
ホームページ >テクノロジー周辺機器 >AI >GPT-4 推論は 1750% 向上しました。プリンストン清華ヤオクラスの卒業生が、LLM が繰り返し考えることを可能にする新しい「Thinking Tree ToT」フレームワークを提案
GPT-4 推論は 1750% 向上しました。プリンストン清華ヤオクラスの卒業生が、LLM が繰り返し考えることを可能にする新しい「Thinking Tree ToT」フレームワークを提案

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-30 16:25:35895ブラウズ
2022 年、Google Brain の元中国人科学者であるジェイソン ウェイは、思考連鎖に関する先駆的な研究の中で、CoT が LLM の推論能力を強化できることを初めて提案しました。
しかし、思考の連鎖があっても、LLM は非常に単純な質問で間違いを犯すことがあります。
最近、プリンストン大学と Google DeepMind の研究者は、新しい言語モデル推論フレームワークである「Tree of Thinking」(ToT) を提案しました。
ToT は、言語モデルをガイドし、一貫したテキスト単位 (思考) を探索することで問題の中間ステップを解決する、現在人気のある「思考チェーン」手法を一般化します。

紙のアドレス: https://arxiv.org/abs/2305.10601
プロジェクトアドレス: https://github.com/kyegomez/tree-of-thoughts
簡単に言うと、「」思考Tree" を使用すると、LLM は次のことを行うことができます。
· 複数の異なる推論パスを自分に与える
· それぞれを評価した後、次のステップを決定する 行動計画
#· グローバルな意思決定を達成するために、必要に応じて前方または後方にトレースします。論文の実験結果は、ToT が LLM を大幅に改善したことを示しています。 3 つの新しいタスク (24 ポイント ゲーム、クリエイティブ ライティング、ミニ クロスワード パズル) の問題解決能力。
たとえば、24 ポイント ゲームでは、GPT-4 はタスクの 4% しか解決しませんでしたが、ToT メソッドの成功率は 74% に達しました。
LLM に「何度も考えさせる」
テキストの生成に使用された大規模言語モデル GPT と PaLM は、幅広いタスクを実行できることが証明されました。 。これらすべてのモデルの進歩の基礎は、もともとテキストを生成するために使用されていた「自己回帰メカニズム」であり、左から右の方法でトークンレベルの決定を次々と行います。 。

