
ホームページ >テクノロジー周辺機器 >AI >逐次的な意思決定と基礎となるモデルはどのように交差し、相互に影響し合うのでしょうか? Google、バークレーなどがさらなる可能性を模索
逐次的な意思決定と基礎となるモデルはどのように交差し、相互に影響し合うのでしょうか? Google、バークレーなどがさらなる可能性を模索

- 王林転載
- 2023-05-27 21:52:411448ブラウズ
幅広いデータセットに対する自己教師あり学習に基づいた事前トレーニング済みの基本モデルは、知識をさまざまな下流タスクに伝達する優れた能力を実証しています。その結果、これらのモデルは、長期的な推論、制御、探索、計画などのより複雑な問題にも適用され、あるいは対話、自動運転、ヘルスケア、ロボット工学などのアプリケーションにも展開されます。将来的には、外部エンティティやエージェントへのインターフェースも提供する予定です。たとえば、会話アプリケーションでは、言語モデルが複数のラウンドで人々と通信します。ロボット工学の分野では、知覚制御モデルが現実の環境でアクションを実行します。
これらのシナリオは、基本モデルに次のような新たな課題をもたらします。1) 外部エンティティからのフィードバック (会話の品質に関する人間による評価など) から学習する方法、2) 環境に適応する方法言語または視覚データセット(ロボットの動作など)における大規模で一般的ではないモダリティ、3)将来の長期的な推論と計画の立て方。
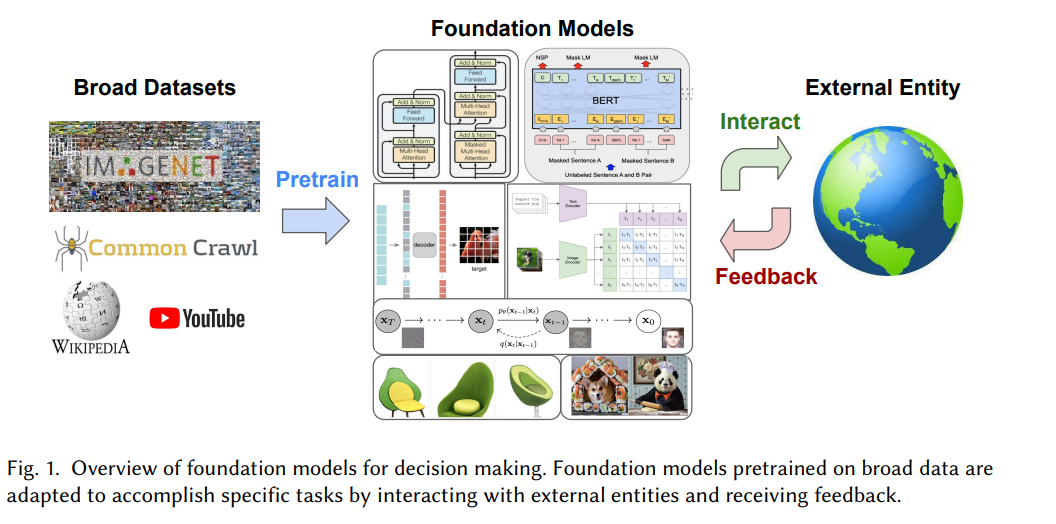
これらの問題は常に、強化学習や模倣学習を含む、伝統的な意味での逐次的意思決定の中核でした。 、計画、探索と最適な制御。ベースモデルが数十億の画像トークンとテキストトークンの広範なデータセットを使用して事前トレーニングされるパラダイムとは対照的に、逐次的意思決定に関するこれまでの研究は、主に事前知識が限られたタスク固有の設定またはホワイトボード設定に焦点を当てていました。
事前知識の不足または欠如により、逐次的な意思決定は困難に見えますが、逐次的な意思決定に関する研究は、ボードゲーム、エレガンス、エレガンスなどの複数のタスクにおいて人間のパフォーマンスを上回りました。など Dali (Atari) ビデオ ゲームと操作ロボットを使用してナビゲーションと操作を完了します。
ただし、これらの方法は、視覚、言語、その他のデータセットからの広範な知識なしでタスクを解決する方法を最初から学習するため、一般化とサンプル効率の点でパフォーマンスが劣ることがよくあります。 1 つの Atari ゲームを解決するには、1 日実行するには 7 つの GPU が必要です。直観的には、基本モデルで使用されるものと同様の広範なデータセットは、逐次意思決定モデルにも役立つはずです。たとえば、インターネット上には、Atari ゲームのプレイ方法に関する記事やビデオが無数にあります。オブジェクトやシーンのプロパティに関する広範な知識がロボットに役立つのと同じように、人間の欲望や感情に関する知識は会話モデルを改善できます。
基本モデルと逐次的意思決定に関する研究は、さまざまな用途や関心事のために一般にバラバラですが、交差する研究はますます増えています。基本モデルに関しては、大規模な言語モデルの出現により、対象となるアプリケーションは、単純なゼロショットまたは数回のタスクから、長期的な推論や複数の対話を必要とする問題にまで拡大しました。対照的に、逐次的意思決定の分野では、大規模な視覚モデルと言語モデルの成功に触発されて、研究者はマルチモデル、マルチタスク、および一般的な対話型エージェントを学習するためにますます大規模なデータセットを準備し始めました。
2 つの分野間の境界線はますます曖昧になってきており、最近の研究では、ビジュアル環境でインタラクティブなインテリジェンスをブートストラップするために、事前トレーニングされた基本モデル (CLIP や ViT など) が研究されています。他の研究では、強化学習と人間のフィードバックを通じて最適化された会話型エージェントとしての基本モデルが研究されています。また、大規模な言語モデルを、検索エンジン、計算機、翻訳ツール、MuJoCo シミュレーター、プログラム インタプリタなどの外部ツールと対話できるように適応させる作業も行われています。
最近、Google Brain チーム、カリフォルニア大学バークレー校、MIT の研究者らは、基本モデルとインタラクティブな意思決定研究の組み合わせが相互に利益をもたらすと書きました。一方で、基礎となるモデルを外部エンティティが関与するタスクに適用すると、インタラクティブなフィードバックと長期計画の恩恵を受けることができます。一方、逐次的な意思決定では、基礎となるモデルに関する世界の知識を活用して、タスクをより迅速に解決し、より適切に一般化することができます。

