
ホームページ >データベース >mysql チュートリアル >MySQLストアドプロシージャを呼び出す方法
MySQLストアドプロシージャを呼び出す方法

- 王林転載
- 2023-05-27 23:39:075822ブラウズ
概要
ストアド プロシージャは、MySQL 5.0 バージョン以降でサポートされます。
特定のユーザーのニーズを達成するために複雑な SQL ステートメントのセットを作成する必要がある場合は、この複雑な SQL ステートメントのセットを事前にデータベースに作成し、JDBC によって呼び出してこの SQL ステートメントのセットを実行できます。 。データベースに記述された SQL ステートメントのセットはストアド プロシージャと呼ばれます。
ストアド プロシージャ : (PROCEDURE) は、事前にコンパイルされデータベースに保存されている SQL ステートメントのコレクションです。ストアド プロシージャを呼び出すと、アプリケーション開発者の多くの作業が簡素化され、データベースとアプリケーション サーバー間のデータ送信が削減され、データ処理の効率を向上させるのに非常に役立ちます。
はコードのカプセル化とデータベース SQL 言語レベルでの再利用です。
Java のメソッドと同様に、ストアド プロシージャは最初に定義し、使用時に呼び出す必要があります。ストアド プロシージャではパラメータを定義でき、パラメータは IN、OUT、INOUT の 3 種類に分類されます。
IN 型パラメータは呼び出し元から渡されたデータの受け入れを表します;
-
OUT 型パラメータは呼び出し元にデータを返すことを表します;
INOUT 型パラメータは、呼び出し元から渡されたパラメータを受け入れることができ、呼び出し元にデータを返すこともできます。
利点
ストアド プロシージャは、処理を通じて使いやすい単位にカプセル化され、複雑な操作が簡素化されます。
変更管理を簡素化します。テーブル名、列名、またはビジネス ロジックが変更された場合。ストアド プロシージャのコードのみを変更する必要があります。これを使用する人はコードを変更する必要がありません。
通常、ストアド プロシージャはアプリケーションのパフォーマンスの向上に役立ちます。作成されたストアド プロシージャはコンパイルされるとデータベースに保存されます。
ただし、MySQL によって実装されるストアド プロシージャは少し異なります。
MySQL ストアド プロシージャはオンデマンドでコンパイルされます。ストアド プロシージャをコンパイルした後、MySQL はそれをキャッシュに配置します。
MySQL は、接続ごとに独自のストアド プロシージャ キャッシュを維持します。アプリケーションが 1 つの接続でストアド プロシージャを複数回使用する場合は、コンパイルされたバージョンを使用します。それ以外の場合、ストアド プロシージャはクエリのように機能します。ストアド プロシージャは、アプリケーションとデータベース サーバー間のトラフィックを削減するのに役立ちます。
アプリケーション プログラムは複数の長い SQL ステートメントを送信する必要がないため、ストアド プロシージャ内の名前とパラメーターを送信するだけで済みます。ストアド プロシージャは再利用可能であり、あらゆるアプリケーションに対して透過的です。開発者がすでにサポートされている機能を重複しないようにするために、ストアド プロシージャはデータベース インターフェイスをすべてのアプリケーションに公開します。
保存されたプログラムは安全です。データベース管理者は、基礎となるデータベース テーブルに権限を付与せずに、データベース内のストアド プロシージャにアクセスするアプリケーションに適切な権限を付与できます。
欠点
多数のストアド プロシージャを使用すると、これらのストアド プロシージャを使用する各接続のメモリ使用量が大幅に増加します。
さらに、ストアド プロシージャで多数の論理操作が過剰に使用されると、CPU 使用率も増加します。これは、MySQL データベースの元の設計では、論理操作ではなく効率的なクエリに重点が置かれていたためです。ストアド プロシージャの構造により、複雑なビジネス ロジックを含むストアド プロシージャの開発が困難になります。
ストアド プロシージャをデバッグするのは困難です。ストアド プロシージャのデバッグができるデータベース管理システムはわずかです。残念ながら、MySQL にはストアド プロシージャをデバッグする機能がありません。
ストアド プロシージャの開発と保守は簡単ではありません。
ストアド プロシージャの開発と保守には、多くの場合、すべてのアプリケーション開発者が持っているわけではない特殊なスキル セットが必要です。これにより、アプリケーションの開発およびメンテナンスの段階で問題が発生する可能性があります。はデータベースへの依存度が高く、転送性が低いです。
MySQL ストアド プロシージャの定義
ストアド プロシージャの基本的なステートメント形式
DELIMITER $$
CREATE
/*[DEFINER = { user | CURRENT_USER }]*/
PROCEDURE 数据库名.存储过程名([in变量名 类型,out 参数 2,...])
/*LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'*/
BEGIN
[DECLARE 变量名 类型 [DEFAULT 值];]
存储过程的语句块;
END$$
DELIMITER ;#ストアド プロシージャ内のパラメータは in、out です。 、3 種類の inout;
in は入力パラメータ (デフォルトでは in パラメータ) を表し、パラメータの値が呼び出し側プログラムによって指定される必要があることを示します。
ou は出力パラメーターを表します。これは、パラメーターの値がストアド プロシージャによって計算された後、out パラメーターの計算結果が呼び出し側プログラムに返されることを意味します。
Inout は、即時の入力パラメータと出力パラメータを表します。つまり、パラメータの値は呼び出し側プログラムによって定式化でき、inout パラメータの計算結果を返すことができます。呼び出し元のプログラムに。
● ストアド プロシージャ内のステートメントは、BEGIN と END の間に含める必要があります。
# DECLARE は変数の宣言に使用されます。デフォルトの変数割り当てでは DEFAULT が使用されます。ステートメント ブロック内の変数値を変更するには、SET variable = value;
ストアド プロシージャの使用
