
ホームページ >データベース >mysql チュートリアル >Python を使用して数千万のデータを読み取り、それを MySQL データベースに自動的に書き込む方法
Python を使用して数千万のデータを読み取り、それを MySQL データベースに自動的に書き込む方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-30 11:55:281691ブラウズ
シナリオ 1: データを頻繁に mysql に書き込む必要はない
navicat ツールのインポート ウィザード機能を使用します。このソフトウェアはさまざまなファイル形式をサポートし、ファイル フィールドに基づいてテーブルを自動的に作成したり、既存のテーブルにデータを挿入したりできるため、非常に高速で便利です。
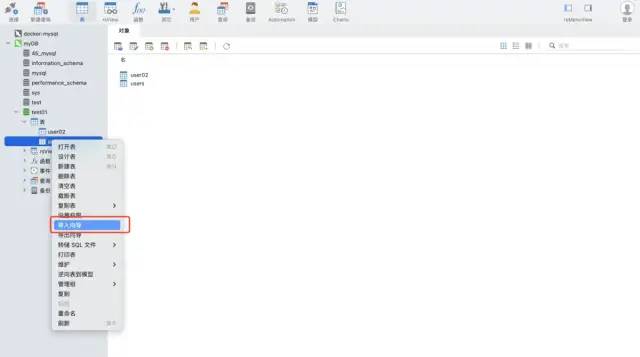
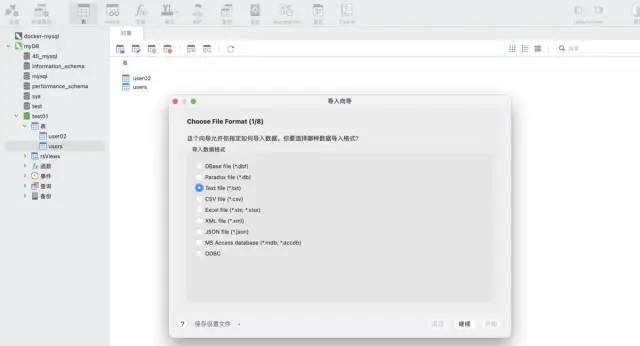
シナリオ 2: データは増分であるため、自動化して mysql
に頻繁に書き込む必要があります。テスト データ: csv 形式、約 1,200 万行
import pandas as pd data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.shape
印刷結果:

#方法 1:python ➕ pymysql ライブラリ
pymysql コマンドをインストールします:
pip install pymysql
コードの実装:
import pymysql
# 数据库连接信息
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='wangyuqing',
db='test01',
port = 3306,
charset="utf8")
# 分块处理
big_size = 100000
# 分块遍历写入到 mysql
with pd.read_csv('./tianchi_mobile_recommend_train_user.csv',chunksize=big_size) as reader:
for df in reader:
datas = []
print('处理:',len(df))
# print(df)
for i ,j in df.iterrows():
data = (j['user_id'],j['item_id'],j['behavior_type'],
j['item_category'],j['time'])
datas.append(data)
_values = ",".join(['%s', ] * 5)
sql = """insert into users(user_id,item_id,behavior_type
,item_category,time) values(%s)""" % _values
cursor = conn.cursor()
cursor.executemany(sql,datas)
conn.commit()
# 关闭服务
conn.close()
cursor.close()
print('存入成功!')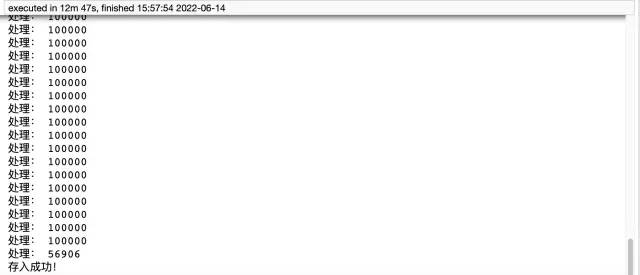
##方法 2: pandas ➕ sqlalchemy: pandas は SQL をサポートするために sqlalchemy を導入する必要があります。sqlalchemy のサポートにより、すべての一般的なデータベース タイプのクエリ、更新、その他の操作を実装できます。
コードの実装:
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:wangyuqing@localhost:3306/test01') data = pd.read_csv('./tianchi_mobile_recommend_train_user.csv') data.to_sql('user02',engine,chunksize=100000,index=None) print('存入成功!')概要 pymysql メソッドには 12 分 47 秒かかります。時間がかかり、コードの量も多くなります。は大きく、パンダ この要件を達成するのに必要なコードは 5 行だけで、所要時間はわずか約 4 分です。最後に、最初の方法では事前にテーブルを作成する必要がありますが、2 番目の方法ではその必要がないことを付け加えておきます。したがって、便利で効率的な 2 番目の方法を使用することをお勧めします。それでも遅いと感じる場合は、マルチプロセスとマルチスレッドの追加を検討してください。
MySQL データベースにデータを保存する 3 つの最も完全な方法:
- navicat のインポート ウィザード機能を使用した直接ストレージ
- Python pymysql
- Pandas sqlalchemy
以上がPython を使用して数千万のデータを読み取り、それを MySQL データベースに自動的に書き込む方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はyisu.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。
前の記事:MySQL で整数を使用する方法次の記事:MySQL で整数を使用する方法