
ホームページ >テクノロジー周辺機器 >AI >24 時間以内に、RLHF プロセスをコピーするのに 200 ドルを費やして、スタンフォード大学は「アルパカ ファーム」をオープンソース化しました。
24 時間以内に、RLHF プロセスをコピーするのに 200 ドルを費やして、スタンフォード大学は「アルパカ ファーム」をオープンソース化しました。

- 王林転載
- 2023-05-28 22:40:041200ブラウズ
2月末、Metaは、ChatGPTのMetaバージョンのプロトタイプと呼ばれる、パラメータが70億から650億の範囲にある大規模モデルシリーズLLaMA(直訳するとアルパカ)をオープンソース化した。その後、スタンフォード大学やカリフォルニア大学バークレー校などの機関がLLaMAに基づいた「二次イノベーション」を行い、AlpacaやVicunaなど複数のオープンソースの大型モデルを次々と発表し、一時は「Alpaca」がトップモデルとなりました。 AIサークルで。オープン ソース コミュニティによって構築されたこれらの ChatGPT に似たモデルは、非常に高速に反復され、高度にカスタマイズ可能であり、ChatGPT のオープン ソース代替モデルと呼ばれます。
ただし、ChatGPT がテキストの理解、生成、推論などで強力な機能を発揮できる理由は、OpenAI が ChatGPT などの大規模モデルに対して新しいトレーニング パラダイム RLHF を使用しているためです。人間のフィードバックからの強化学習)、強化学習を使用して人間のフィードバックに基づいて言語モデルを最適化します。 RLHF メソッドを使用すると、大規模な言語モデルを人間の好みに合わせて調整し、人間の意図に従い、役に立たない、歪んだ、または偏った出力を最小限に抑えることができます。ただし、RLHF 手法は大規模な手作業による注釈と評価に依存しており、人間によるフィードバックの収集には多くの場合数週間と数千ドルを要し、コストがかかります。
