
ホームページ >テクノロジー周辺機器 >AI >大規模なモデルの知識がなくなったらどうすればよいでしょうか?浙江大学チームは、大規模モデルのパラメータを更新する方法、つまりモデル編集を研究しています
大規模なモデルの知識がなくなったらどうすればよいでしょうか?浙江大学チームは、大規模モデルのパラメータを更新する方法、つまりモデル編集を研究しています

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-30 22:11:091490ブラウズ
Xi Xiaoyao Science and Technology Talk 原著者 | Xiaoxi、Python
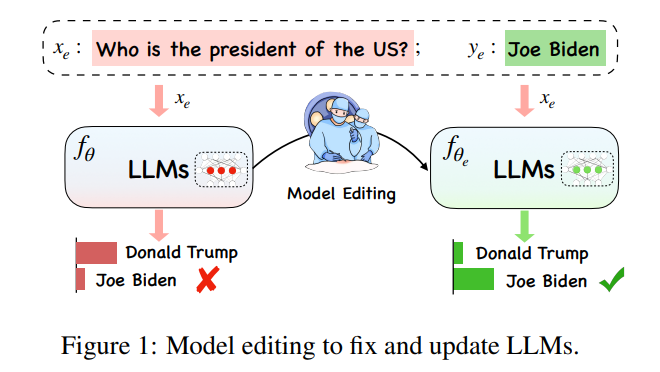
大規模モデルの巨大なサイズの背後には、「大規模モデルをどのように更新する必要があるか?」という直観的な疑問があります。
in 大規模モデルの非常に膨大なコンピューティング オーバーヘッドの下では、大規模モデルの知識を更新することは単純な「学習タスク」ではありません。理想的には、世界のさまざまな状況が複雑に変化する中、大規模モデルもいつでもどこでも時代に追いつくことができる必要があります。しかし、新しい大規模なモデルをトレーニングする計算負荷のため、大規模なモデルをすぐに更新することはできません。そこで、特定の分野のモデル データに悪影響を与えることなく効果的に処理することを実現するための新しい概念「モデル編集」が生まれました。他の入力の結果。

