
ホームページ >テクノロジー周辺機器 >AI >GPTの現状をついに誰かが明らかにしてくれました! OpenAIの最新のスピーチは急速に広まったが、それはマスク氏が厳選した天才に違いない
GPTの現状をついに誰かが明らかにしてくれました! OpenAIの最新のスピーチは急速に広まったが、それはマスク氏が厳選した天才に違いない

- PHPz転載
- 2023-05-31 16:23:411276ブラウズ
Windows Copilot のリリースに続いて、Microsoft Build カンファレンスは スピーチ によって爆発しました。
元 Tesla AI ディレクターの Andrej Karpathy 氏は、スピーチの中で、tree of thought は AlphaGo の Monte Carlo Tree Search (MCTS) に似ていると信じていました。なんと素晴らしいことでしょう。
ネチズンは叫びました: これは、大規模な言語モデルと GPT-4 モデルの使用方法に関する最も詳細で興味深いガイドです!

さらに、Karpathy 氏は、トレーニングとデータの拡張により、LLAMA 65B が「GPT-3 175B よりも大幅に強力」であることを明らかにしました。大型モデルを導入しました Anonymous Arena ChatBot Arena:
Claude のスコアは ChatGPT 3.5 と ChatGPT 4 の間です。

ネチズンは、カルパシーのスピーチはいつも素晴らしく、今回の内容はいつものように誰もを失望させるものではなかったと述べています。
このスピーチで拡散したのは、そのスピーチをもとに Twitter ネチズンが編集したメモです。メモは 31 件あり、いいねの数は 3,000 を超えています:
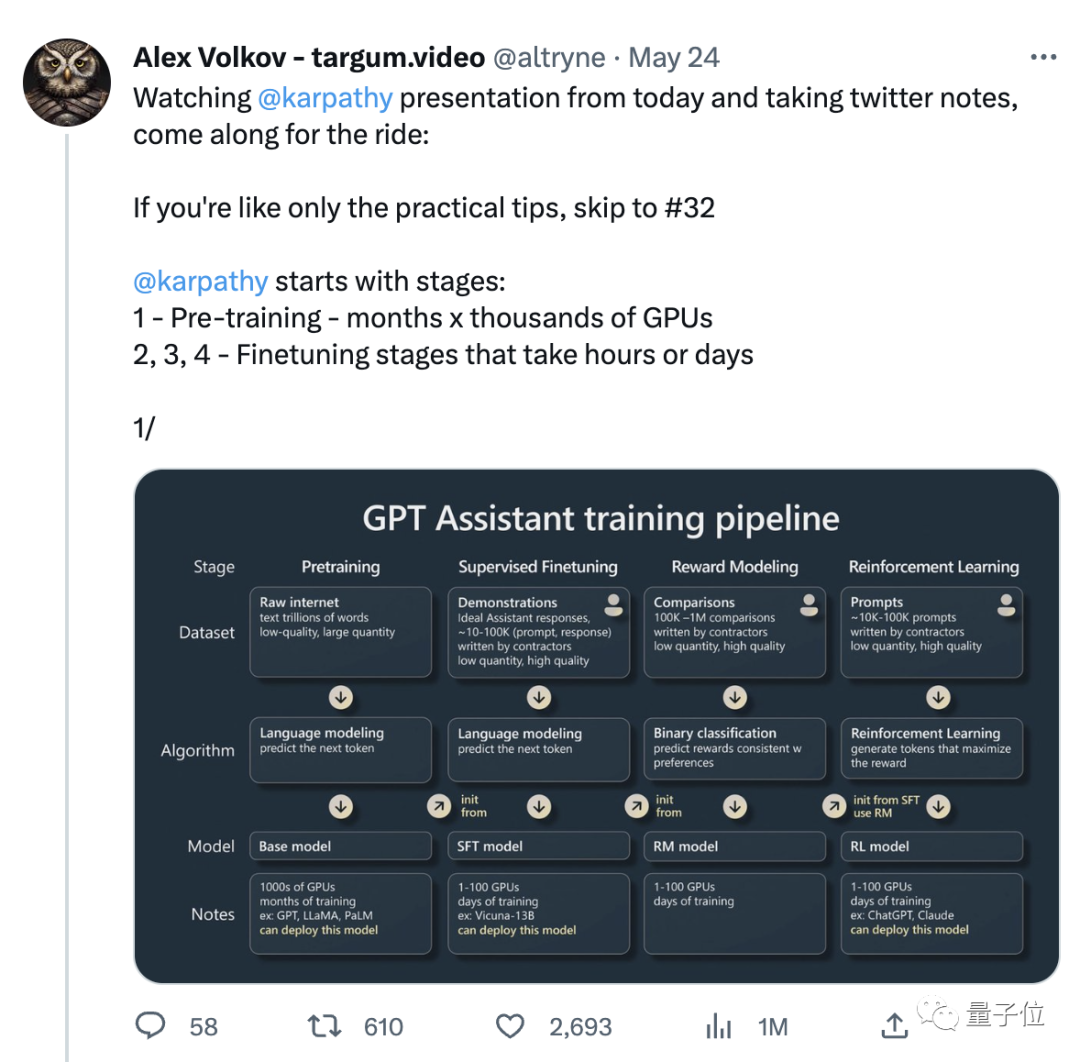
それでは、この待望のスピーチでは具体的にどのような内容が語られたのでしょうか?