まさに「人間の認知」に関する文献こそが、この問題への手がかりを提供してくれるのです。
「二重プロセス」モデルに関する研究では、人間には 2 つの意思決定モードがあることが示されています。それは、高速で自動的な無意識モード「システム 1」と、ゆっくりとした意図的な意識モードです。 「システム2」。
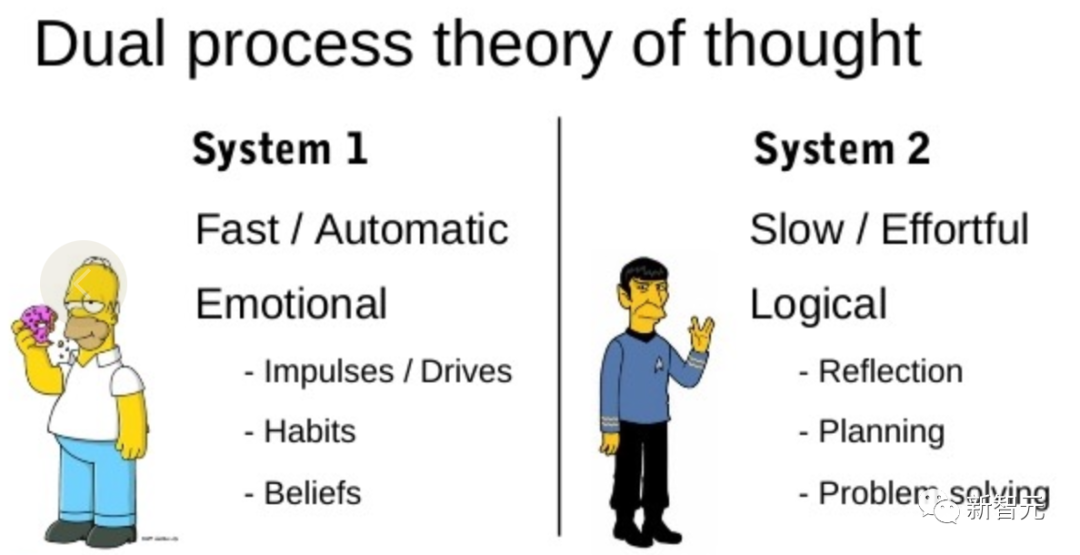
「システム 1」では、LLM が現在の選択を 1 つだけ選択するのではなく、複数の選択肢を維持および探索できるようにします。一方、「システム 2」では、現在のステータスを評価し、積極的に先を見て振り返ります。より総合的な意思決定を行うために。
このような計画プロセスを設計するために、研究者たちは、1950 年代に科学者ニューウェル、ショー、サイモンによって探求された計画プロセスから始めて、人工知能と認知科学の起源をたどりました。 . からインスピレーションを得ます。
Newellらは、問題解決をツリーとして表現された「問題空間を組み合わせることによる検索」であると説明しています。
問題を解決するプロセスでは、最終的に解決策が見つかるまで、既存の情報を使用して探索を繰り返し、より多くの情報を取得する必要があります。 
この観点からは、LLM を使用して一般的な問題を解決する既存の方法の 2 つの主な欠点が強調されます。
##1. ローカルでは、LLM は思考プロセスのさまざまな継続、つまりツリーの枝を探索しません。2. 全体として、LLM には、これらのさまざまなオプションを評価するために役立つ、将来を見据えた計画や過去を振り返るような計画は含まれていません。
これらの問題を解決するために、研究者らは言語モデルを使用して一般的な問題を解決する思考ツリー フレームワーク (ToT) を提案し、LLM が複数の思考推論パスを探索できるようにしました。
ToT 4 ステップ法
現在、IO、CoT、CoT-SC などの既存の方法は、連続した言語シーケンスをサンプリングすることで問題を解決します。そして、ToT は「思考ツリー」を積極的に維持しています。それぞれの長方形のボックスは思考を表しており、それぞれの思考は問題を解決するための中間ステップとして機能する一貫した言語シーケンスです。
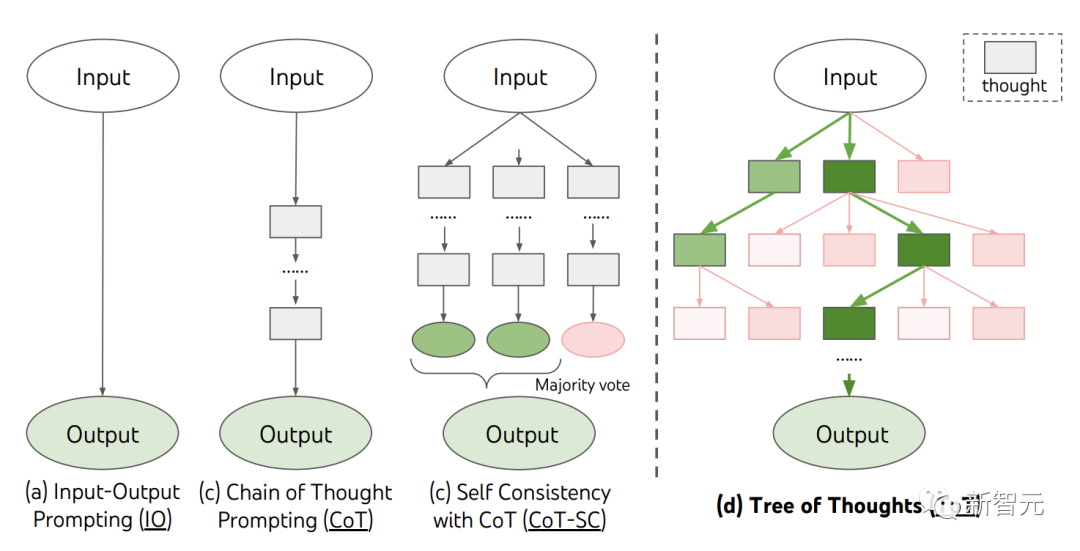
ToT は、特定のタスクを実行するときに 4 つの質問に答える必要があります:
中間プロセスを思考ステップに分解する方法、どのように開始するか各状態 潜在的なアイデアを生成する、状態をヒューリスティックに評価する方法、使用する検索アルゴリズム。
#1. 思考の内訳CoT が明確ではない分解には思考の一貫したサンプリングが含まれますが、ToT では問題の特性を使用して中間の思考ステップを設計および分解します。