ストアド プロシージャを定義する
DELIMITER $$
CREATE
PROCEDURE `demo`.`demo1`()
-- 存储过程体
BEGIN
-- DECLARE声明 用来声明变量的
DECLARE de_name VARCHAR(10) DEFAULT '';
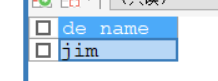
SET de_name = "jim";
-- 测试输出语句(不同的数据库,测试语句都不太一样。
SELECT de_name;
END$$
DELIMITER ;
ストアド プロシージャを呼び出す
CALL demo1();
ストアド プロシージャを定義するパラメーター付きストアド プロシージャ ストアド プロシージャ
最初に学生データベース テーブルを定義します:
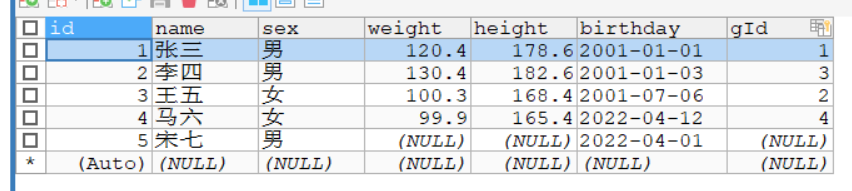
现在要查询这个student表中的sex为男的有多少个人。
DELIMITER $$
CREATE
PROCEDURE `demo`.`demo2`(IN s_sex CHAR(1),OUT s_count INT)
-- 存储过程体
BEGIN
-- 把SQL中查询的结果通过INTO赋给变量
SELECT COUNT(*) INTO s_count FROM student WHERE sex= s_sex;
SELECT s_count;
END$$
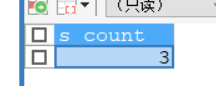
DELIMITER ;调用这个存储过程
-- @s_count表示测试出输出的参数 CALL demo2 ('男',@s_count);
定义一个流程控制语句 IF ELSE
IF 语句包含多个条件判断,根据结果为 TRUE、FALSE执行语句,与编程语言中的 if、else if、else 语法类似。
DELIMITER $$
CREATE
PROCEDURE `demo`.`demo3`(IN `day` INT)
-- 存储过程体
BEGIN
IF `day` = 0 THEN
SELECT '星期天';
ELSEIF `day` = 1 THEN
SELECT '星期一';
ELSEIF `day` = 2 THEN
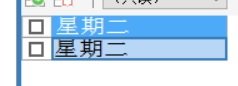
SELECT '星期二';
ELSE
SELECT '无效日期';
END IF;
END$$
DELIMITER ;调用这个存储过程
CALL demo3(2);
定义一个条件控制语句 CASE
case是一种类似于编程语言中的choose和when语法的条件判断语句。MySQL 中的 case语句有两种语法格式。
第一种
DELIMITER $$
CREATE
PROCEDURE demo4(IN num INT)
BEGIN
CASE -- 条件开始
WHEN num<0 THEN
SELECT '负数';
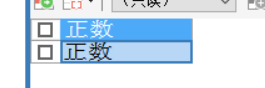
WHEN num>0 THEN
SELECT '正数';
ELSE
SELECT '不是正数也不是负数';
END CASE; -- 条件结束
END$$
DELIMITER;调用这个存储过程
CALL demo4(1);
2.第二种
DELIMITER $$
CREATE
PROCEDURE demo5(IN num INT)
BEGIN
CASE num -- 条件开始
WHEN 1 THEN
SELECT '输入为1';
WHEN 0 THEN
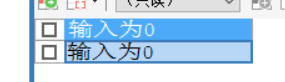
SELECT '输入为0';
ELSE
SELECT '不是1也不是0';
END CASE; -- 条件结束
END$$
DELIMITER;调用此函数
CALL demo5(0);
定义一个循环语句 WHILE
DELIMITER $$
CREATE
PROCEDURE demo6(IN num INT,OUT SUM INT)
BEGIN
SET SUM = 0;
WHILE num<10 DO -- 循环开始
SET num = num+1;
SET SUM = SUM+num;
END WHILE; -- 循环结束
END$$
DELIMITER;调用此函数
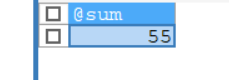
-- 调用函数 CALL demo6(0,@sum); -- 查询函数 SELECT @sum;
定义一个循环语句 REPEAT UNTLL
REPEATE…UNTLL 语句的用法和 Java中的 do…while 语句类似,都是先执行循环操作,再判断条件,区别是REPEATE 表达式值为 false时才执行循环操作,直到表达式值为 true停止。
-- 创建过程
DELIMITER $$
CREATE
PROCEDURE demo7(IN num INT,OUT SUM INT)
BEGIN
SET SUM = 0;
REPEAT-- 循环开始
SET num = num+1;
SET SUM = SUM+num ;
UNTIL num>=10
END REPEAT; -- 循环结束
END$$
DELIMITER;调用此函数
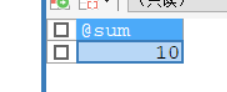
CALL demo7(9,@sum); SELECT @sum;
定义一个循环语句 LOOP
循环语句,用来重复执行某些语句。
执行过程中可使用 LEAVE语句或者ITEREATE来跳出循环,也可以嵌套IF等判断语句。
LEAVE 语句效果对于Java中的break,用来终止循环;
ITERATE语句效果相当于Java中的continue,用来跳过此次循环。进入下一次循环。且ITERATE之下的语句将不在进行。
DELIMITER $$
CREATE
PROCEDURE demo8(IN num INT,OUT SUM INT)
BEGIN
SET SUM = 0;
demo_sum:LOOP-- 循环开始
SET num = num+1;
IF num > 10 THEN
LEAVE demo_sum; -- 结束此次循环
ELSEIF num < 9 THEN
ITERATE demo_sum; -- 跳过此次循环
END IF;
SET SUM = SUM+num;
END LOOP demo_sum; -- 循环结束
END$$
DELIMITER;调用此函数
CALL demo8(0,@sum); SELECT @sum;

