にバランスの取れた状態を常に維持することで、二分探索ツリーの最高の検索パフォーマンスを維持できます。この考え方に基づく自己調整平衡状態を持つバイナリ ツリーには、AVL ツリーと赤黒ツリーが含まれます。
まず、赤黒ツリーについて簡単に紹介します。これは、木の形状を自動的に調整する木構造です。例えば、二分木がアンバランスな状態にある場合、赤黒ツリーは、ノードを自動的に左右に回転させ、ノードの色を変更します 基本的なバランスの取れた状態 (時間計算量が O(logn)) を維持するようにツリーの形状を調整することで、検索効率が大幅に低下することはありません。たとえば、データ ノードが 1 から 7 まで昇順に挿入されると、通常の二分探索木はリンク リストに縮退しますが、赤黒木は図に示すように基本的なバランスを維持するために木の形状を継続的に調整します。下の図のとおりです。以下の赤黒ツリーで id=7 を検索するときに比較されるノードの数は 4 ですが、それでも二分木の良好な検索効率が維持されます。
赤黒ツリーは平均的な検索効率が良く、極端な O(n) 状況はありません。赤黒ツリーは Mysql の基礎となるインデックス実装として使用できますか?実際、赤黒の木にもいくつかの問題があります。次の例を見てください。
赤黒ツリーは 1 ~ 7 個のノードを順番に挿入しますが、id=7 を検索するときに計算する必要があるノードの数は 4 です。 #赤黒ツリーは 1 ~ 16 個のノードを順番に挿入し、比較する必要があるノードの数を決定します。 id=16 の検索は 6 回です。このツリーの形状を観察してください。データを順番に挿入すると、ツリーの形状は常に「右傾」傾向になるというのは本当ですか?基本的に、赤黒ツリーは二分探索ツリーを完全に解決するわけではありません。この「右傾化」の傾向は、線形リンク リストに縮退する二分探索ツリーほど誇張されていませんが、データベースの主キーは一般的に数百万、数千万です。赤黒ツリーにこのような問題が発生すると、検索パフォーマンスも膨大に消費されます。私たちのデータベースは、このような無意味な待機を許容できません。
#赤黒ツリーは 1 ~ 16 個のノードを順番に挿入し、比較する必要があるノードの数を決定します。 id=16 の検索は 6 回です。このツリーの形状を観察してください。データを順番に挿入すると、ツリーの形状は常に「右傾」傾向になるというのは本当ですか?基本的に、赤黒ツリーは二分探索ツリーを完全に解決するわけではありません。この「右傾化」の傾向は、線形リンク リストに縮退する二分探索ツリーほど誇張されていませんが、データベースの主キーは一般的に数百万、数千万です。赤黒ツリーにこのような問題が発生すると、検索パフォーマンスも膨大に消費されます。私たちのデータベースは、このような無意味な待機を許容できません。 
ここで、別のより厳密な自己平衡型バイナリ ツリーである AVL ツリーについて考えてみましょう。 AVL ツリーは完全にバランスの取れたバイナリ ツリーであるため、バイナリ ツリーの形状を調整する際により多くのパフォーマンスを消費します。
AVL ツリーは 1 ~ 7 個のノードを順番に挿入し、id=7 のノードの比較回数は 3 回です。


AVL ツリーの利点を要約します:
- 優れた検索パフォーマンス (O(logn)) により、極端に非効率な検索状況は発生しません。
データベース クエリ データのボトルネックはディスク IO です。AVL ツリーを使用する場合、各ツリー ノードには 1 つのデータしか格納されません。1 つのノードでのみデータを取り出してロードすることができます。たとえば、データ ID=7 をクエリするには、ディスク IO を 3 回実行する必要があり、非常に時間がかかります。したがって、データベースのインデックスを設計するときは、まずディスク IO の数をできるだけ減らす方法を検討する必要があります。
Disk IO はディスクから 1B のデータを読み込むのにかかる時間と 1KB のデータを読み込むのにかかる時間は基本的に同じであるという特性を持っており、この考えに基づいてツリー ノード上で可能な限り多くのデータを読み込むことができます。データをローカルにロードし、1 回のディスク IO でより多くのデータをメモリにロードする、これが B ツリーと B ツリーの設計原則です。
次の B ツリーは、ノードあたり最大 2 つのキーの保存に制限されています。ノードに 3 つ以上のキーがある場合は、自動的にスプリット。たとえば、次の B ツリーには 7 つのデータが格納されています。id=7 のデータの特定の場所を知るには、2 つのノードをクエリするだけで済みます。つまり、2 つのディスク IO で指定されたデータをクエリできます。 AVL ツリー。