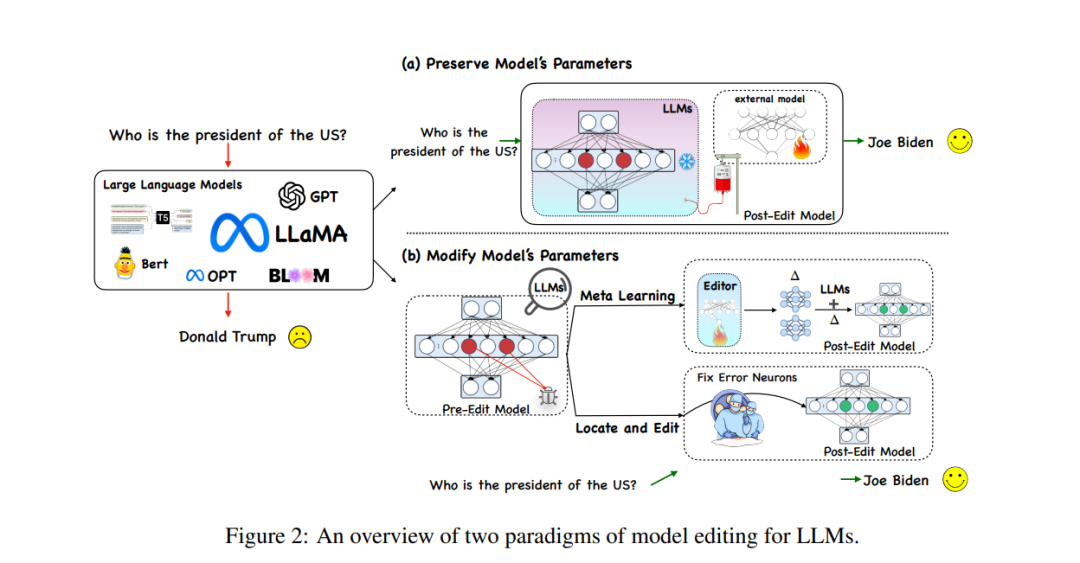
もう 1 つの主要なカテゴリのメソッドである、元のモデルのパラメータを変更する方法は、主に Δ マトリックスを使用してモデル内の一部のパラメータを更新します。メタ学習メソッドには 2 つのタイプがあります。名前からわかるように、Locate-Then-Edit メソッドは、最初にモデル内で主要な影響を与えるパラメーターを特定し、次に特定されたモデル パラメーターを変更してモデル編集を実装します。主な手法としては、モデル内の「知識ニューロン」を特定することで主な影響パラメータを決定し、これらのニューロンを更新することでモデルを更新するナレッジ ニューロン法 (KN) などがあります。ROME と呼ばれる別の手法は、KN と同様の考え方を持ち、因果関係中間分析による編集領域の更新に加えて、一連の編集記述を更新するために使用できる MEMIT メソッドもあります。このタイプの方法の最大の問題は、一般に事実知識の局所性の仮定に依存していることですが、この仮定は広く検証されておらず、多くのパラメーターを編集すると予期しない結果が生じる可能性があることです。
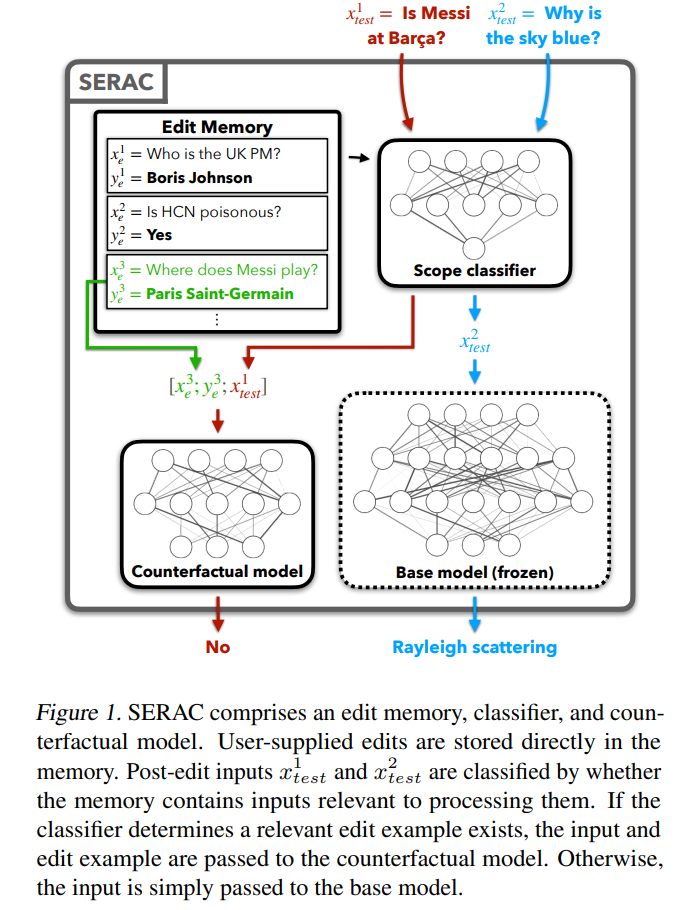
