
ホームページ >データベース >mysql チュートリアル >MySQL の詳細なインデックス障害ケースの分析
MySQL の詳細なインデックス障害ケースの分析

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-28 13:17:431495ブラウズ
インデックスの記憶構造
まず、インデックスの記憶構造を理解しましょう。インデックスの記憶構造を知ることによってのみ、インデックスの失敗の問題をより深く理解することができます。
インデックスのストレージ構造は MySQL ストレージ エンジンに関連しており、ストレージ エンジンが異なれば使用する構造も異なります。
MySQL のデフォルトのストレージ エンジン InnoDB は、インデックス データ構造として B Tree を使用します。テーブルを作成するとき、InnoDB はデフォルトでプライマリ キー インデックス (クラスター化インデックス) を作成し、他のインデックスはセカンダリ インデックスになります。
MyISAM ストレージ エンジンはテーブルを作成するときに、デフォルトで B ツリー インデックスを使用します。
どちらも InnoDB などの B ツリー インデックスをサポートしていますが、データの保存方法は異なります。
InnoDB はクラスター化インデックスです (B ツリー インデックスのリーフ ノードがデータ自体を保存します)。
MyISAM は非クラスター化インデックス (B ツリーのリーフ ノードがデータを格納する物理アドレス)
次の図に示すように:
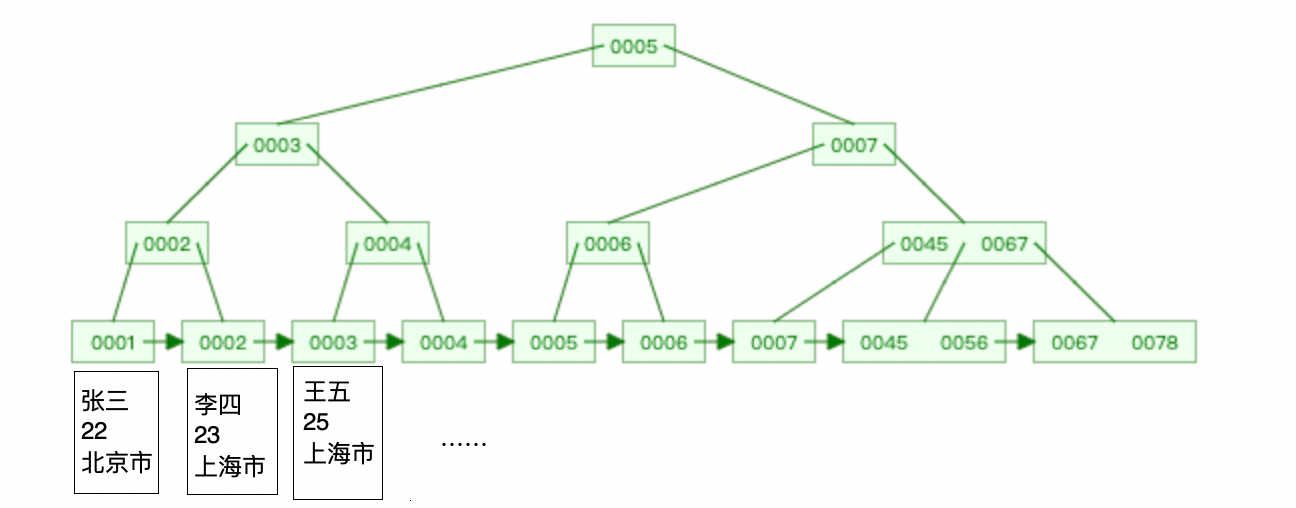
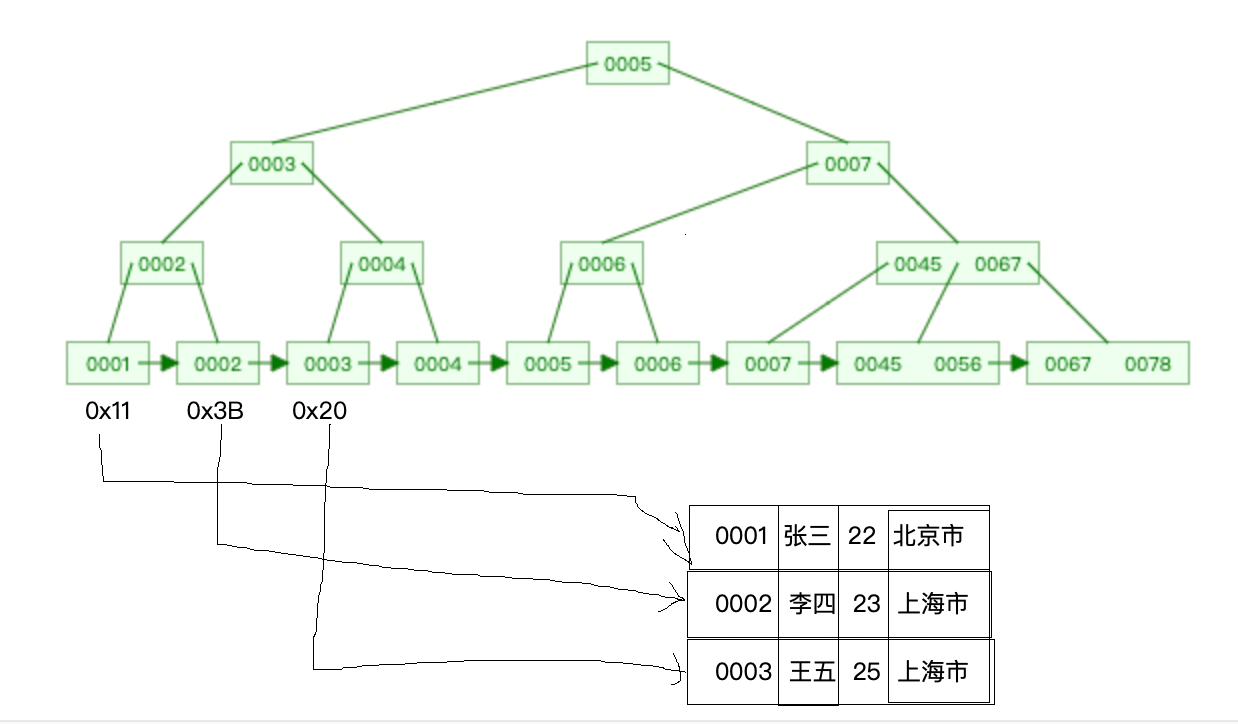
InnoDB ストレージ エンジンは [クラスター化インデックス] と [セカンダリ インデックス] に分類できます。それらの違いは、クラスター化インデックスのリーフ ノードに実際のデータが格納されることと、すべての完全なデータはクラスター化インデックスに保存され、セカンダリ インデックスのリーフ ノードには主キー値が保存されます。
