
ホームページ >データベース >mysql チュートリアル >mysqlテーブルの4つのパーティショニング方法とは何ですか
mysqlテーブルの4つのパーティショニング方法とは何ですか

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-30 17:17:211596ブラウズ
1. テーブルパーティショニングとは何ですか?
mysql データベースのデータは、ファイルの形式でディスクに保存されます。デフォルトでは、/mysql/data に配置されます (my.cnf の datadir から表示できます)。主に 1 つのテーブルです。 1 つはテーブル構造を格納するための frm、1 つはテーブル データを格納するための myd、もう 1 つはテーブル インデックスを格納するための myi です。テーブル内のデータ量が大きすぎると、myd や myi が非常に大きくなり、データの検索が非常に遅くなりますが、このとき、mysql のパーティション関数を使用して、このテーブルを物理的に対応付けることができます。 3 つのファイルは多くの小さなブロックに分割されています。この方法では、1 つのデータを検索するときに、すべてのファイルを検索する必要はありません。データがどのブロックにあるかを知っていれば、そのブロック内で検索するだけで済みます。ブロック。テーブルに大量のデータがある場合、1 つのディスクにすべてのデータを保持できないように、データを複数のディスクに分散することが必要になる場合があります。
テーブルのパーティショニングとは、データベース内のテーブルを、特定のルールに従って、より小さく管理しやすい複数の部分に分割することです。論理的にはテーブルは 1 つだけですが、最下層は複数の物理パーティションで構成されています。
2. テーブル パーティショニングとテーブル パーティショニングの違い
テーブル パーティショニング: 特定のルールに従ってテーブルを複数の異なるテーブルに分解することを指します。たとえば、ユーザーの注文レコードは時間に基づいて複数のテーブルに分割されます。パーティショニングとテーブルのサブディビジョンの違いは、論理的には、パーティショニングは 1 つのテーブルにすぎないのに対し、テーブルのサブディビジョンは 1 つのテーブルを複数のテーブルに分割することです。
3. テーブルパーティショニングの利点は何ですか?
(1). 単一のディスクまたはファイル システム パーティションと比較して、より多くのデータを保存できます。
一般に、保持値のないデータは、そのデータに関連付けられたパーティションを削除することで簡単に削除できます。新しいデータを簡単に追加するために、これらの新しいデータを特別に保存する新しいパーティションを作成できる場合があります。
(3). 一部のクエリは大幅に最適化できます。これは主に、特定の WHERE ステートメントを満たすデータが 1 つ以上のパーティションにのみ格納できるため、検索時に検索する必要がないためです。残りの他のパーティション。パーティション化テーブルの作成後にパーティション化を変更できるため、最初にパーティション化スキームを構成するときにデータを再編成していない場合でも、よく使用されるクエリの効率を向上させるためにデータを再編成できます。
クエリに SUM() や COUNT() などの集計関数が含まれる場合、それらは簡単に並列処理できます。このようなクエリの簡単な例は、「SELECT sales_id, COUNT (orders) as order_total FROM sales GROUP BY sales_id;」です。 「並列」クエリは、クエリを各パーティションで同時に実行でき、最終結果はすべてのパーティションからの結果を単純に集計することを意味します。
(5). データ クエリを複数のディスクに分散させることで、クエリ スループットを向上させます。
4. パーティション テーブルに関する制限
(1). テーブルには最大 1024 個のパーティションしか含めることができません。
MySQL5.1 では、パーティション式は整数、または整数を返す式のみにすることができます。非整数式パーティショニングのサポートは、MySQL 5.5 で提供されます。
主キー列または一意のインデックス列がパーティション フィールドに含まれている場合は、すべての主キー列と一意のインデックス列を含める必要があります。パーティション フィールドに主キー列とインデックス列が含まれていないか、すべての主キー列とインデックス列が含まれています。
(4). 外部キー制約はパーティションテーブルでは使用できません。
(5) MySQL パーティショニングは、テーブル内のすべてのデータとインデックスに適用されます。テーブル データはパーティション化できますが、インデックスはパーティション化できません。インデックスはパーティション化できますがテーブルはパーティション化できません。テーブルのみをパーティション化することはできません。データ パーティションの一部。
5. 現在の MySQL がパーティショニングをサポートしているかどうかを確認するにはどうすればよいですか?