さて、オープンソース モデル Alpaca を立ち上げたスタンフォード大学は、別のシミュレーターである AlpacaFarm (直訳するとアルパカ農場) を提案しました。 AlpacaFarm は、わずか約 200 ドルで RLHF プロセスを 24 時間で複製できるため、オープンソース モデルで人間による評価結果を迅速に改善でき、これは RLHF と同等と言えます。

AlpacaFarm は、人間のフィードバックから学ぶ方法を迅速かつ安価に開発しようとしています。これを行うために、スタンフォード大学の研究チームはまず、RLHF 手法の研究における 3 つの主な問題点を特定しました。それは、人間の嗜好データのコストが高いこと、信頼できる評価の欠如、参照実装の欠如です。
これら 3 つの問題を解決するために、AlpacaFarm は、シミュレーション アノテーター、自動評価、SOTA メソッドの具体的な実装を構築しました。現在、AlpacaFarm プロジェクトのコードはオープンソースです。
- GitHub アドレス: https://github.com/tatsu-lab/alpaca_farm
- #論文アドレス: https://tatsu-lab.github.io/alpaca_farm_paper.pdf
以下の図に示すように、研究者は AlpacaFarm シミュレーターを使用して人間のフィードバック データから学習する新しい方法を迅速に開発でき、既存の SOTA メソッドを実際のシステムに移行することもできます。人間の好みのデータ。
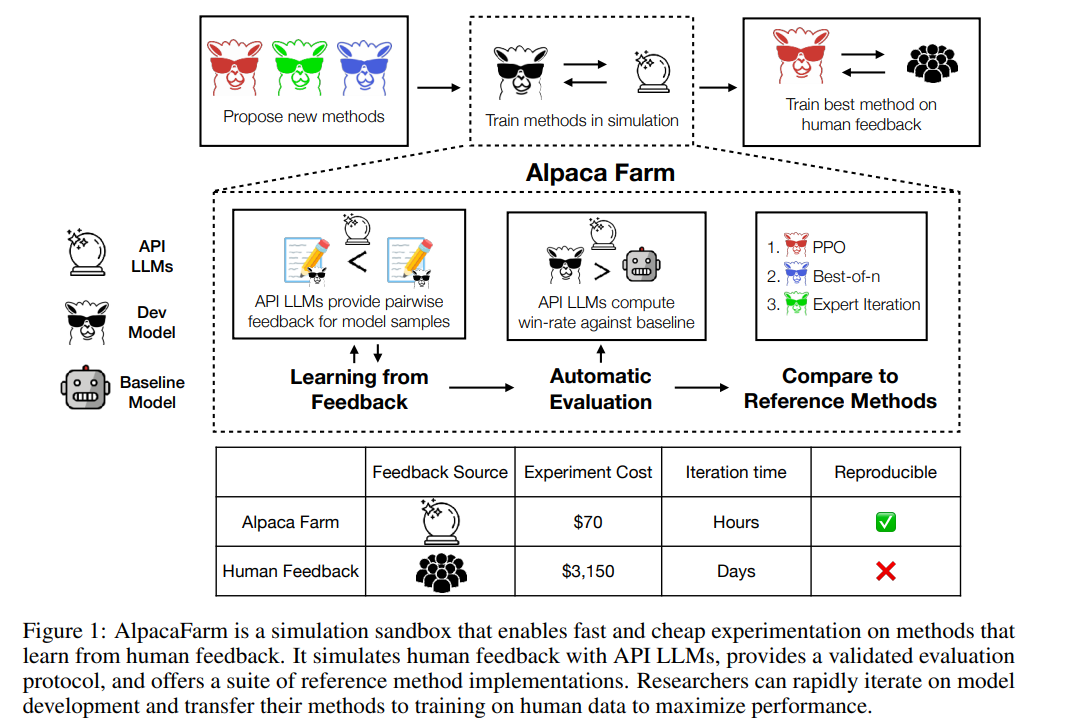
まず、アノテーションのコストを削減するために、この研究では API でアクセス可能な LLM (GPT-4、ChatGPT など) のプロンプトを作成し、AlpacaFarm が人間のフィードバックをシミュレートできるようにしました。収集されたデータの RLHF メソッド 1/45 のみ。この研究では、13 の異なるプロンプトを使用して、複数の LLM から人間の異なる好みを抽出する、ランダムでノイズの多いアノテーション スキームを設計しました。このアノテーション スキームは、品質の判断、アノテーター間のばらつき、スタイルの好みなど、人間によるフィードバックのさまざまな側面を捉えることを目的としています。