GPT アシスタントをトレーニングするにはどうすればよいですか?
今回のカルパシーのスピーチは主に2つのパートに分かれています。
パート 1 では、「GPT アシスタント」をトレーニングする方法について話しました。
Karpathy は主に、AI アシスタントの 4 つのトレーニング段階 (事前トレーニング、教師あり微調整、報酬モデリング、強化学習) について話しています。

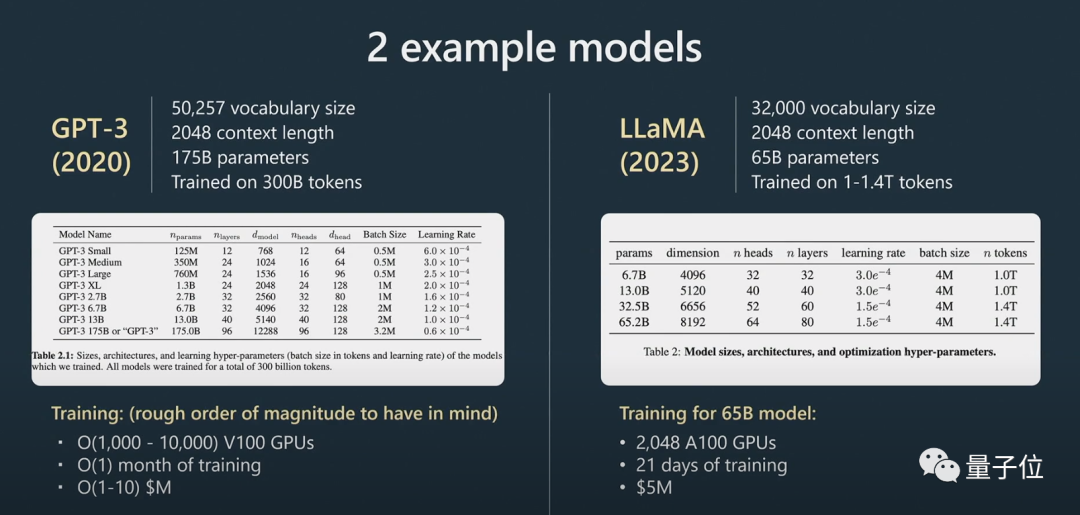
アシスタント モデルを作成できます。
基本モデルはアシスタント モデルではないということです。
基本モデルには問題を解決する機能がありますが、その答えは信頼できませんが、アシスタント モデルは信頼できる答えを提供できます。教師あり微調整アシスタント モデルは、基本モデルに基づいてトレーニングされており、応答の生成とテキスト構造の理解におけるパフォーマンスは、基本モデルよりも優れています。 強化学習は、言語モデルをトレーニングする際のもう 1 つの重要なプロセスです。 トレーニング プロセス中に手動で注釈が付けられた高品質のデータを使用し、報酬モデリング方式で損失関数を作成してパフォーマンスを向上させます。強化トレーニングは、ポジティブなマーキングの確率を高め、ネガティブなマーキングの確率を減らすことによって達成できます。 創造的なタスクに関して AI モデルを改善するには人間の判断が不可欠であり、人間のフィードバックを組み込むことでモデルをより効果的にトレーニングできます。 人間のフィードバックによる強化学習の後、RLHF モデルを取得できます。 モデルがトレーニングされた後の次のステップは、これらのモデルを効果的に使用して問題を解決する方法です。モデルをより効果的に使用するにはどうすればよいですか?