問題に応じて、アイデアはいくつかの単語 (クロスワード パズル)、方程式 (24 ポイント)、または執筆計画全体 (クリエイティブ ライティング) になります。
一般的に、LLM が有意義で多様なサンプルを生成できるように、アイデアは十分に「小さい」必要があります。たとえば、完全な本を作成すると、一貫性を持たせるには「大きすぎる」ことがよくあります。
しかし、アイデアは、LLM が問題解決の見通しを評価するのに十分な「大きな」ものでなければなりません。たとえば、トークンの生成は評価するには「小さすぎる」ことがよくあります。
#2. 思考ジェネレーター
与えられたツリーの状態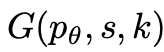
、2 つの戦略を使用して、次の思考ステップの k 個の候補を生成します。 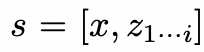 (a) CoT プロンプトからのサンプリング
(a) CoT プロンプトからのサンプリング
思考: 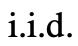
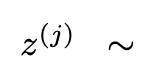
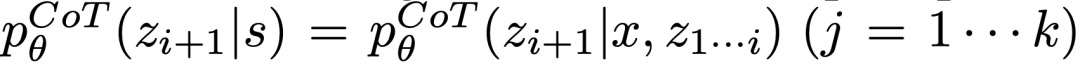
# は思考スペースが豊富 (各アイデアが段落であるなど)、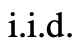 多様性につながると効果はさらに高まります。
多様性につながると効果はさらに高まります。
(b) 「提案プロンプト」を使用して、次の順序でアイデアを提案します。これは、思考スペースが限られている場合 (たとえば、それぞれの考えが 1 つの単語または行だけである場合) に有効に機能するため、同じコンテキストで異なるアイデアを提示することで重複を避けることができます。 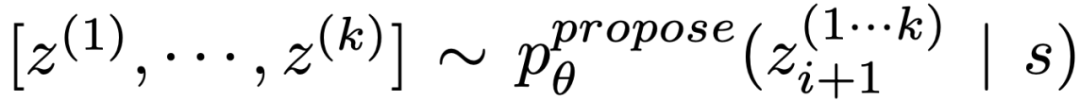
#3. 状態評価器
さまざまな状態のフロンティアが与えられると、状態評価器は問題解決の進捗状況を評価し、どの状態をどの順序で探索し続ける必要があるかを判断するための検索アルゴリズムのヒューリスティックとして機能します。
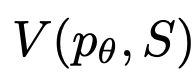
該当する場合、このような思慮深いヒューリスティックは、手順ルールよりも柔軟であり、学習モデルよりも効率的です。研究者らは、Think Generator を使用して、州を個別にまたは一緒に評価するための 2 つの戦略、つまり各州に個別に値を割り当てる方法と、州全体で投票する方法についても検討しました。
