
ホームページ >データベース >mysql チュートリアル >MySQL における分類ランキングと TOP N のグループ化の分析例
MySQL における分類ランキングと TOP N のグループ化の分析例

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-28 23:10:041883ブラウズ
テーブル構造
学生テーブルは次のとおりです:
CREATE TABLE `t_student` ( `id` int NOT NULL AUTO_INCREMENT, `t_id` int DEFAULT NULL COMMENT '学科id', `score` int DEFAULT NULL COMMENT '分数', PRIMARY KEY (`id`) );
データは次のとおりです:
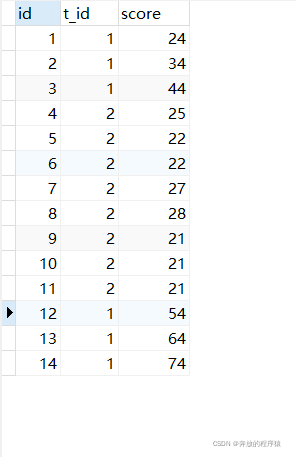
質問 1: 各科目の上位 5 点の順位を取得します (同点は許可されます)
同点の状況が存在する場合があります (4 位と 5 位が同点である場合など)。上位 4 つから 5 つのデータが取得されます。上位 5 つも 5 つのデータです。
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score GROUP BY s1.id HAVING COUNT( s2.id ) < 5 ORDER BY s1.t_id, s1.score DESC
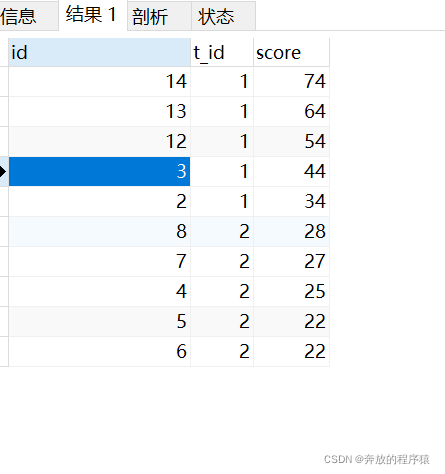
ps: 上位 4 位を獲得した場合
分析:
1. 自分自身left 外部結合は、左の値が右の値より小さいすべてのセットを取得します。 t_id=1 を例にとると、24 は彼より 5 スコア上 (74、64、54、44、34) で 6 位、34 は彼より 4 スコアだけ大きくて 5 位です... .74 はありません彼よりも大きくて、彼が最初です。
SELECT * FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score
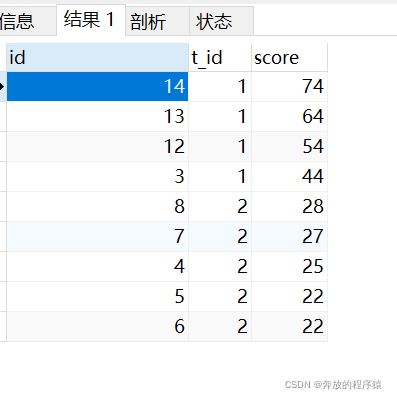