メタ学習メソッドは、Locate-Then-Edit メソッドとは異なります。メタ学習メソッドは、ハイパー ネットワーク メソッドを使用し、特にナレッジ エディター メソッドで、ハイパー ネットワークを使用して別のネットワークの重みを生成します。著者は双方向 LSTM を使用して、各データ ポイントがモデルの重みにもたらす更新を予測し、それによって編集ターゲットの知識の制約付き最適化を実現します。この種の知識編集手法は、LLM のパラメータが膨大であるため、LLM に適用するのが困難であるため、Mitchell らは、単一の編集記述で効率的に LLM を更新できる MEND (Model Editor Networks with Gradient Decomposition) を提案しました。 update この方法では、主に勾配の低ランク分解を使用して大規模モデルの勾配を微調整することで、LLM へのリソースの更新を最小限に抑えることができます。 Locate-Then-Edit メソッドとは異なり、メタ学習メソッドは通常、時間がかかり、より多くのメモリ コストを消費します。
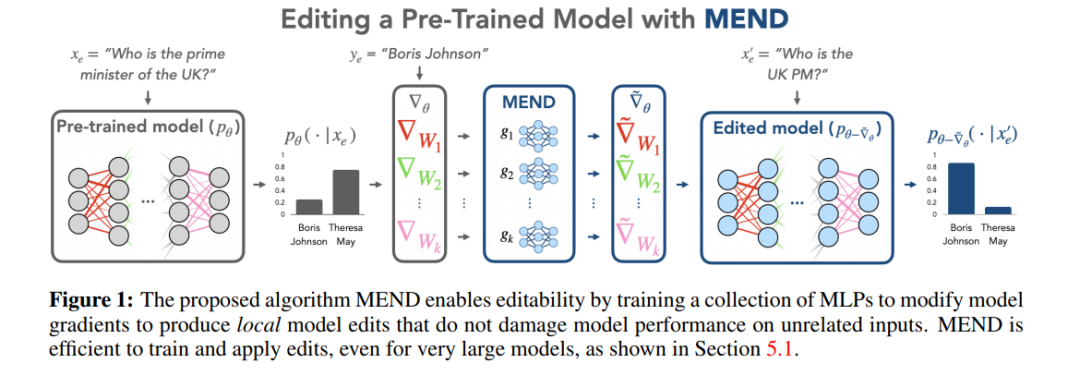
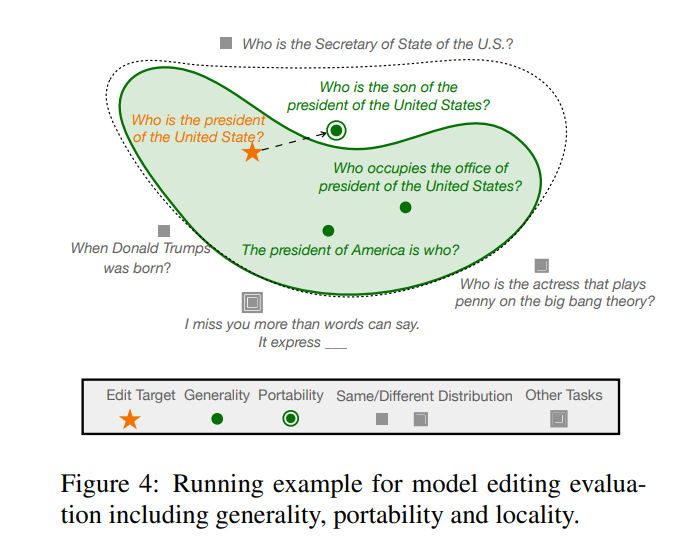
メソッド評価
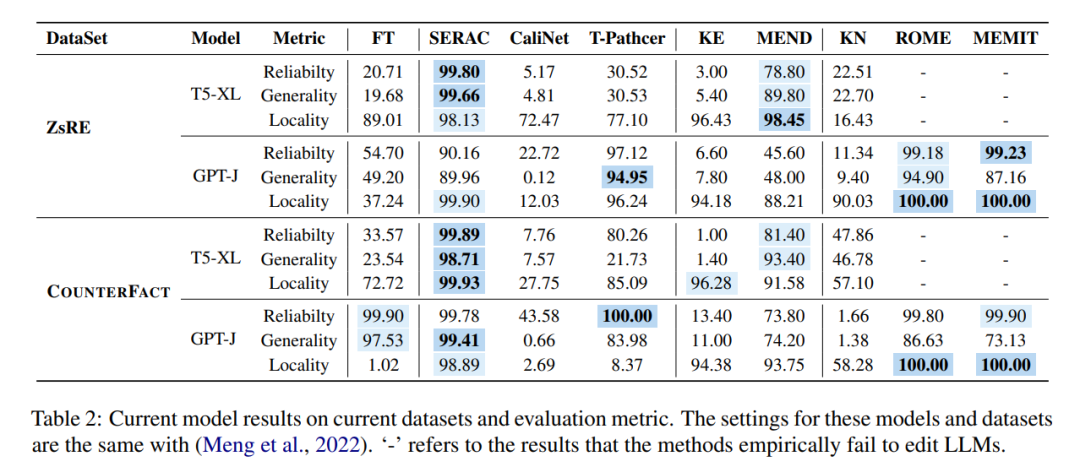
