
ホームページ >データベース >mysql チュートリアル >MySQL InnoDB の MVCC 原則とは何ですか?
MySQL InnoDB の MVCC 原則とは何ですか?

- 王林転載
- 2023-05-30 13:20:54796ブラウズ

MVCC の正式名は Multi-Version Concurrency Control で、主にデータベースの同時実行パフォーマンスを向上させるためのマルチバージョン同時実行制御です。同じデータ行に対して読み取りまたは書き込みリクエストが発生すると、そのリクエストはロックされブロックされます。 MVCC は、より最適化された方法を使用して読み取りおよび書き込みリクエストを処理し、ロックせずに読み取りおよび書き込みリクエストの競合を処理できます。これは、悲観的なロック メカニズムである現在の読み取りではなく、スナップショットの読み取りを指します。以下の研究では、ロックを行わずに読み取りおよび書き込み操作を実行する方法を学び、スナップショット読み取りと現在の読み取りの概念も分析します。
MySQL は、REPEATABLE READ 分離レベルでファントム リードの問題を大幅に回避できます。MySQL はどのようにこれを行うのでしょうか?
バージョン チェーン
InnoDB ストレージ エンジンを使用するテーブルの場合、そのクラスター化インデックス レコードには 2 つの必要な隠し列 (row_id は必要ありません。row_id 列) が含まれることがわかっています。作成するテーブルに主キーまたは NULL 以外の UNIQUE キーがある場合は含まれません):
trx_id: トランザクションが特定のクラスターになるたびに、インデックス レコードが変更されると、トランザクションのトランザクション ID は、trx_id 非表示列に割り当てられます。
roll_pointer: クラスター化インデックス レコードが変更されるたびに、古いバージョンが元に戻すログに書き込まれ、この非表示の列はポインターに相当します。レコードが変更される前の情報。
この問題を説明するために、デモ テーブルを作成します:
CREATE TABLE `teacher` ( `number` int(11) NOT NULL, `name` varchar(100) DEFAULT NULL, `domain` varchar(100) DEFAULT NULL, PRIMARY KEY (`number`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
次に、このテーブルにデータを挿入します:
mysql> insert into teacher values(1, 'J', 'Java');Query OK, 1 row affected (0.01 sec)
現在のデータ これです。
mysql> select * from teacher; +--------+------+--------+ | number | name | domain | +--------+------+--------+ | 1 | J | Java | +--------+------+--------+ 1 row in set (0.00 sec)
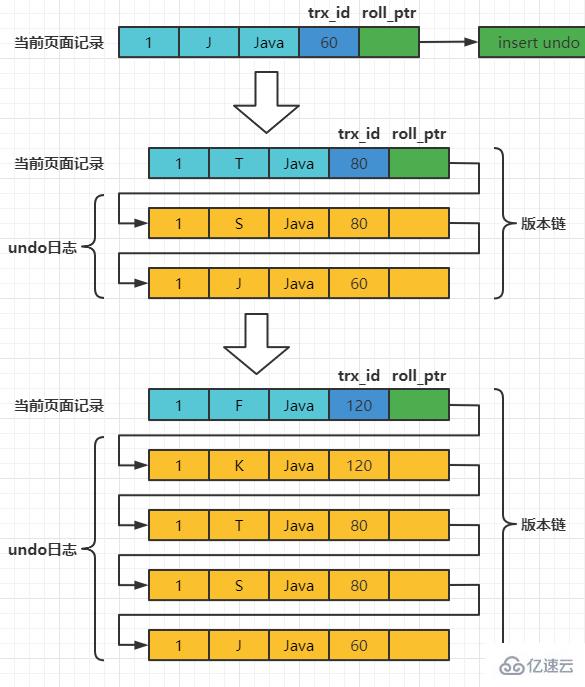
レコードを挿入するトランザクション ID が 60 であるとすると、この時点のレコードの図は次のとおりです。

トランザクション ID が 80 と 120 の次の 2 つの A トランザクションがこのレコードに対して UPDATE 操作を実行するとします。操作プロセスは次のとおりです:
| Trx80 | Trx120 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 開始 | ||||||||||||||
| ##commit | ||||||||||||||
|
每次对记录进行改动,都会记录一条undo日志,每条undo日志也都有一个roll_pointer属性(INSERT操作对应的undo日志没有该属性,因为该记录并没有更早的版本),可以将这些undo日志都连起来,串成一个链表,所以现在的情况就像下图一样:
对该记录每次更新后,都会将旧值放到一条undo日志中,就算是该记录的一个旧版本,随着更新次数的增多,所有的版本都会被roll_pointer属性连接成一个链表,我们把这个链表称之为版本链,版本链的头节点就是当前记录最新的值。另外,每个版本中还包含生成该版本时对应的事务id。于是可以利用这个记录的版本链来控制并发事务访问相同记录的行为,那么这种机制就被称之为多版本并发控制(Mulit-Version Concurrency Control MVCC)。 ReadView对于使用READ UNCOMMITTED隔离级别的事务来说,由于可以读到未提交事务修改过的记录,所以直接读取记录的最新版本就好了。 对于使用SERIALIZABLE隔离级别的事务来说,InnoDB使用加锁的方式来访问记录。 对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的,核心问题就是:READ COMMITTED和REPEATABLE READ隔离级别在不可重复读和幻读上的区别,这两种隔离级别关键是需要判断一下版本链中的哪个版本是当前事务可见的。 为此,InnoDB提出了一个ReadView的概念,这个ReadView中主要包含4个比较重要的内容:
有了这个ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见:
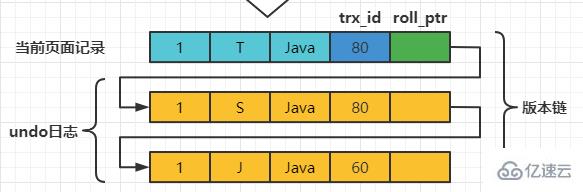
在MySQL中,READ COMMITTED和REPEATABLE READ隔离级别的的一个非常大的区别就是它们生成ReadView的时机不同。 我们还是以表teacher为例,假设现在表teacher中只有一条由事务id为60的事务插入的一条记录,接下来看一下READ COMMITTED和REPEATABLE READ所谓的生成ReadView的时机不同到底不同在哪里。 READ COMMITTED每次读取数据前都生成一个ReadView假设现在系统里有两个事务id分别为80、120的事务在执行: # Transaction 80 set session transaction isolation level read committed; begin update teacher set name='S' where number=1; update teacher set name='T' where number=1; 此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用READ COMMITTED隔离级别的事务开始执行: set session transaction isolation level read committed; # 使用READ COMMITTED隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' 这个SELECE1的执行过程如下:
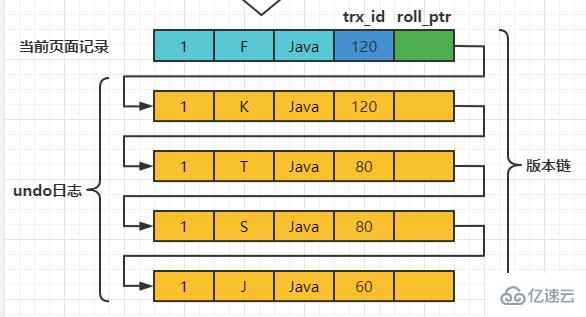
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录: set session transaction isolation level read committed; # Transaction 120 begin update teacher set name='K' where number=1; update teacher set name='F' where number=1; 此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用READ COMMITTED隔离级别的事务中继续查找这个number 为1的记录,如下: # 使用READ COMMITTED隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' # SELECE2:Transaction 80提交、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'T' 这个SELECE2 的执行过程如下:
以此类推,如果之后事务id为120的记录也提交了,再次在使用READCOMMITTED隔离级别的事务中查询表teacher中number值为1的记录时,得到的结果就是’F’了,具体流程我们就不分析了。 总结一下就是:使用READCOMMITTED隔离级别的事务在每次查询开始时都会生成一个独立的ReadView。 REPEATABLE READ —— 在第一次读取数据时生成一个ReadView对于使用REPEATABLE READ隔离级别的事务来说,只会在第一次执行查询语句时生成一个ReadView,之后的查询就不会重复生成了。我们还是用例子看一下是什么效果。 假设现在系统里有两个事务id分别为80、120的事务在执行: # Transaction 80 begin update teacher set name='S' where number=1; update teacher set name='T' where number=1; 此刻,表teacher中number为1的记录得到的版本链表如下所示:
假设现在有一个使用REPEATABLE READ隔离级别的事务开始执行: # 使用REPEATABLE READ隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' 这个SELECE1的执行过程如下(与READ COMMITTED的过程一致):
之后,我们把事务id为80的事务提交一下,然后再到事务id为120的事务中更新一下表teacher 中number为1的记录: # Transaction 80 begin update teacher set name='K' where number=1; update teacher set name='F' where number=1; 此刻,表teacher 中number为1的记录的版本链就长这样:
然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,如下: # 使用REPEATABLE READ隔离级别的事务 begin; # SELECE1:Transaction 80、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' # SELECE2:Transaction 80提交、120未提交 SELECT * FROM teacher WHERE number = 1; # 得到的列name的值为'J' 这个SELECE2的执行过程如下:
可重复读的意思是两次SELECT查询的结果相同,记录的列值均为'J'。 如果我们之后再把事务id为120的记录提交了,然后再到刚才使用REPEATABLE READ隔离级别的事务中继续查找这个number为1的记录,得到的结果还是’J’,具体执行过程大家可以自己分析一下。 MVCC下的幻读现象和幻读解决前面我们已经知道了,REPEATABLE READ隔离级别下MVCC可以解决不可重复读问题,那么幻读呢?MVCC是怎么解决的?幻读是一个事务按照某个相同条件多次读取记录时,后读取时读到了之前没有读到的记录,而这个记录来自另一个事务添加的新记录。 我们可以想想,在REPEATABLE READ隔离级别下的事务T1先根据某个搜索条件读取到多条记录,然后事务T2插入一条符合相应搜索条件的记录并提交,然后事务T1再根据相同搜索条件执行查询。结果会是什么?按照ReadView中的比较规则: 无论事务T2是否先于事务T1开启,事务T1都无法观察到T2的提交。请根据以上所述的版本历史、阅读视图与可视性判断规则,自行进行分析。 但是,在REPEATABLE READ隔离级别下InnoDB中的MVCC可以很大程度地避免幻读现象,而不是完全禁止幻读。怎么回事呢?我们来看下面的情况:
さて、何が起こっているのでしょうか?トランザクション T1 には明らかにファントム リード現象があります。 REPEATABLE READ 分離レベルでは、T1 は通常の SELECT ステートメントを初めて実行するときに ReadView を生成し、その後 T2 が新しいレコードを教師テーブルに挿入して送信します。 ReadView は、T1 が新しく挿入されたレコードを変更するために UPDATE または DELETE ステートメントを実行するのを防ぐことはできません (T2 がすでに送信されているため、レコードを変更してもブロックは発生しません)。ただし、この方法では、この新しいレコードの trx_id 非表示列の値がbe T1のトランザクションIDになります。その後、T1 は通常の SELECT ステートメントを使用してこのレコードをクエリするときにこのレコードを確認し、このレコードをクライアントに返すことができます。この特殊な現象が存在するため、MVCC ではファントムリードを完全に排除することはできません。 MVCC の概要上記の説明から、いわゆる MVCC (Multi-Version ConcurrencyControl、マルチバージョン同時実行制御) が READ COMMITTD と REPEATABLE READ の使用を指すことがわかります。この分離レベルのトランザクションは、通常の SELECT 操作の実行時に記録されたバージョン チェーンにアクセスするため、異なるトランザクションの読み取り/書き込みおよび書き込み/読み取り操作を同時に実行できるため、システムのパフォーマンスが向上します。 READ COMMITTD と REPEATABLE READ の 2 つの分離レベルの大きな違いは、ReadView を生成するタイミングが異なることです。READ COMMITTD は通常の SELECT 操作の前に ReadView を生成しますが、REPEATABLE READ は ReadView のみを生成します。通常の SELECT 操作の後に ReadView を生成してから通常の SELECT 操作を実行し、この ReadView を後続のクエリ操作で再利用するだけで、基本的にファントム読み取りの現象が回避されます。 主キーを更新する DELETE ステートメントまたは UPDATE ステートメントを実行しても、対応するレコードがページからすぐに完全に削除されるわけではなく、いわゆる削除マーク操作が実行されると前に述べました。レコードにマークを付けるだけと同じで、主に MVCC に使用されるフラグ ビットを削除します。また、いわゆる MVCC は、通常の SEELCT クエリを実行する場合にのみ有効になります。これまで見てきた SELECT ステートメントはすべて通常のクエリです。特殊なクエリとは何かについては、後ほど説明します。 |
以上がMySQL InnoDB の MVCC 原則とは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。