
ホームページ >データベース >mysql チュートリアル >MySQL で文字列フィールドにインデックスを付ける方法
MySQL で文字列フィールドにインデックスを付ける方法

- 王林転載
- 2023-05-28 14:38:522622ブラウズ
現在、電子メール ログインをサポートするシステムを管理しているとします。ユーザー テーブルは次のように定義されています:
create table SUser( ID bigint unsigned primary key, email varchar(64), ... )engine=innodb;
ログインに電子メールを使用する必要があるため、これと同様のステートメントがビジネス コードに記述される必要があります。 :
select f1, f2 from SUser where email='xxx';
電子メール フィールドにインデックスがない場合、このステートメントはテーブル全体のスキャンのみを実行できます。
1) 電子メール アドレス フィールドにインデックスを作成できますか?
- #MySQL はプレフィックス インデックスをサポートしているため、文字列の一部をインデックスとして定義できます
2)インデックスを作成する ステートメントでプレフィックス長が指定されていない場合はどうなりますか?
- インデックスには文字列全体が含まれます
3) 例を教えてください。
alter table SUser add index index1(email); 或 alter table SUser add index index2(email(6));
- index1 インデックスには、各レコードの文字列全体が含まれます
- index2 インデックスには、各レコードに対して最初の 6 バイトを取る
#4) データ構造とストレージにおけるこれら 2 つの異なる定義の違いは何ですか?
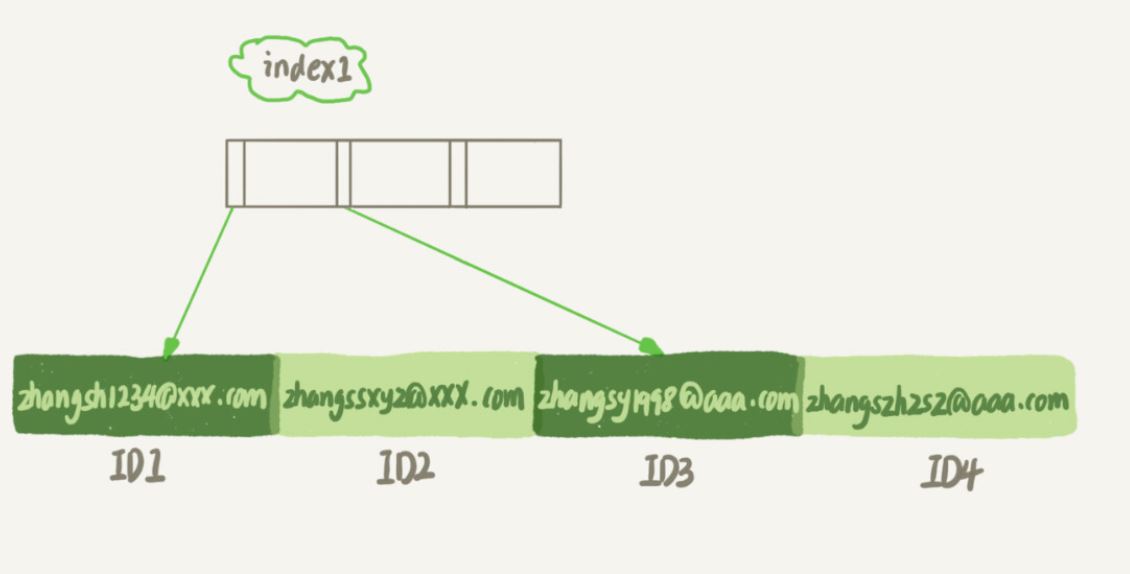
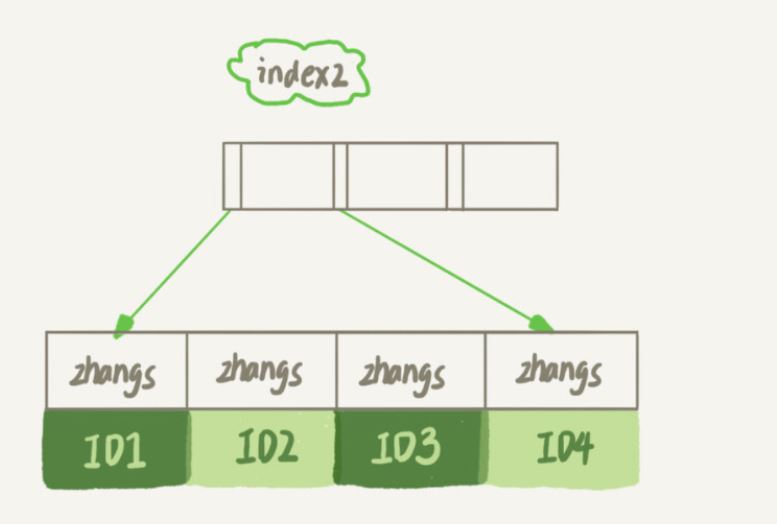 #email(6) インデックス構造が占めるスペースが少なくなるのは明らかです
#email(6) インデックス構造が占めるスペースが少なくなるのは明らかです
#5) 電子メール(6) このインデックス構造には欠点はありますか?