使用存储过程插入信息
DELIMITER $$
CREATE
PROCEDURE demo9(IN s_student VARCHAR(10),IN s_sex CHAR(1),OUT s_result VARCHAR(20))
BEGIN
-- 声明一个变量 用来决定这个名字是否已经存在
DECLARE s_count INT DEFAULT 0;
-- 验证这么名字是否已经存在
SELECT COUNT(*) INTO s_count FROM student WHERE `name` = s_student;
IF s_count = 0 THEN
INSERT INTO student (`name`, sex) VALUES(s_student, s_sex);
SET s_result = '数据添加成功';
ELSE
SET s_result = '名字已存在,不能添加';
SELECT s_result;
END IF;
END$$
DELIMITER;调用此函数
CALL demo9("Jim","女",@s_result);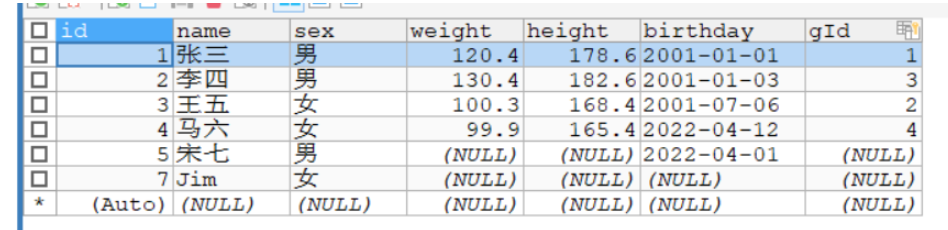
再次调用次函数
CALL demo9("Jim","女",@s_result)
存储过程的管理
显示存储过程
SHOW PROCEDURE STATUS

显示特定数据库的存储过程
SHOW PROCEDURE STATUS WHERE db = 'db名字' AND NAME = 'name名字';
显示特定模式的存储过程
SHOW PROCEDURE STATUS WHERE NAME LIKE '%mo%';

显示存储过程的源码
SHOW CREATE PROCEDURE 存储过程名;

删除存储过程
DROP PROCEDURE 存储过程名;
后端调用存储过程的实现
在mybatis当中,调用存储过程
<parameterMap type="savemap" id=“usermap">
<parameter property="name" jdbcType="VARCHAR" mode="IN"/>
<parameter property="sex" jdbcType="CHAR" mode="IN"/>
<parameter property="result" jdbcType="VARCHAR" mode="OUT"/>
</parameterMap>
<insert id="saveUserDemo" parameterMap="savemap" statementType="CALLABLE">
{call saveuser(?, ?, ?)}
</insert >调用数据库管理
HashMap<String, Object> map = new HashMap<String, Object>();
map.put("name", "Jim");
map.put("sex","男");
userDao.saveUserDemo(map);
map.get(“result”);//获得输出参数通过这样就可以调用数据库中的存储过程的结果。
以上がMySQLストアドプロシージャを呼び出す方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。