mysql> show variables like '%partition%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | have_partitioning | YES | +-------------------+-------+ 1 row in set (0.00 sec)
have_partintioning の値は YES で、パーティショニングがサポートされていることを示します。
6. MySQL でサポートされているパーティション タイプは何ですか?
(1)、RANGE パーティショニング: 指定された連続間隔に属する列値に基づいて、複数の行をパーティションに割り当てます。
(2) LIST パーティショニング: RANGE によるパーティショニングと同様ですが、LIST パーティショニングは離散値セット内の特定の値に一致する列値に基づいて選択される点が異なります。
(3)、HASH パーティション: テーブルに挿入される行の列値を使用して計算される、ユーザー定義式の戻り値に基づいて選択されるパーティション。負でない整数値を生成する任意の有効な MySQL 式をこの関数に含めることができます。
(4) KEY パーティショニング: HASH パーティショニングと似ていますが、異なる点は、KEY パーティショニングが 1 つ以上のカラムの計算のみをサポートし、MySQL サーバーが独自のハッシュ関数を提供することです。整数値を含む列が 1 つ以上存在する必要があります。
注: バージョン MySQL 5.1 では、RANGE、LIST、および HASH パーティションでは、パーティション キーが INT 型であるか、式を通じて INT 型を返す必要があります。 KEYパーティション化を行う場合、BLOB型やTEXT型の列に加えて、他の型の列もパーティションキーとして使用できます。
6.1. RANGE パーティション
範囲に基づくパーティションです。範囲は連続的である必要がありますが、重複してはなりません。PARTITION BY RANGE, VALUES LESS THAN キーワードを使用します。 COLUMNS キーワードを使用しない場合、RANGE 括弧は整数フィールド名、または明確な整数を返す関数である必要があります。
6.1.1. 数値範囲によると
drop table if exists employees;
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null default 0,
store_id int not null default 0
)engine=myisam default charset=utf8
partition by range(store_id)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21)
);rrree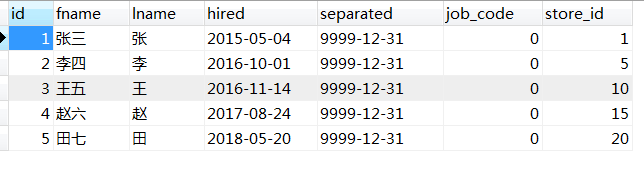
按照这种分区方案,在商店1到5工作的雇员相对应的所有行被保存在分区P0中,商店6到10的雇员保存在P1中,依次类推。注意,每个分区都是按顺序进行定义,从最低到最高。这是PARTITION BY RANGE 语法的要求。
对于包含数据(6,'亢八','亢','2018-06-24',13)的一个新行,可以很容易地确定它将插入到p2分区中。
insert into employees (id,fname,lname,hired,store_id) values(6,'亢八','亢','2018-06-24',13);
但是如果增加了一个编号为第21的商店(7,'周九','周','2018-07-24',21),将会发生什么呢?在这种方案下,由于没有规则把store_id大于20的商店包含在内,服务器将不知道把该行保存在何处,将会导致错误。
insert into employees (id,fname,lname,hired,store_id) values(7,'周九','周','2018-07-24',21); ERROR 1526 (HY000): Table has no partition for value 21
要避免这种错误,可以通过在CREATE TABLE语句中使用一个“catchall” VALUES LESS THAN子句,该子句提供给所有大于明确指定的最高值的值:
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null default 0,
store_id int not null default 0
)engine=myisam default charset=utf8
partition by range(store_id)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21),
partition p4 values less than MAXVALUE
);6.1.2、根据TIMESTAMP范围
drop table if exists quarterly_report_status; create table quarterly_report_status( report_id int not null, report_status varchar(20) not null, report_updated timestamp not null default current_timestamp on update current_timestamp ) partition by range(unix_timestamp(report_updated))( partition p0 values less than (unix_timestamp('2008-01-01 00:00:00')), partition p1 values less than (unix_timestamp('2008-04-01 00:00:00')), partition p2 values less than (unix_timestamp('2008-07-01 00:00:00')), partition p3 values less than (unix_timestamp('2008-10-01 00:00:00')), partition p4 values less than (unix_timestamp('2009-01-01 00:00:00')), partition p5 values less than (unix_timestamp('2009-04-01 00:00:00')), partition p6 values less than (unix_timestamp('2009-07-01 00:00:00')), partition p7 values less than (unix_timestamp('2009-10-01 00:00:00')), partition p8 values less than (unix_timestamp('2010-01-01 00:00:00')), partition p9 values less than maxvalue );
6.1.3、根据DATE、DATETIME范围
添加COLUMNS关键字可定义非integer范围及多列范围,不过需要注意COLUMNS括号内只能是列名,不支持函数;多列范围时,多列范围必须呈递增趋势:
drop table if exists member; create table member( firstname varchar(25) not null, lastname varchar(25) not null, username varchar(16) not null, email varchar(35), joined date not null ) partition by range columns(joined)( partition p0 values less than ('1960-01-01'), partition p1 values less than ('1970-01-01'), partition p2 values less than ('1980-01-01'), partition p3 values less than ('1990-01-01'), partition p4 values less than maxvalue )
6.1.4、根据多列范围
drop table if exists rc3; create table rc3( a int, b int ) partition by range columns(a,b)( partition p0 values less than (0,10), partition p1 values less than (10,20), partition p2 values less than (20,30), partition p3 values less than (30,40), partition p4 values less than (40,50), partition p5 values less than (maxvalue,maxvalue) )
6.1.5、RANGE分区在如下场合特别有用
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 )engine=myisam default charset=utf8 partition by range(year(separated))( partition p0 values less than (1991), partition p1 values less than (1996), partition p2 values less than (2001), partition p4 values less than MAXVALUE );
只需删除分区,就能清除“旧的”数据。如果你使用上面最近的那个例子给出的分区方案,你只需简单地使用”alter table staff drop partition p0;”来删除所有在1991年前就已经停止工作的雇员相对应的所有行。对于有大量行的表,这比运行一个如”delete from staff WHERE year(separated)
(2)、想要使用一个包含有日期或时间值,或包含有从一些其他级数开始增长的值的列。
(3)、经常运行直接依赖于用于分割表的列的查询。例如,当执行一个如”select count(*) from staff where year(separated) = 200 group by store_id;”这样的查询时,MySQL可以很迅速地确定只有分区p2需要扫描,这是因为余下的分区不可能包含有符合该WHERE子句的任何记录。
6.2、LIST分区
根据具体数值分区,每个分区数值不重叠,使用PARTITION BY LIST、VALUES IN关键字。在不使用COLUMNS关键字的情况下,与Range分区类似,List括号内必须是整数字段名或返回确定整数的函数。
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr”是某列值或一个基于某个列值、并返回一个整数值的表达式,然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。
假定有20个音像店,分布在4个有经销权的地区,如下表所示:
====================
地区 商店ID 号
北区 3, 5, 6, 9, 17
东区 1, 2, 10, 11, 19, 20
4, 12, 13, 14, 18是西区的编号
中心区 7, 8, 15, 16
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by list(store_id)( partition pNorth values in (3,5,6,9,17), partition pEast values in (1,2,10,11,19,20), partition pWest values in (4,12,13,14,18), partition pCentral values in (7,8,15,16) );
这使得在表中增加或删除指定地区的雇员记录变得容易起来。例如,假定西区的所有音像店都卖给了其他公司。那么与在西区音像店工作雇员相关的所有记录(行)可以使用查询“ALTER TABLE staff DROP PARTITION pWest;”来进行删除,它与具有同样作用的DELETE(删除)“DELETE FROM staff WHERE store_id IN (4,12,13,14,18);”比起来,要有效得多。
如果试图插入列值(或分区表达式的返回值)不在分区值列表中的一行时,那么“INSERT”查询将失败并报错。
当插入多条数据出错时,如果表的引擎支持事务(Innodb),则不会插入任何数据;如果不支持事务,则出错前的数据会插入,后面的不会执行。
与Range分区相同,添加COLUMNS关键字可支持非整数和多列。
6.3、HASH分区
Hash分区主要用来确保数据在预先确定数目的分区中平均分布,Hash括号内只能是整数列或返回确定整数的函数,实际上就是使用返回的整数对分区数取模。
要使用HASH分区来分割一个表,要在CREATE TABLE 语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回一个整数的表达式。它可以仅仅是字段类型为MySQL整型的一列的名字。此外,你很可能需要在后面再添加一个“PARTITIONS num”子句,其中num是一个非负的整数,它表示表将要被分割成分区的数量。
如果没有包括一个PARTITIONS子句,那么分区的数量将默认为1
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by hash(store_id) partitions 4;
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by hash(year(hired)) partitions 4;
Hash分区也存在与传统Hash分表一样的问题,可扩展性差。MySQL也提供了一个类似于一致Hash的分区方法-线性Hash分区,只需要在定义分区时添加LINEAR关键字。
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by linear hash(year(hired)) partitions 4;
线性哈希功能,它与常规哈希的区别在于,线性哈希功能使用的一个线性的2的幂(powers-of-two)运算法则,而常规哈希使用的是求哈希函数值的模数。
6.4、KEY分区
Key分区与Hash分区很相似,只是Hash函数不同,定义时把Hash关键字替换成Key即可,同样Key分区也有对应与线性Hash的线性Key分区方法。
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by key(store_id) partitions 4;
在KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样的作用,分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
另外,当表存在主键或唯一索引时可省略Key括号内的列名,Mysql将按照主键-唯一索引的顺序选择,当找不到唯一索引时报错。
以上がmysqlテーブルの4つのパーティショニング方法とは何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。