#4. 検索アルゴリズム
最後に、ToT でフレームワーク内では、ツリー構造に基づいてさまざまな検索アルゴリズムをプラグアンドプレイできます。 研究者らは、ここで 2 つの比較的単純な検索アルゴリズムを検討しました:
アルゴリズム 1 - 幅優先検索 (BFS)、それぞれが最も有望な状態を維持します。 bのセットをワンステップで。
アルゴリズム 2 - 深さ優先検索 (DFS)。最初に、最終出力に到達するまで、または状態評価者が現在のしきい値の質問から解決することが不可能と判断するまで、最も有望な状態を探索します。どちらの場合も、DFS は s の親状態に戻って探索を続行します。
上記のことから、自己評価と意識的な意思決定を通じてヒューリスティック検索を実装する LLM の方法は斬新です。
実験
24 ポイント (24 人制ゲーム)
24 ポイントは数学です4 つの数字と基本的な算術演算 (-*/) を使用して 24 を得ることが目的の推理ゲームです。 
たとえば、入力が「4 9 10 13」の場合、答えの出力は「(10-4)*(13-9)=24」になる可能性があります。
ToT Setup
チームはモデルの思考プロセスを 3 つのステップに分割しました。各ステップは中間方程式。
図 2(a) に示すように、各ノードで「左側」の番号を抽出し、考えられる次のステップを生成するように LLM に指示します。 (各ステップで与えられる「提案プロンプト」は同じです)
その中で、チームは ToT で幅優先検索 (BFS) を実行し、各ステップで最良の b= を保持します。 . 候補者は5人。
図 2(b) に示すように、LLM は各思考候補を「間違いなく/おそらく/不可能」として最大 24 段階で評価するように求められます。 「大きすぎる・小さすぎる」という常識に基づいて不可能な部分解を排除し、残った「可能な」項目を残します。
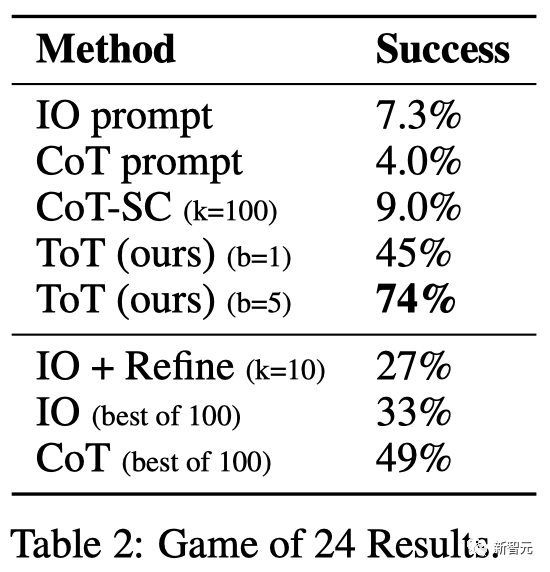
結果を表に示します。 2 IO、CoT、CoT-SC のプロンプト手法はタスクのパフォーマンスが低く、成功率はわずか 7.3%、4.0%、9.0% であることが示されました。比較すると、ToT は幅が b=1 の場合に 45%、b=5 の場合に 74% の成功率を達成しました。
チームは、成功率を計算するために最良の k 個のサンプル (1≤k≤100) を使用して IO/CoT の予測設定を検討し、それを図 3(a) に示しました。 5 つの成功率がプロットされます。予想通り、CoT は IO よりもスケーリングが良く、最良の 100 CoT サンプルでは 49% の成功率を達成しましたが、依然として ToT よりも多くのノードを探索しています (b>1)。 。