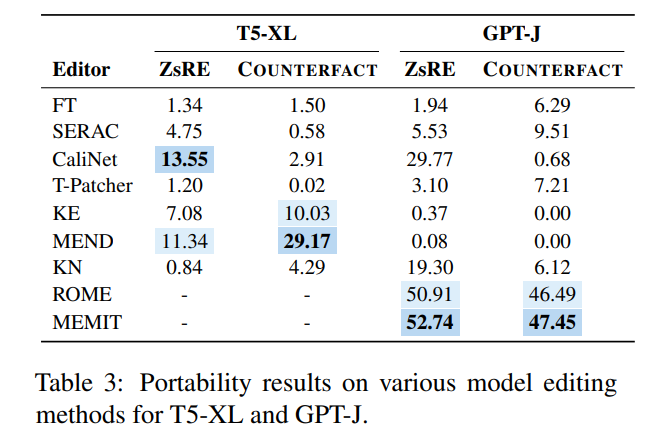
これらのさまざまなメソッドは、2 つの主流データ セット ZsRE (逆変換を使用した質問と回答のデータ セット) で使用されます。逆変換を使用すると、有効フィールドとして書き換えられます) および COUNTERFACT (反事実データ セット、対象エンティティを有効フィールドとして同義のエンティティに置き換えます) 実験は次の図に示されています。実験は主に 2 つの比較的大きな LLM T5- に焦点を当てています。 XL (3B) および GPT-J (6B) は基本モデルであり、効率的なモデル エディターでは、モデルのパフォーマンス、推論速度、ストレージ スペースのバランスを取る必要があります。
最初の列の微調整 (FT) の結果を比較すると、SERAC と ROME が ZsRE および COUNTERFACT データ セットで良好なパフォーマンスを示し、特に SERAC は複数のデータ セットで 90% 以上を達成したことがわかります。その結果、MEMIT は SERAC や ROME ほど汎用性は高くありませんが、信頼性と局所性の点で優れています。 T-Patcher 法は非常に不安定であり、COUNTERFACT データセットでは信頼性と局所性は優れていますが、一般性に欠けており、GPT-J では信頼性と汎用性は優れていますが、局所性の性能が劣っています。 