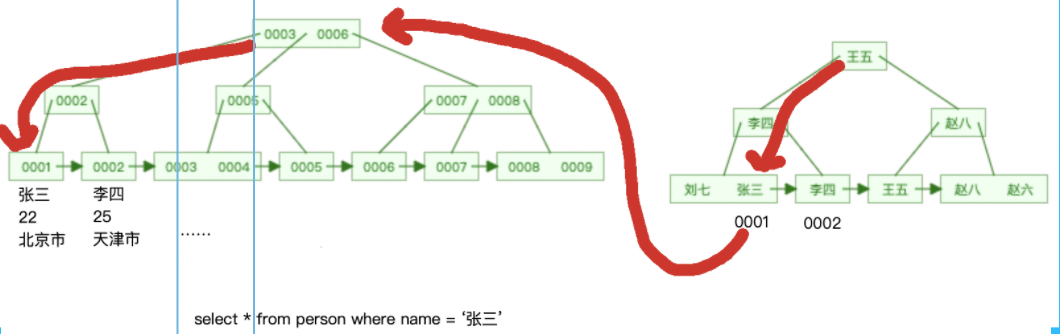
セカンダリ インデックス フィールドをクエリ条件として使用し、クラスター化インデックス上のデータをクエリする場合、
はまず条件に従ってセカンダリ インデックス上の対応するリーフ ノードを検索し、プライマリ インデックスを取得します。 key.value,
その後、主キー値に基づいてクラスター化インデックス上の対応するリーフ ノードを見つけて、対応するデータをクエリします。
このプロセスはテーブルにコールバックされます
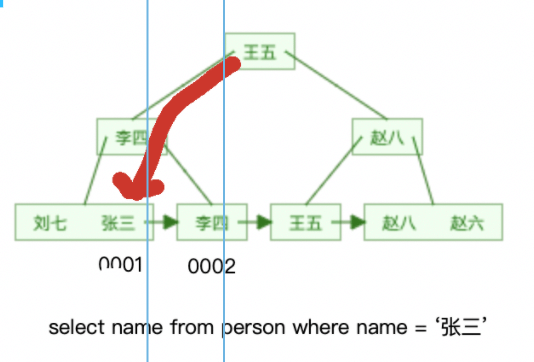
セカンダリ インデックスをクエリ条件として使用します。クエリされたデータがセカンダリ インデックスのリーフ ノードにある場合、必要なのは、セカンダリ インデックスの B ツリーに対応するリーフ ノードを見つけることだけです。セカンダリ インデックスを作成してデータを読み取ります。このプロセスはカバリング インデックスと呼ばれます。
上記のクエリ条件はすべてインデックス列を使用しますが、インデックスが確実に有効になることを意味するものではありません。インデックス列が使用されている場合。もう一度インデックスを見てみましょう。失敗状況
不当なファジークエリ条件
左または左ファジィクエリを使用する場合、つまり like " % Zhang" または like "% Zhang%"これら 2 つのファジー クエリ メソッドはインデックスの失敗を引き起こします
B ツリーはインデックス値に従って配置されるため、プレフィックスは不確かですが、「Xiao Zhang」、「Two Zhang」の可能性があります。このようなすべての場合、クエリはフル テーブル スキャンを通じてのみクエリできます。
インデックスに関数を使用します。
例: SELECT * FROM sys_user WHERE LENGTH(user_id) = 3 ;