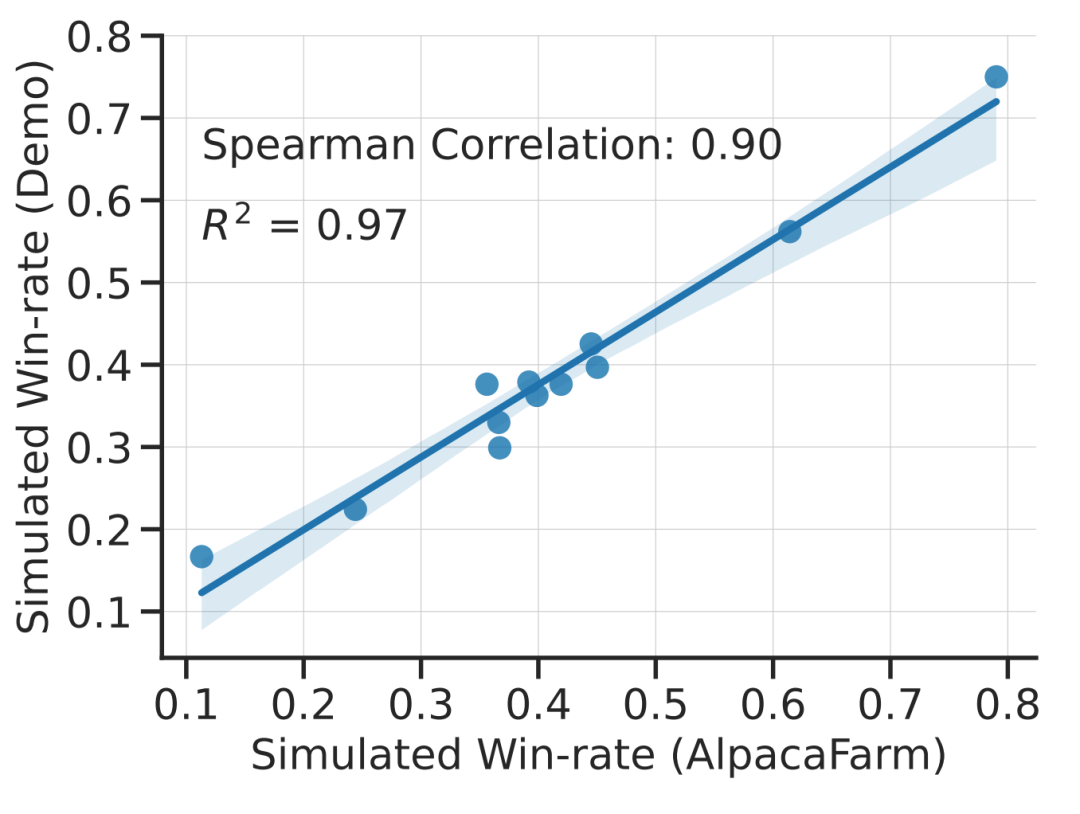
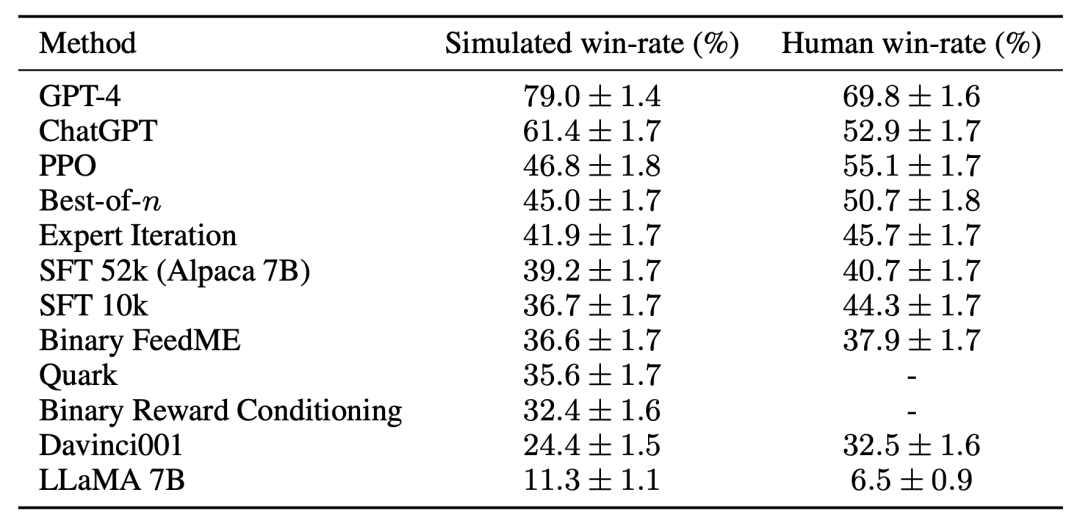
この研究は、AlpacaFarm のシミュレーションが正確であることを実験的に示しています。研究チームが AlpacaFarm を使用してメソッドをトレーニングおよび開発した場合、そのメソッドは、実際の人間のフィードバックを使用してトレーニングおよび開発された同じメソッドと非常に一貫してランク付けされました。以下の図は、AlpacaFarm シミュレーション ワークフローとヒューマン フィードバック ワークフローから得られたメソッド間のランキングにおける高い相関関係を示しています。この特性は、シミュレーションから導かれた実験的結論が実際の状況でも当てはまる可能性が高いことを示すため、非常に重要です。 AlpacaFarm シミュレーターは、メソッドレベルの相関関係に加えて、報酬モデルの過剰最適化などの定性的な現象も再現できますが、代理報酬に対する継続的な RLHF トレーニングはモデルのパフォーマンスにダメージを与える可能性があります。次の図は、この現象を人間によるフィードバック (左) と AlpacaFarm (右) の 2 つのケースで示しています。AlpacaFarm は最初はモデルのパフォーマンス向上の正しい決定論的な動作を捕捉していましたが、その後、RLHF トレーニングが継続するにつれてモデルのパフォーマンスが低下したことがわかります。 評価のために、研究チームはアルパカ 7B 本物を使用しました。ユーザー インタラクションの時間をガイドとして利用し、自己指示データセット、人類的有用性データセット、Open Assistant、Koala、Vicuna の評価セットなど、いくつかの既存の公開データセットを組み合わせて指示分布をシミュレートします。研究では、これらの評価手順を使用して、RLHF モデルの応答を Davinci003 モデルと比較し、スコアを使用して RLHF モデルの応答が優れた回数を測定し、このスコアを勝率と呼びました。