#エラー分析
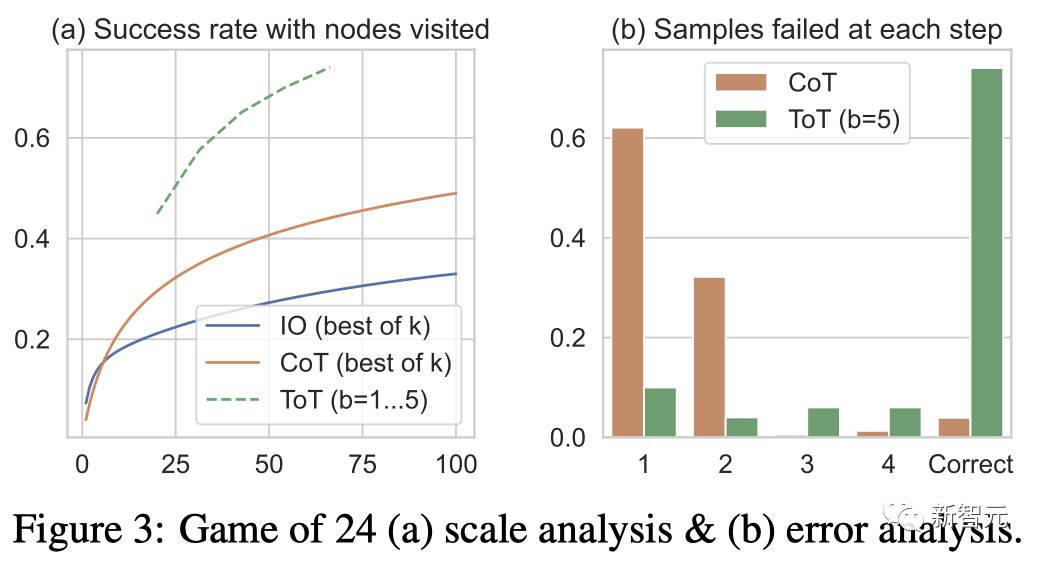
図 3( b) CoT および ToT サンプルがどのステップでタスクに失敗したかを分析しました。つまり、思考 (CoT) またはすべての思考 (ToT) が無効であるか、24 に到達できませんでした。 CoT サンプルの約 60% が最初のステップ、つまり最初の 3 つの単語 (「4 9」など) で失敗していることは注目に値します。
クリエイティブ ライティング
次に、チームはクリエイティブ ライティングのタスクを設計しました。
入力は 4 つのランダムな文であり、出力は一貫した段落である必要があります。各段落はそれぞれ 4 つの入力文で終わります。このようなタスクは、自由で探索的なものであり、創造的思考と高度な計画に挑戦するものです。
チームが各タスクのランダム IO サンプルに対して反復最適化 (k≤5) メソッドも使用していることは注目に値します。このメソッドでは、LLM は入力制約と最後の制約に基づいています。生成された段落。段落が「完全に一貫性がある」かどうかを判断し、そうでない場合は、最適化された段落を生成します。
#ToT 設定
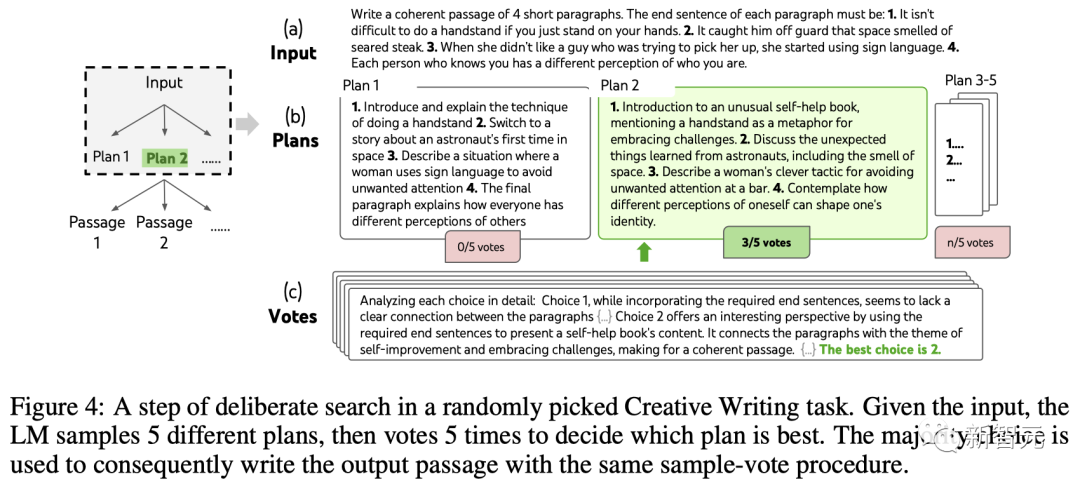
LLM は、最初に k=5 の計画を生成し、投票して最良の計画を選択します (図 4)。次に、最良の計画に基づいて k=5 の段落を生成し、投票して最良の計画を選択します。一つ一つ。
単純なゼロショット投票プロンプト (「次の選択肢を分析し、ディレクティブを実装する可能性が最も高いものを決定してください」) を使用して、2 つのステップで 5 票を集めます。
#結果
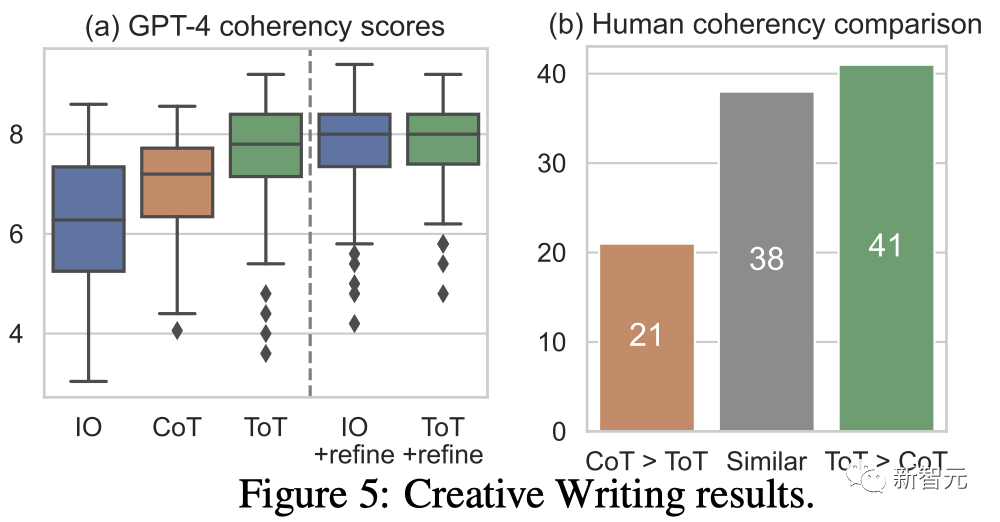
図 5(a) は 100 個のタスク GPT を示しています。の 4 平均スコア。ToT (7.56) は、IO (6.19) や CoT (6.93) よりも平均してより一貫した段落を生成すると考えられます。
このような自動評価にはノイズが含まれる可能性がありますが、図 5(b) は、人間が 100 段落ペアのうち 41 個の段落ペアに対して ToT を好み、CoT に対しては 21 個だけを好むことを示してこれを示しています (他の 38 個のペア)は「同様に一貫性がある」と考えられました)、この発見を裏付けるために。
最後に、この自然言語タスクでは反復最適化がより効果的です。IO コヒーレンス スコアが 6.19 から 7.67 に、ToT コヒーレンス スコアが 7.56 から 7.91 に改善されました。