KE、CaliNET、KN のパフォーマンスが低いことは注目に値しますが、「小規模モデル」でこれらのモデルが達成する優れたパフォーマンスと比較すると、これらの手法が大規模モデルの環境にはあまり適応していないことが実験で証明される可能性があります。
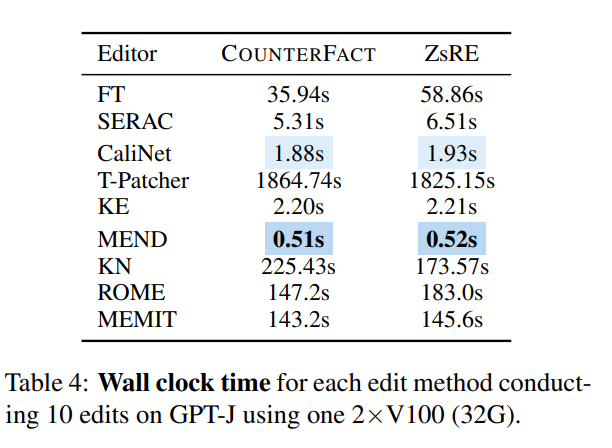
時間の観点から見ると、ネットワークがトレーニングされると、KE と MEND は非常にうまく機能しますが、T-Patcher などの方法は時間がかかりすぎます。
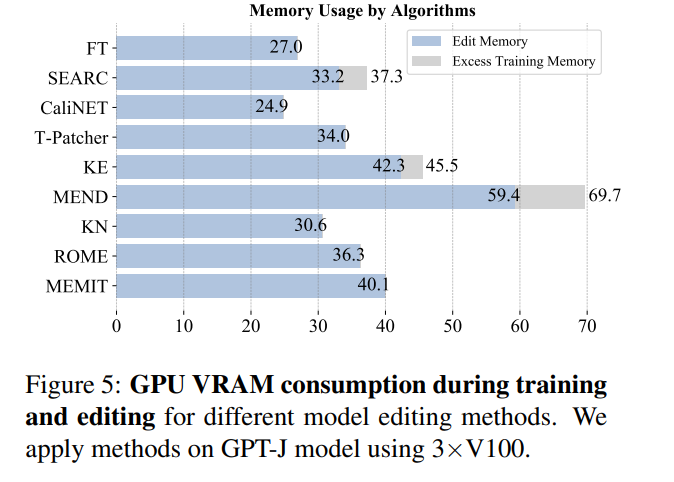
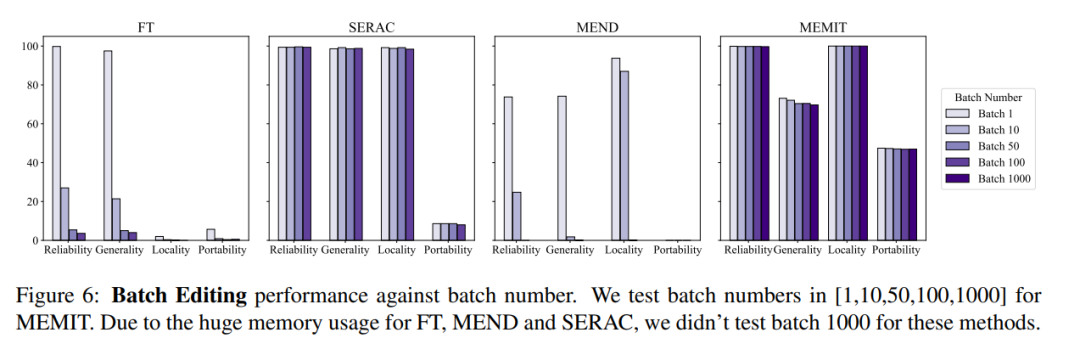
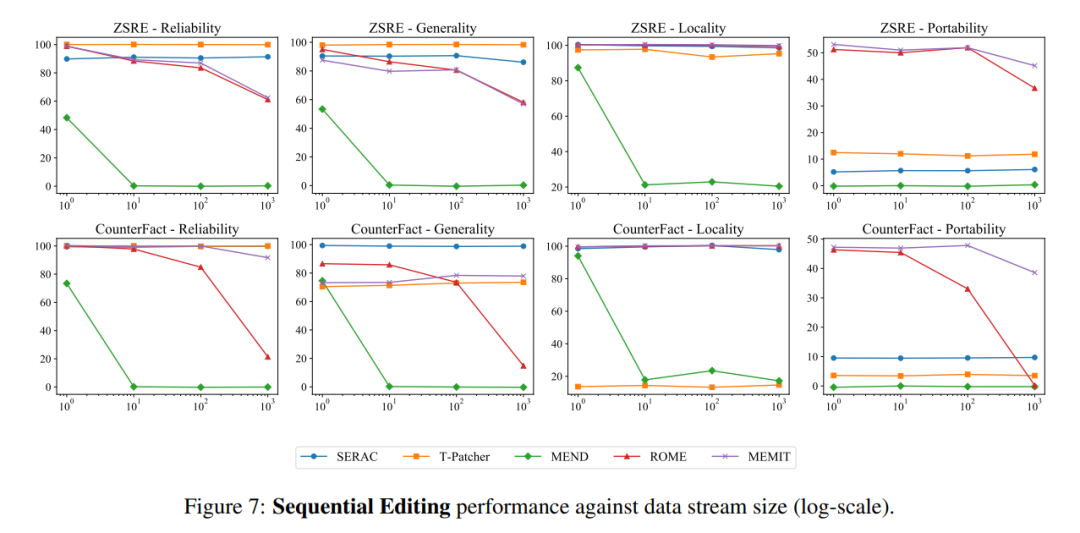
シーケンシャル入力に関しては、SERAC と T-Patcher は良好かつ安定したパフォーマンスを示しましたが、ROME、MEMIT、および MEND はすべて、一定量の入力後にモデルのパフォーマンスが急激に低下しました。
以上が大規模なモデルの知識がなくなったらどうすればよいでしょうか?浙江大学チームは、大規模モデルのパラメータを更新する方法、つまりモデル編集を研究していますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。