論文アドレス: https://arxiv.org/pdf/2303.04129v1.pdf
これら 2 つの分野の交差点におけるさらなる研究を促進するために、研究者は、意思決定のための基礎となるモデルの問題空間を制限しました。また、現在の研究を理解し、現在の課題と未解決の疑問をレビューし、これらの課題に対処するための潜在的な解決策と有望なアプローチを予測するための技術ツールも提供します。
論文の概要
この論文は主に次の 5 つの主要な章に分かれています。
第 2 章では、逐次的な意思決定に関連する背景を確認し、基礎となるモデルと意思決定を一緒に考慮するのが最適なシナリオの例をいくつか示します。これに続いて、意思決定システムのさまざまなコンポーネントが基礎となるモデルを中心にどのように構築されるかについて説明します。

#第 3 章では、基本モデルが行動生成モデル (スキル発見など) および環境生成モデル (モデルベースの演繹など) としてどのように機能するかを検討します。 )。
 #第 5 章では、言語ベースのモデルが、逐次意思決定フレームワーク (言語モデル) で逐次意思決定を可能にする対話型エージェントおよび環境としてどのように機能するかを検討します。推論、対話、ツールの使用など)、新しい問題と応用を検討します。
#第 5 章では、言語ベースのモデルが、逐次意思決定フレームワーク (言語モデル) で逐次意思決定を可能にする対話型エージェントおよび環境としてどのように機能するかを検討します。推論、対話、ツールの使用など)、新しい問題と応用を検討します。

 #詳細については、元の論文を参照してください。
#詳細については、元の論文を参照してください。
以上が逐次的な意思決定と基礎となるモデルはどのように交差し、相互に影響し合うのでしょうか? Google、バークレーなどがさらなる可能性を模索の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。