 #次は 16 個のデータを格納する B ツリーです。同様に、各ノードには最大 2 つのキーが格納されます. クエリ id=16 のデータは 4 つのノードでクエリおよび比較する必要があり、これは 4 倍のディスク IO を意味します。クエリのパフォーマンスは AVL ツリーと同じのようです。
#次は 16 個のデータを格納する B ツリーです。同様に、各ノードには最大 2 つのキーが格納されます. クエリ id=16 のデータは 4 つのノードでクエリおよび比較する必要があり、これは 4 倍のディスク IO を意味します。クエリのパフォーマンスは AVL ツリーと同じのようです。  ただし、ディスク IO で 1 つのデータを読み取るのにかかる時間は、基本的に読み取り時間と同じであることを考慮します。 100 個のデータ、その後の最適化 この考え方は、1 回のディスク IO でできるだけ多くのデータをメモリに読み取るように変更できます。これはツリーの構造に直接反映され、各ノードが格納できるキーを適切に増やすことができます。
ただし、ディスク IO で 1 つのデータを読み取るのにかかる時間は、基本的に読み取り時間と同じであることを考慮します。 100 個のデータ、その後の最適化 この考え方は、1 回のディスク IO でできるだけ多くのデータをメモリに読み取るように変更できます。これはツリーの構造に直接反映され、各ノードが格納できるキーを適切に増やすことができます。 
16 個のデータを格納する B ツリーでは、id=7 でデータをクエリするには 2 つのディスク IO が必要です。 AVL ツリーと比較すると、ディスク IO の数が半分に減ります。

したがって、データベース インデックス データ構造の選択という点では、B ツリーは非常に良い選択です。要約すると、B ツリーをデータベース インデックスとして使用すると、次のような利点があります。
優れた検索速度、時間計算量: B ツリーの検索パフォーマンスは、 O(h* logn) に等しく、h はツリーの高さ、n は各ノード内のキーワードの数です。
ディスク IO をできるだけ少なくすると、取得速度;
範囲検索をサポートできます。
B ツリー
B ツリーと B ツリーの違いは何ですか?
まず、B ツリーは 1 つのノードにデータを格納し、B ツリーはインデックス (アドレス) を格納するため、B ツリーの 1 つのノードには大量のデータを格納できませんが、1 つのノードにはB ツリーの には多くのインデックスを格納でき、B ツリーのリーフ ノードにはすべてのデータが格納されます。
2 番目、B ツリーの葉ノードは、範囲検索を容易にするために、データ ステージでリンク リストを使用して直列に接続されます。

2. Innodb エンジンと Myisam エンジンの実装
Mysql の基礎となるデータ エンジンはプラグインの形式で設計されており、最も一般的なものは Innodb エンジンと Myisam です。ユーザーは個人のニーズに応じてカスタマイズできますが、Mysql データ テーブルの基礎となるエンジンとして別のエンジンを選択する必要があります。 B-treeはMysqlのインデックスのデータ構造として非常に適していると分析しましたが、データとインデックスをどのように構成するかについても設計が必要であり、設計思想の違いからInnodbやMyisamも登場し、それぞれが独自のパフォーマンスを発揮します。 。 MyISAM は優れたデータ検索パフォーマンスを備えていますが、トランザクション処理はサポートしていません。 Innodb の最大の特徴は、ACID 互換のトランザクション関数をサポートし、行レベルのロックをサポートしていることです。 Mysql がテーブルを作成するときにエンジンを指定できます。たとえば、次の例では、user テーブルと user2 テーブルのデータ エンジンとしてそれぞれ Myisam と Innodb が指定されています。
 #これら 2 つの命令を実行します。次のファイルがシステムに表示され、2 つのエンジンのデータとインデックスが異なる方法で編成されていることを示しています。
#これら 2 つの命令を実行します。次のファイルがシステムに表示され、2 つのエンジンのデータとインデックスが異なる方法で編成されていることを示しています。  テーブルの作成後に Innodb によって生成されるファイルは次のとおりです:
テーブルの作成後に Innodb によって生成されるファイルは次のとおりです: - frm: テーブルを作成するステートメント
- frm: テーブルを作成するステートメント
MYI: テーブル内のインデックス ファイル (myisam インデックス)