alter table t_user add key idx_name_length ((length(name)));
インデックスに対して式の計算を実行します例: select * from sys_user where user_id 1 =3;

ただし、SELECT * FROM sys_user WHERE user_id = 1 1 ;

#理由はインデックスの使用に関連しています。関数は似ています。インデックスはインデックス フィールドの元の値を保存します。計算された値であるため、インデックスは使用できません。
インデックスには暗黙的な変換を使用してください
Herephoneフィールドはセカンダリ インデックスであり、型は varchar


整数をクエリ パラメーターとして使用する場合、実行プランのタイプは ALL、つまりフル テーブル スキャンを通じてクエリされますが、これは文字列型であり、依然としてインデックスによってクエリされます
別の例を見てみましょう
Hereuser_id は bigint 型ですが、クエリ パラメータとして文字列を使用しても、索引############

为什么第一个例子导致了索引失效,而第二个不会呢?
这里就要了解一下MySQL的字符转换规则了,看是数字转字符串,还是字符串转数字
我们可以用select "10">9来测试一下
如果是数字转字符串,那么就相当于select "10">"9"结果应该是0
如果是字符串转数字,那么就相当于select 10>9,结果是1
在MySQL中的执行结果如下:

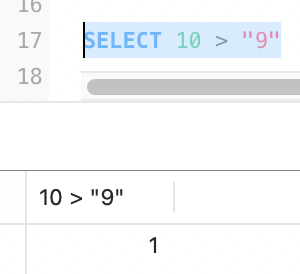
这就说明,MySQL在遇到数字与字符串的比较的时候,会自动把字符串转换为数字,然后进行比较
也就是说,在第一个例子中
SELECT * FROM sys_user WHERE phone = 18200000000 ;
相当于
SELECT * FROM sys_user WHERE CAST(phone AS UNSIGNED) = 18200000000 ;
这就在索引字段上使用了函数,所以导致索引失效
而在第二个例子中
SELECT * FROM sys_user WHERE user_id = "1" ;
相当于
SELECT * FROM sys_user WHERE user_id = CAST("1" AS UNSIGNED) ;函数式作用在查询参数上的,并没有作用在索引字段上,所以还是走索引的
联合索引非最左匹配
多个普通字段组合在一起创建的索引叫做联合索引(组合索引)
在使用联合索引的时候,一定要注意顺序问题,联合索引的使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引匹配。
例如,创建了一个(a,b,c)联合索引,那么如果查询条件是一下几种,就可以匹配上联合索引
where a = 1
where a = 1 and b = 2
where a = 1 and b = 2 and c = 3
需要注意的是,因为有查询优化器,所以a字段在where子句中的顺序不重要
若缺少a字段,则以下几种情况由于不符合最左匹配原则将无法匹配联合索引,导致该联合索引失效
where b = 2
where c = 3
where b = 2 and c = 3
还有一个比较特殊的查询条件:where a = 1 and c = 3
在MySQL5.5的话,前面的a 会走索引,在联合索引找到主键值,然后回表,到主键索引读取数据行,然后在比对c字段的值
在MySQL5.6之后,有一个索引下推的功能,
下推就是将部分上层(服务层)负责的事情,交给了下层(引擎层)处理
存储引擎直接在联合索引里按照c=3过滤,按照过滤后的数据在进行回表扫描,减少了回表的次数,从而提升了性能
在执行计划中Extra = Using index condition就表示使用了索引下推