チームは、これが ToT フレームワークの下で思考を生成する 3 番目の方法であると考えています。新しい思考は、i.i.d. や逐次生成ではなく、古い思考を最適化することで生成できます。
ミニ クロスワード パズル
24 ポイントのゲームやクリエイティブ ライティングでは、ToT は比較的浅く、理解するには最大 3 つの思考ステップが必要です。それを解くと出力が完了します。
最後に、チームは 5×5 のミニ クロスワード パズルを通じて、より難しい問題を設定することにしました。
繰り返しますが、目標は単にタスクを解決することではなく、一般的な問題解決ツールとしての LLM の限界を研究することです。自分の心を見つめ、目的を持った推論をインスピレーションとして使用して、探索を進めてください。
#ToT セットアップ
チームの活用度の深さ優先順位付き検索では、その状態が有望でなくなるまで、成功する可能性が最も高い後続の単語の手がかりを探索し続け、その後、親状態に戻って別のアイデアを探索します。検索を実行可能にするために、その後の思考では埋められた単語や文字の変更が制限されるため、ToT には最大 10 の中間ステップが含まれます。
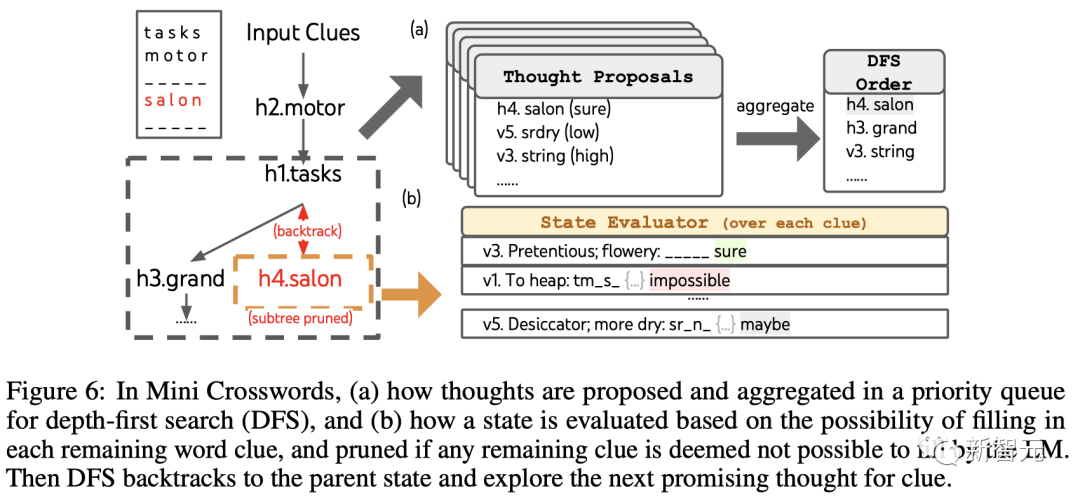
思考生成の場合、チームは各状態の既存の思考をすべて生成します (たとえば、図 6(a) の状態では「h2.motor; h1.tasks」)。残りの手がかりの文字制限 (例: "v1.To heap: tm___;...") を取得し、次の単語の位置と内容を埋めるための候補を取得します。
重要なのは、チームはまた、LLM にさまざまなアイデアの信頼レベルを与えるよう促し、これらを提案に集約して、次に検討するアイデアのランク付けされたリストを取得することです (図 6(a) )。 )。
ステータス評価の場合、チームは同様に各ステータスを残りのリードの文字数制限に変換し、指定された制限内で満たされる可能性が高いかどうかについて各リードを評価します。
残りの手がかりが「不可能」であるとみなされる場合 (例: 「v1. ヒープへ: tm_s_」)、その状態のサブツリーの探索はプルーニングされ、DFS はバックトラックして次の状態に戻ります。その親ノードを調べて、次の候補を探索します。
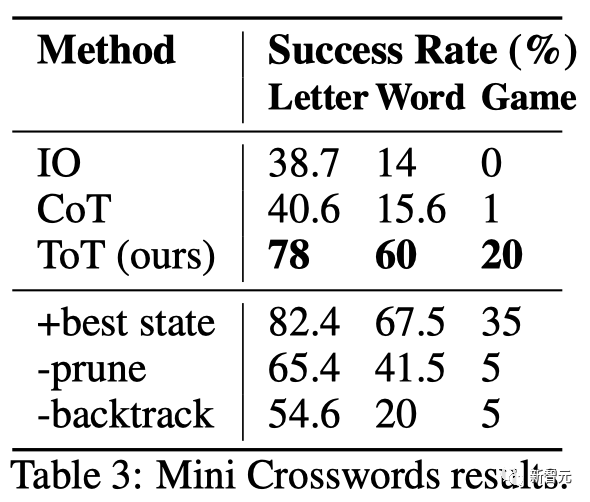
IO と CoT には、さまざまな手がかりを試したり、決定を変更したり、後戻りしたりするメカニズムがないことを考えると、この改善は驚くべきことではありません。
制限と結論
ToT は、LLM が意思決定を行い、より自律的かつインテリジェントに問題を解決できるようにするフレームワークです。