パート 2 では、Karpathy が戦略の促進、微調整、急速に進化するツール エコシステム、将来の拡張について説明します。
カルパシーは、別の具体的な例を挙げて説明しました。
文章を書くとき、私たちは多くの精神活動を行う必要があります。表現が正確かどうかを検討することも含めて。 GPT の場合、これは単にタグ付けされたトークンのシーケンスにすぎません。そして
prompt は、この認知的ギャップを補うことができます。
カルパシーは、思考連鎖プロンプトがどのように機能するかをさらに説明しました。
推論の問題について、自然言語処理で Transformer のパフォーマンスを向上させたい場合は、非常に複雑な問題を直接投げるのではなく、Transformer に情報を段階的に処理させる必要があります。いくつかの例を与えると、この例のテンプレートを模倣し、最終的な結果がより良くなります。

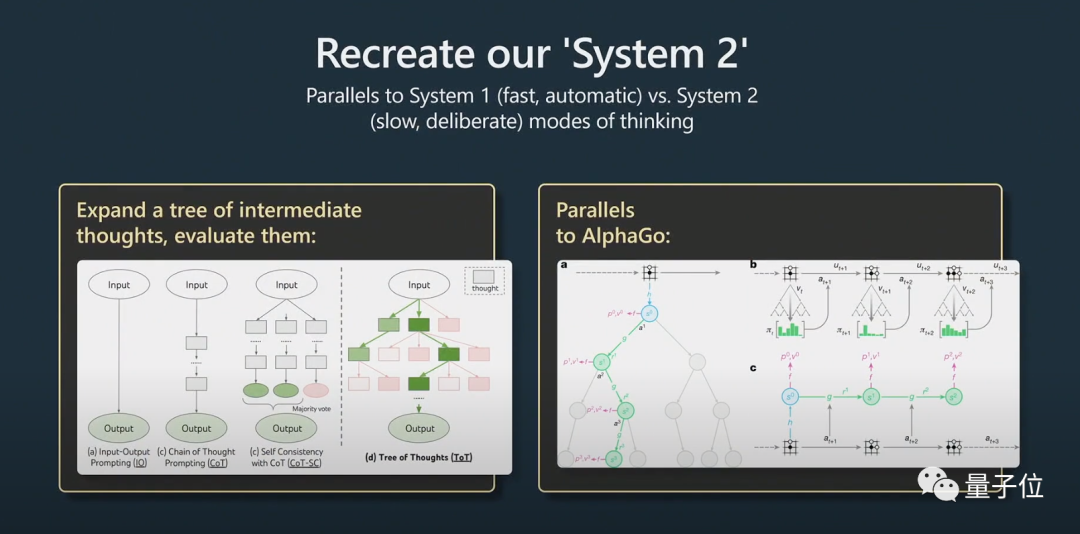 #これには、System1 と System2 の問題が関係します。
#これには、System1 と System2 の問題が関係します。
 「思慮深い」とは、単に質問に答えるということではなく、Python グルー コードで使用されるプロンプトに似ており、多くのプロンプトが連結されて組み込まれています。ヒントをスケーリングするには、モデルで複数のヒントを維持し、ツリー検索アルゴリズムを実行する必要があります。
「思慮深い」とは、単に質問に答えるということではなく、Python グルー コードで使用されるプロンプトに似ており、多くのプロンプトが連結されて組み込まれています。ヒントをスケーリングするには、モデルで複数のヒントを維持し、ツリー検索アルゴリズムを実行する必要があります。
AlphaGo が碁をプレイするとき、次の駒をどこに置くかを考慮する必要があります。最初は人間の真似をして学習しました。
これに加えて、モンテカルロ ツリー検索を実装して、複数の潜在的な戦略による結果を取得します。多くの可能な手を評価し、より良い動きのみを保持します。これはAlphaGoとある程度同等だと思います。これに関連して、Karpathy 氏は AutoGPT についても言及しています。
