
ホームページ >データベース >mysql チュートリアル >MySQL クラスター化インデックスの長所と短所は何ですか
MySQL クラスター化インデックスの長所と短所は何ですか

- 王林転載
- 2023-05-27 21:43:111485ブラウズ
1. クラスタード インデックスとは
データベース インデックスはさまざまな観点からさまざまな種類に分類できますが、クラスタード インデックスもその 1 つです。
クラスタードインデックスは英語でClustered Indexといい、クラスタードインデックスなどと呼んでいる人も時々見かけますが、その反対はノンクラスタードインデックス、セカンダリインデックスです。
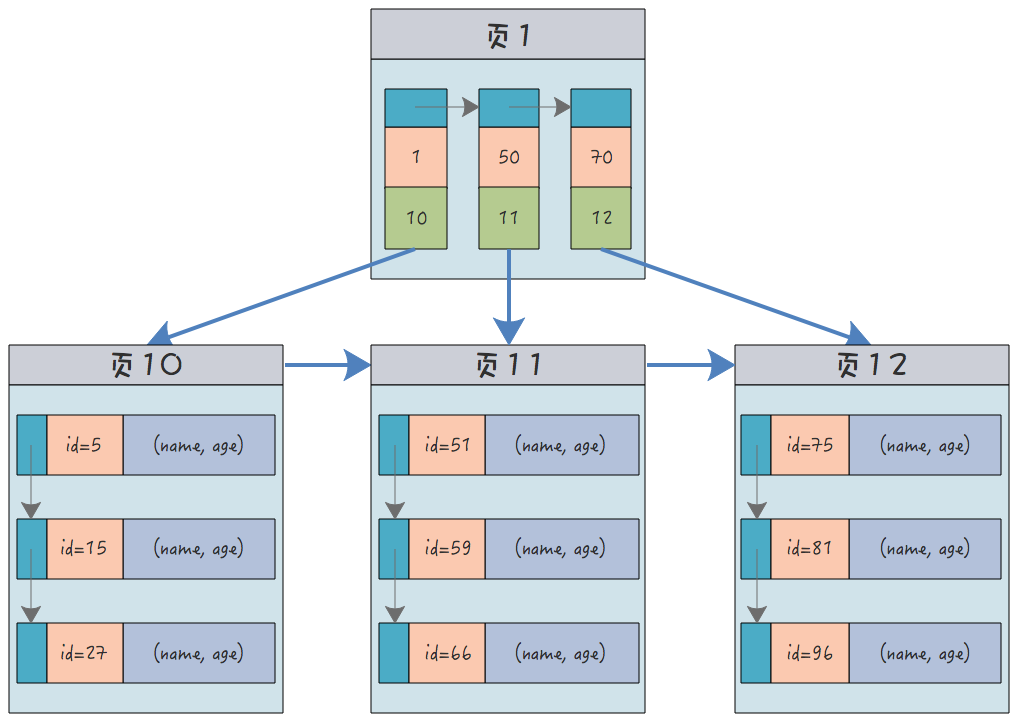
クラスター化インデックスは個別のインデックス タイプではなく、データを保存する方法の 1 つです。 MySQL の InnoDB ストレージ エンジンでは、いわゆるクラスター化インデックスは、実際にはインデックスとデータ行を同じ B ツリーに保存します。 この時点で、データはリーフ ノードに配置され、クラスター化され、クラスター化されます。これは、前述のデータ行を意味します。と対応するキー値がコンパクトにまとめて存在します。
次のデータがあるとします:
| id (主キー) | username | age | 住所 | 性別 |
|---|---|---|---|---|
| 1 | ab | 99 | 深セン | 男 |
| ac | ##98 | 广州 | ##男3 | |
| 88 | 北京 | 女 | 4 | |
| 80 | 上海 | 女 | 5 | |
| 85 | 重慶 | #女 | 6 | |
| 95 | 天津 | 男性 | 7 | |
| 99 | 海口 | 女 | 8 | |
| 92 | 武汉 | 男性 | 9 | |
| 90 | 深セン | 男性 | 10 | |
| 93 | 深セン | 男性 |
そのクラスター化インデックスはおそらく次のようになります:
# すると、主キー値 (インデックス) とデータ行の両方がリーフにあることがわかります。 . ノードには主キー値(インデックス)のみが存在します。 考えてみてください、MySQL テーブルのデータはディスク上に 1 つのコピーにのみ保存でき、2 つのコピーを保存することは不可能です。したがって、テーブル内にはクラスター化されたデータは 1 つだけ存在できます。インデックスを 1 つだけ持つことは不可能です。複数。 2. クラスター化インデックスと主キー友人の中には、この 2 つの関係をよく理解しておらず、この 2 つを同一視している人もいますが、これは大きな誤解です。 一部のデータベースでは、開発者はクラスタ化インデックスとして使用するインデックスを自由に選択できますが、MySQL はこの機能をサポートしていません。 MySQL では、テーブル自体に主キーが設定されている場合、主キーはクラスター化インデックスになります。テーブル自体に主キーが設定されていない場合、テーブル内の一意の空でないインデックスは、 ; テーブル内に一意の空でないインデックスがない場合、テーブル内の暗黙的な主キーがクラスター化インデックスとして自動的に選択されます。 Brother Song は、今後の記事で MySQL テーブルの暗黙的な主キーについて紹介する予定です。
上記の説明に基づいて、MySQL のクラスター化インデックスと主キー インデックスの関係を次のように要約できます。
3. クラスター化インデックスの利点と欠点最初に利点について話しましょう:
これらはクラスター化インデックスの一般的な利点の一部であり、実際、日常のテーブル設計ではこれらの利点を最大限に活用する必要があります。 欠点を見てみましょう:
|
以上がMySQL クラスター化インデックスの長所と短所は何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。