生成されたファイルから、これら 2 つのエンジンの基礎となるデータとインデックスが取得されます。 MyISAM エンジンはデータとインデックスを分離し、各人が 1 つのファイルを持ちます (非クラスター化インデックスと呼ばれます)。Innodb エンジンはデータとインデックスを同じファイルに配置します (クラスター化インデックスと呼ばれます)。方法。以下では、これら 2 つのエンジンが B ツリー データ構造にどのように依存して、基礎となる実装の観点からエンジンの実装を整理するかを分析します。
MyISAM エンジンの基盤となる実装 (非クラスター化インデックス方式)
MyISAM は非クラスター化インデックス方式、つまりデータとインデックスを使用します。ファイル上では 2 つの異なるものに分類されます。 MyISAM はテーブルを作成する際、主キーを KEY として主インデックス B ツリーを作成し、ツリーの葉ノードには対応するデータの物理アドレスが格納されます。この物理アドレスを取得したら、MyISAM データ ファイル内の特定のデータ レコードを直接見つけることができます。

Innodb エンジンの基盤となる実装 (クラスター化インデックス メソッド)
InnoDB はクラスター化インデックス メソッドであるため、データとインデックスは同じ場所に保存されます。ファイル。まず、InnoDB は左下図のように主キー ID を KEY としてインデックス B ツリーを構築し、B ツリーの葉ノードには主キー ID に対応するデータが格納されます。 select * from user_info where id=15, InnoDB 主キー ID インデックス B ツリーがクエリされ、対応する user_name='Bob' が検索されます。 これは、テーブルの作成時に InnoDB が主キー ID インデックス ツリーを自動的に構築するときです。これが、Mysql がテーブルの作成時に主キーを指定する必要がある理由です。テーブル内のフィールドにインデックスを追加するとき、InnoDB はどのようにインデックス ツリーを構築しますか?たとえば、user_name フィールドにインデックスを追加する場合、InnoDB は user_name インデックス B ツリーを作成します。user_name の KEY はノードに格納され、リーフ ノードに格納されるデータは主キー KEY になります。リーフには主キー KEY が格納されることに注意してください。主キー KEY を取得した後、InnoDB は主キー インデックス ツリーに移動し、user_name インデックス ツリーで見つかった主キー KEY に基づいて対応するデータを検索します。 #問題は、なぜ InnoDB は特定のデータを主キー インデックス ツリーのリーフ ノードにのみ保存し、他のデータには保存しないのかということです。インデックス ツリーはどうですか? 特定のデータはどうですか? まず主キーを見つけてから、主キー インデックス ツリーで対応するデータを見つける必要がある場合はどうすればよいですか?
#問題は、なぜ InnoDB は特定のデータを主キー インデックス ツリーのリーフ ノードにのみ保存し、他のデータには保存しないのかということです。インデックス ツリーはどうですか? 特定のデータはどうですか? まず主キーを見つけてから、主キー インデックス ツリーで対応するデータを見つける必要がある場合はどうすればよいですか? InnoDB はストレージ スペースを節約する必要があるため、実際には非常に簡単です。 。テーブルには多数のインデックスが存在する可能性があります。InnoDB はインデックス付きフィールドごとにインデックス ツリーを生成します。各フィールドのインデックス ツリーに特定のデータが格納されている場合、このテーブルのインデックス データ ファイルは非常に巨大になります (データが非常に冗長です)。ディスク領域を節約するという観点から見ると、各フィールド インデックス ツリーに特定のデータを保存する必要は実際にはありません。この一見「不必要」な手順により、クエリのパフォーマンスが低下する代わりに、膨大なディスク領域が節約されます。これは非常に価値があります。
InnoDB と MyISAM の機能を比較したときに、MyISAM の方がクエリ パフォーマンスが優れていると述べましたが、その理由は上記のインデックス ファイル データ ファイルの設計からわかります: MyISAM は物理アドレスを直接検索できるため、データはレコードですが、InnoDB がリーフ ノードをクエリした後、特定のデータを見つけるために主キー インデックス ツリーを再度クエリする必要があります。つまり、MyISAM では 1 ステップでデータを見つけることができますが、InnoDB では 2 ステップ必要ですが、当然ながら MyISAM の方がクエリ パフォーマンスは高くなります。
以上がmysqlインデックスが速い理由は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。