追加のレコード スキャンの数が増える可能性があります
- 6) 次のステートメントはこれら 2 つのインデックスで定義されています。以下は実装されていますか?
select id,name,email from SUser where email='zhangssxyz@xxx.com';index1 (つまり、メール文字列全体のインデックス構造)、実行順序 からインデックス値を満たすインデックス値を見つけます。 Index1 インデックス ツリーは ’zhangssxyz@xxx です。.com のこのレコードについては、ID2 の値を取得します。
- テーブルに戻り、主キー値が次の行を見つけます。 ID2、電子メールの値が正しいと判断し、この行のレコードを追加します。 結果セット;
- インデックス インデックス ツリーの次のレコードに進み、電子メールの条件が一致していることを確認します。 ='zhangssxyz@xxx.com' が満たされなくなり、ループが終了します。
- このプロセスでは、主キー インデックスからデータを 1 回取得するだけでよいため、システムは 1 行だけがスキャンされたと認識します。
- 主キーに移動し、主キーの値が ID1 である行を検索すると、メールの値は「zhangssxyz@xxx. com" とすると、この行のレコードは破棄されます。
- index2 で見つかった位置にある次のレコードを取得すると、それがまだ「zhangs」であることがわかります。ID2 を取り出し、次にID インデックスの行全体を取得し、今回は値を判断します。ちなみに、このレコード行を結果セットに追加します。
- 取得した値が得られるまで、前の手順を繰り返します。 idxe2 は「zhangs」ではないため、ループは終了します。
- このプロセスでは、主キー インデックスを 4 回取得する必要があります。つまり、4 行がスキャンされます。
7) 上記の比較からどのような結論が得られますか?
#プレフィックス インデックスを使用すると、クエリ ステートメントによるデータの読み取り回数が増える可能性があります。
- #8) 接頭辞インデックスは本当に役に立たないのでしょうか?
定義するインデックス 2 が email(6) ではなく email(7) の場合、プレフィックス ’zhangss’ を満たすレコードは 1 つだけあり、ID2 は次のようになります。直接検索すると、1行だけスキャンして終了します。
- #9) では、プレフィックスインデックスを使用する場合の注意点は何でしょうか?
長さの選択は合理的です
- # インデックス上にある異なる値の数を数えて、プレフィックスを使用する期間を決定します。
select count(distinct email) as L from SUser;
- 長さの異なるプレフィックスを順番に選択してこの値を確認します
select count(distinct left(email,4))as L4, count(distinct left(email,5))as L5, count(distinct left(email,6))as L6, count(distinct left(email,7))as L7, from SUser;
次に、L4~L7 の中で最初の A を見つけます。 L * 95% 以上の値は、このインデックスを通じて 95% 以上のデータを見つけることができることを意味します。
次の SQL ステートメント:
select id,email from SUser where email='zhangssxyz@xxx.com';
前の例の SQL ステートメント
select id,name,email from SUser where email='zhangssxyz@xxx.com';
と比較すると、最初のステートメントでは ID と電子メールを返すだけで済みます。田畑。
- index1 (つまり、メール文字列全体のインデックス構造) を使用すると、メールをチェックすることで ID を取得できるため、テーブルを返す必要はありません。これはカバリングインデックスです。
用 index2(即 email(6) 索引结构)的话,就不得不回到 ID 索引再去判断 email 字段的值。
14)那我把index2 的定义修改为 email(18) 的前缀索引不就行了?