2. 要約されたルールを SQL に変換して表現し、各学生の ID (s1.id) でグループ化します。この ID の下にある人は彼より大きい値 (s2.id)
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score < s2.score GROUP BY s1.id HAVING COUNT( s2.id ) < 5
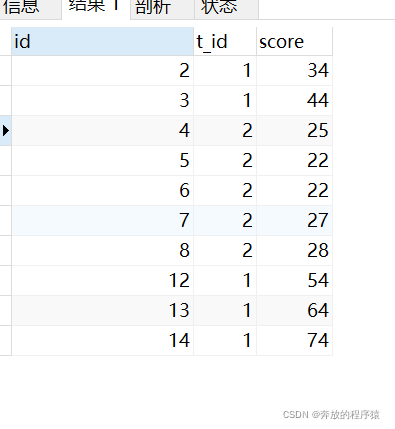
3. 最後に、t_id に従って分類し、スコアによって逆順に並べ替えます。
質問 2: 各科目の最後の 2 人の生徒の平均スコアを取得します。
最後の 2 人のスコアを取得します。
SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score GROUP BY s1.id HAVING COUNT( s1.id )< 2 ORDER BY s1.t_id, s1.score
並置が存在すると、同じものが除外される可能性があります。 t_id の結果の数は 2 より大きいですが、質問の要件は、最後の 2 つの結果の平均をとることです。複数の結果を平均しても、結果は同じであるため、これ以上処理する必要はありません。質問の要件。
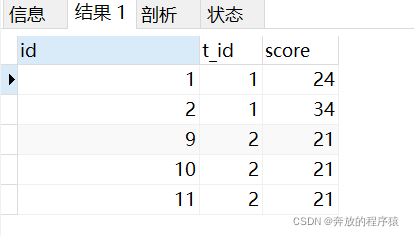
グループ平均:
SELECT t_id,AVG(score) FROM ( SELECT s1.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score GROUP BY s1.id HAVING COUNT( s1.id )< 2 ORDER BY s1.t_id, s1.score ) tt GROUP BY t_id
結果:
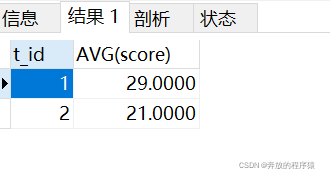
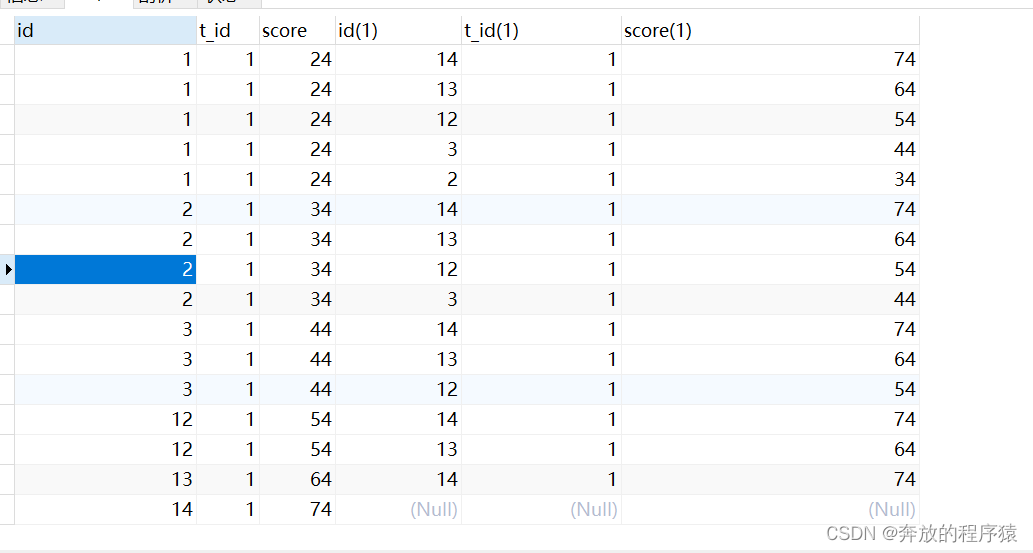
分析:
1. t1.score>t2.score
SELECT s1.*,s2.* FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score
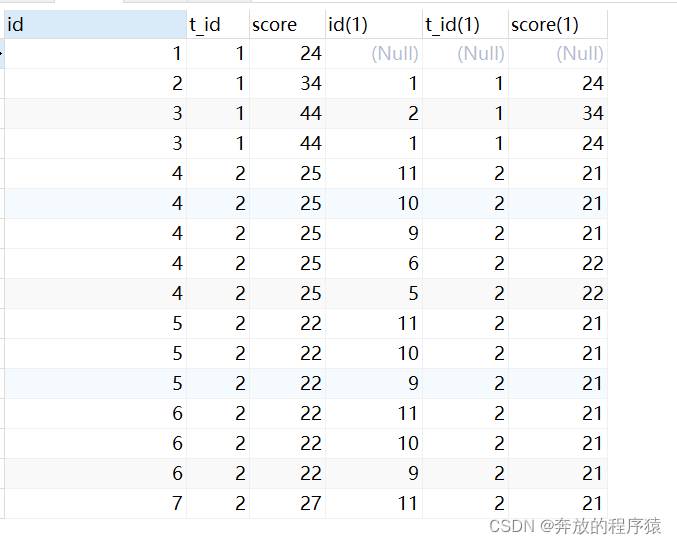