ToT によって生成される表現は、暗黙的な低レベル言語推論ではなく、可読な高水準言語推論の形式であるため、モデルの決定の解釈可能性と人間との調整の可能性が向上します。レベルトークンの値。
ToT は、GPT-4 がすでに得意とするタスクには必要ないかもしれません。
さらに、ToT のような検索方法では、タスクのパフォーマンスを向上させるためにより多くのリソース (GPT-4 API コストなど) が必要ですが、ToT のモジュール式の柔軟性により、ユーザーはこのパフォーマンスとコストのバランスをカスタマイズできます。
ただし、LLM はより現実世界の意思決定アプリケーション (プログラミング、データ分析、ロボティクスなど) で使用されるため、ToT はより多くのことを研究するための基礎を提供できます。今後の複雑な問題や課題を解決し、新たな機会を提供します。
著者紹介
姚顺雨(ヤオシュンユウ)

#この論文の筆頭著者、姚俊宇氏はプリンストン大学博士課程 4 年生で、以前は清華大学の姚クラスを卒業しています。
彼の研究の方向性は、言葉遊び (CALM)、オンライン ショッピング (WebShop)、推論のための Wikipedia の閲覧 (ReAct) など、言語エージェントと世界の間のインタラクションを確立することです。または、同じ考えに基づいて、任意のツールを使用して任意のタスクを実行します。
人生では、読書、バスケットボール、ビリヤード、旅行、ラップを楽しんでいます。
#Dian Yu

彼の研究関心は、言語のプロパティ表現と多言語およびマルチモーダルの理解にあり、主に会話研究 (オープン ドメインとタスク指向の両方) に焦点を当てています。
Yuan Cao
#Yuan Cao は、Google DeepMind の研究科学者でもあります。以前は、上海交通大学で学士号と修士号を取得し、ジョンズ ホプキンス大学で博士号を取得しました。彼は Baidu の主任アーキテクトも務めました。#Jeffrey Zhao
 ##Jeffrey Zhao はソフトウェアですGoogle DeepMind のエンジニア。以前はカーネギーメロン大学で学士号と修士号を取得していました。
##Jeffrey Zhao はソフトウェアですGoogle DeepMind のエンジニア。以前はカーネギーメロン大学で学士号と修士号を取得していました。
以上がGPT-4 推論は 1750% 向上しました。プリンストン清華ヤオクラスの卒業生が、LLM が繰り返し考えることを可能にする新しい「Thinking Tree ToT」フレームワークを提案の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。