这个18是你自己定义的,系统不知道18这个长度是否已经大于我的email长度,所以它还是会回表去查一下验证。
总而言之:使用前缀索引就用不上覆盖索引对查询性能的优化了
针对类似于邮箱这样的字段,使用前缀索引可能会产生不错的效果。但是,遇到身份证这种前缀的区分度不够好的情况时,我们要怎么办呢?
索引选取的要更长一些。
但是所以越长的话,占的磁盘空间更大,相同的一页能放下的索引值就变少了,反而会影响查询效率。
16)如果我们能够确定业务需求里面只有按照身份证进行等值查询的需求,还有没有别的处理方法呢?
-
既然正过来相同的多,那我就把它倒过来存。查询时候这样查
select field_list from t where id_card = reverse('input_id_card_string');
使用 的时候用count(distinct) 方法去做个验证
-
使用 hash 字段。在表上再创建一个整数字段,来保存身份证的校验码,同时在这个字段上创建索引。
alter table t add id_card_crc int unsigned, add index(id_card_crc);
新记录插入时必须使用 crc32() 函数生成校验码,并填入新字段中。由于校验码可能存在冲突,也就是说两个不同的身份证号通过 crc32() 函数得到的结果可能是相同的,所以你的查询语句 where 部分要判断 id_card 的值是否精确相同。
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string'
这样,索引的长度变成了 4 个字节(int类型),比原来小了很多
17)使用倒序存储和使用 hash 字段这两种方法有什么异同点?
相同点:都不支持范围查询
倒序存储的字段上创建的索引是按照倒序字符串的方式排序的,已经没有办法利用索引方式查出身份证号码在[ID_X, ID_Y]的所有市民了。同样地,hash 字段的方式也只能支持等值查询。
区别
从占用的额外空间来看,倒序存储方式在主键索引上,不会消耗额外的存储空间,而 hash 字段方法需要增加一个字段。当然,倒序存储方式使用 4 个字节的前缀长度应该是不够的,如果再长一点,这个消耗跟额外这个 hash 字段也差不多抵消了。
在 CPU 消耗方面,倒序方式每次写和读的时候,都需要额外调用一次 reverse 函数,而 hash 字段的方式需要额外调用一次 crc32() 函数。以仅考虑这两个函数的计算复杂度为前提,reverse 函数对 CPU 资源的额外消耗将较少。
就查询性能而言,采用哈希字段方式的查询更具可靠性。虽然crc32算法不可避免地存在冲突的风险,但这种风险极其微小,因此我们可以认为查询时平均扫描行数接近于1。使用倒序存储方式仍然需要使用前缀索引来进行扫描,因此会增加扫描的行数。
案例:如果你在维护一个学校的学生信息数据库,学生登录名的统一格式是”学号 @gmail.com", 而学号的规则是:十五位的数字,其中前三位是所在城市编号、第四到第六位是学校编号、第七位到第十位是入学年份、最后五位是顺序编号。
学生必须输入正确的登录名和密码,方可继续使用系统。如果只考虑登录验证这个行为,你会如何为登录名设计索引?
如果一个学校每年预计2万新生,50年才100万记录,如果直接使用全字段索引,可以节省多少存储空间?。除非遇到超大规模数据,否则不需要使用后两种方法,从而避免了开发转换和限制风险
在实际操作中,只需对所有字段进行索引,一个学校的数据库数据量和查询负担不会变得很大。 如果单从优化数据表的角度: \1. 后缀@gmail可以单独一个字段来存,或者用业务代码来保证, \2. 城市编号和学校编号估计也不会变,也可以用业务代码来配置 \3. 然后直接存年份和顺序编号就行了,这个字段可以全字段索引
以上がMySQL で文字列フィールドにインデックスを付ける方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。