联合索引不遵循最左匹配原则的原因:在联合索引中,数据按照第一列索引进行排序,第一列数据相同时,才会按照第二列进行排序,以此类推,所以直接使用第二列进行查询的时候,联合索引就会失效
where子句中的or
where子句中or的条件列有不是索引列会导致索引失效
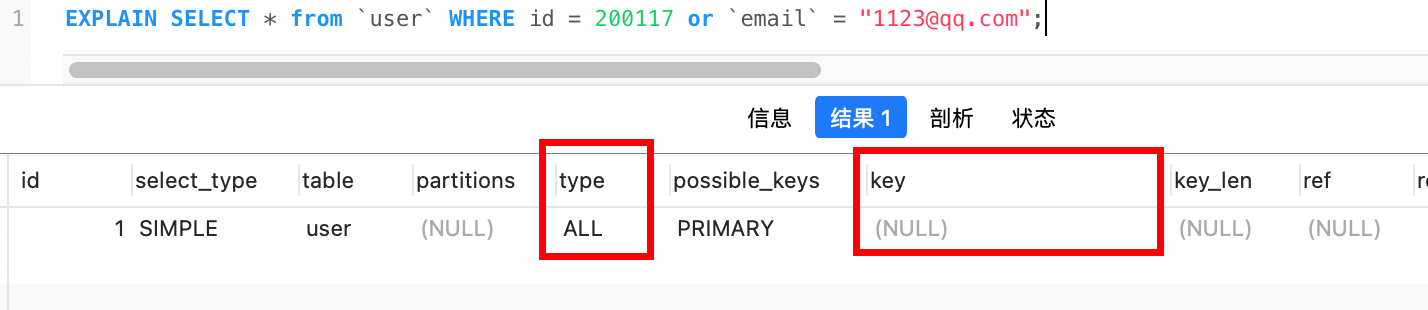
例如:下图中id是索引列,email不是索引列,从执行计划来看,进行了全文扫描并没有使用到索引
因为or关键字只满足一个条件就可以,因此只要有一个列不是索引列,其他索引列也就没有意义了,就会进行全表扫描
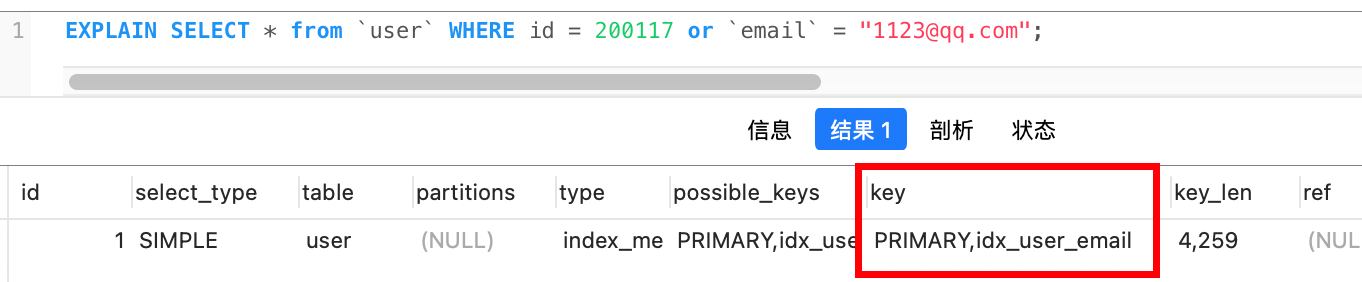
在email列上建立索引之后,可以看到执行计划中使用到了两个索引
type = index_merge表示对id 和email都进行了扫描,然后进行了合并
以上がMySQL の詳細なインデックス障害ケースの分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。