以下の図に示すように、調査の評価データに基づいてシステム ランキングを定量的に評価すると、システム ランキングとリアルタイム ユーザー コマンドには高い相関があることがわかります。この結果は、既存の公開データを集約することで、単純な実際の命令と同様のパフォーマンスを達成できることを示しています。
これらの結果は、PPO アルゴリズムがモデルの勝率を最適化するのに非常に効果的であることを示しています。これらの結果は、この研究の評価データとアノテーターに固有のものであることに注意することが重要です。研究の評価指示はリアルタイムのユーザー指示を表していますが、より困難な問題をカバーしていない可能性があり、事実や正確さではなくスタイルの好みを活用することで勝率がどの程度向上するかは定かではありません。たとえば、調査では、以下に示すように、PPO モデルははるかに長い出力を生成し、多くの場合、回答についてより詳細な説明を提供することがわかりました。
## 全体的に、AlpacaFarm を使用してシミュレートされた設定に基づいてモデルをトレーニングすると、モデルを再トレーニングすることなく、モデルの人による評価結果を大幅に向上させることができます。人間の好み。ただし、この移行プロセスは脆弱であり、人間の嗜好データに基づいてモデルを再トレーニングするよりも効果がわずかに劣ります。ただし、わずか 200 ドルで 24 時間以内に RLHF パイプラインをコピーできるため、モデルが人間の評価パフォーマンスを迅速に向上させることができます。シミュレータ AlpacaFarm は依然として優れています。これは、オープン ソース コミュニティによって作成され、次のようなモデルの強力な機能を複製します。 ChatGPT 別の取り組み。 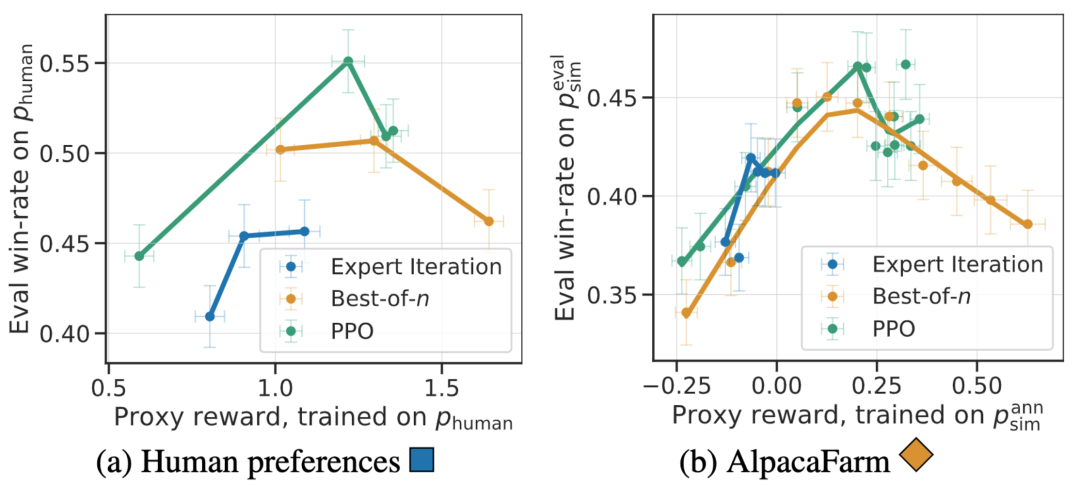

以上が24 時間以内に、RLHF プロセスをコピーするのに 200 ドルを費やして、スタンフォード大学は「アルパカ ファーム」をオープンソース化しました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。