私は、その効果は現時点ではあまり良くないと考えており、実用化はお勧めしません。私たちは時間の経過によるその進化から学ぶことができるかもしれないと思います。
 第 2 に、もう 1 つの小さなトリックは、拡張生成 (拡張生成の取得) と効果的なプロンプトを取得することです。
第 2 に、もう 1 つの小さなトリックは、拡張生成 (拡張生成の取得) と効果的なプロンプトを取得することです。
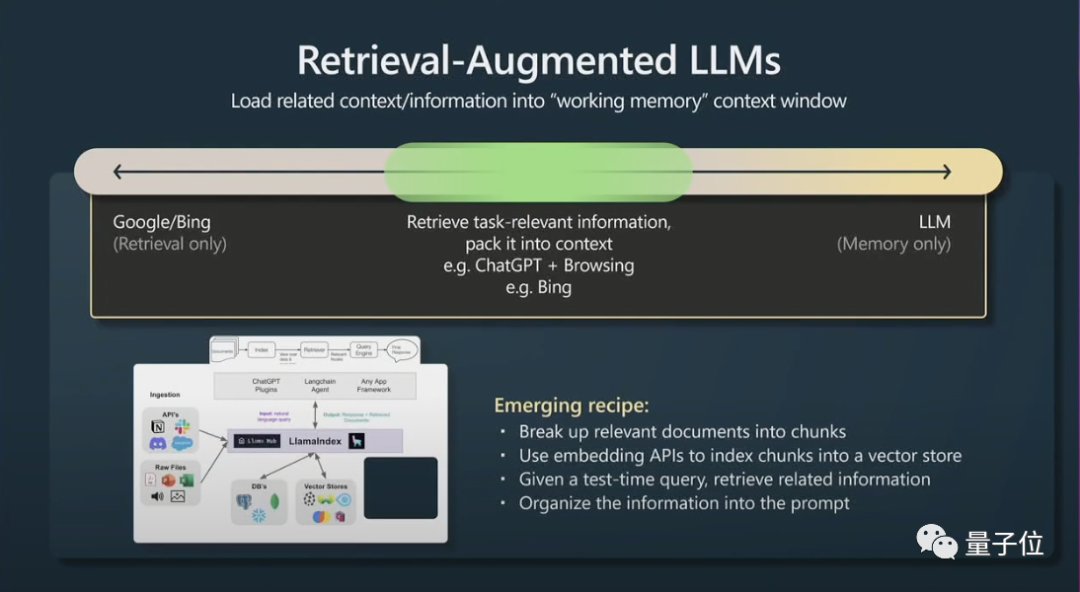
# トランスフォーマーには、参照するメイン ファイルがある場合、パフォーマンスが向上します。
最後に、Karpathy は、大規模な言語モデルにおける制約のプロンプトと微調整について簡単に説明しました。
大規模な言語モデルは、制約のヒントと微調整によって改善できます。制約ヒントは大規模な言語モデルの出力にテンプレートを適用し、微調整によってモデルの重みを調整してパフォーマンスを向上させます。
低リスクのアプリケーションでは大規模な言語モデルを使用し、常に人間の監視と組み合わせ、インスピレーションやアドバイスの源として扱い、副操縦士を完全に自律的に動作させるのではなく副操縦士を考慮することをお勧めします。
Andrej Karpathy について

ポータル:
[1]https://www.youtube.com /watch?v=xO73EUwSegU (スピーチビデオ)
[2]https://arxiv.org/pdf/2305.10601.pdf (「思考の木」論文)
# 参考リンク: [1]https://twitter.com/altryne/status/1661236778458832896
[2]https://www.reddit.com/r/MachineLearning/comments/13qrtek/n_state_of_gpt_by_andrej_karpathy_in_msbuild_2023/
[ 3]https://www.wisdominanutshell.academy/state-of-gpt/
以上がGPTの現状をついに誰かが明らかにしてくれました! OpenAIの最新のスピーチは急速に広まったが、それはマスク氏が厳選した天才に違いないの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。