2 のすべてのレコードをクエリします。s.id でグループ化して重複を削除し、2 つのレコードを持ちます
3. t_id でグループ化する 各科目の結果を取得し、平均値を取得します。
質問 3: 各科目のスコア ランキングの上位 5 つを取得します (時間は許可されません)
SELECT * FROM ( SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it GROUP BY s1.id ORDER BY s1.t_id, s1.score DESC ) tt GROUP BY t_id, score, rownum HAVING COUNT( rownum )< 5
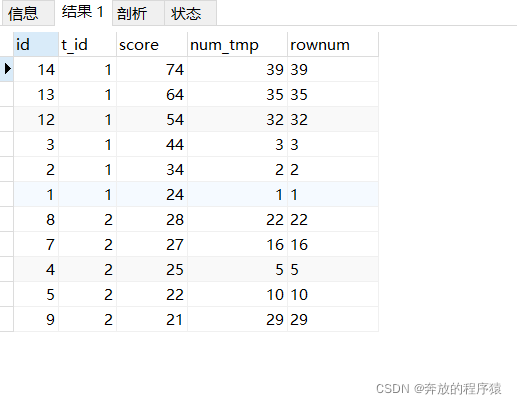
分析:
1. 補助パラメータの導入
SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it
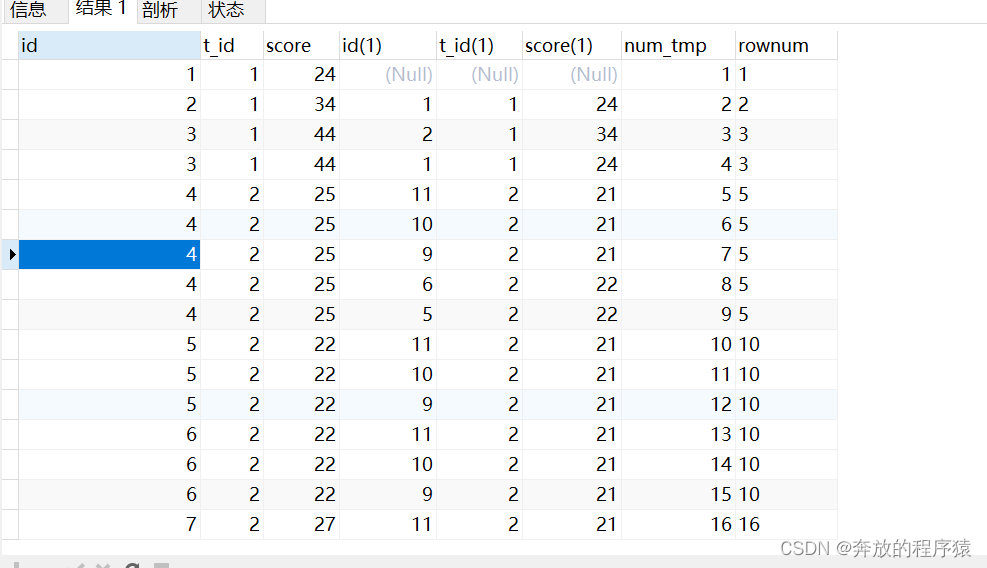
2. 重複した s1.id の削除、グループの並べ替え
SELECT s1.*, @rownum := @rownum + 1 AS num_tmp, @incrnum := CASE WHEN @rowtotal = s1.score THEN @incrnum WHEN @rowtotal := s1.score THEN @rownum END AS rownum FROM student s1 LEFT JOIN student s2 ON s1.t_id = s2.t_id AND s1.score > s2.score, ( SELECT @rownum := 0, @rowtotal := NULL, @incrnum := 0 ) AS it GROUP BY s1.id ORDER BY s1.t_id, s1.score DESC
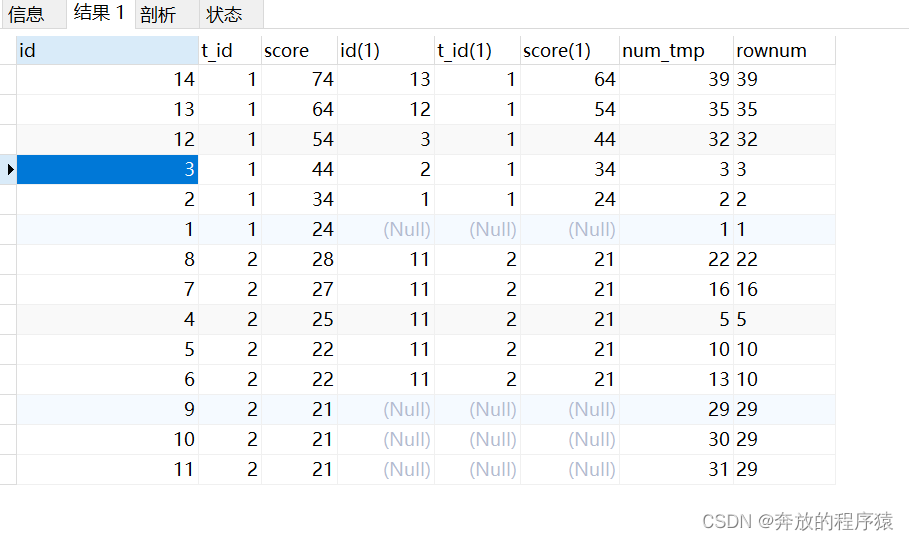
3.GROUP BY t_id、score、rownum その後、HAVING は最初の 5 つの一意の項目を取得します
以上がMySQL における分類ランキングと TOP N のグループ化の分析例の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。