
ホームページ >データベース >mysql チュートリアル >MySQL で重複したクエリを削除する方法は何ですか?
MySQL で重複したクエリを削除する方法は何ですか?

- 王林転載
- 2023-05-27 21:23:0612770ブラウズ
1. テスト データの挿入
下図のテスト データでは、user_name が lilei と zhaofeng であるユーザーが重複データです。
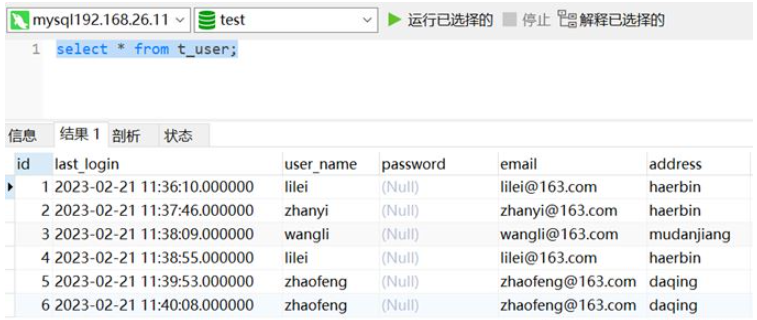
2. 重複データを削除する方法
1. 方法 1: unique を使用する
コードは次のとおりです ( example):
select distinct user_name,email,address from t_user;
以下に示すように、データは重複排除されており、重複データは 1 つだけ保持されています。
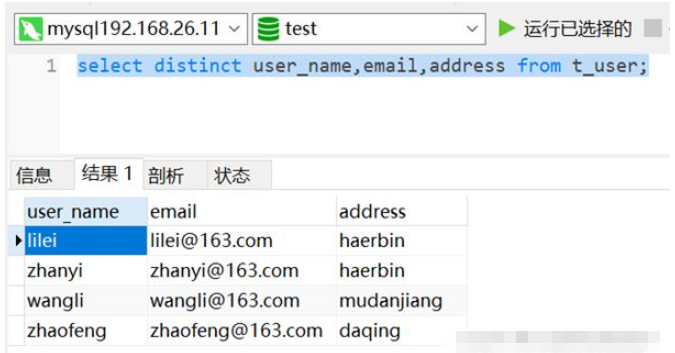
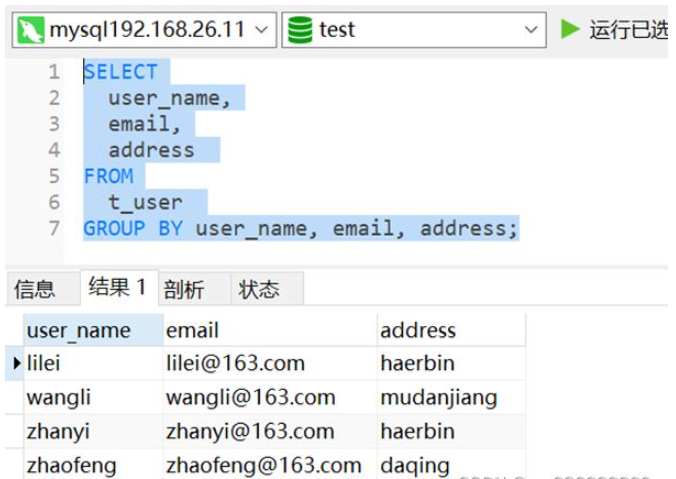
2. 方法 2: 以下に示すように、group by
SELECT user_name,email,address FROM t_user GROUP BY user_name, email, address;
を使用します。データは重複排除されており、重複データ 1 つだけが保持されます。
3. 方法 3: ウィンドウ関数を使用する
(1) データベースが MySQL8 以降の場合は、ウィンドウ関数 row_number( )
SELECT *
FROM(
SELECT t.*,
ROW_NUMBER() OVER(PARTITION BY user_name
ORDER BY last_login DESC) rn
FROM table AS t
) AS t_user
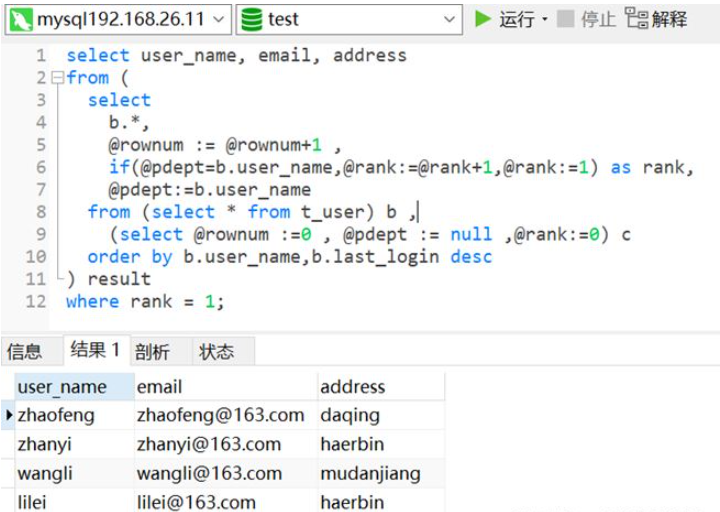
WHERE rn = 1;(2) データベースのバージョンが MySQL8 より低い場合は、以下に示すようにクラス row_number() メソッド
select user_name, email, address from ( select b.*, @rownum := @rownum+1 ,-- 定义用户变量@rownum来记录数据的行号 if(@pdept=b.user_name,@rank:=@rank+1,@rank:=1) as rank,-- 如果当前分组user_name和上一次分组user_name相同,则@rank(对每一组的数据进行编号)值加1,否则表示为新的分组,从1开始 @pdept:=b.user_name -- 定义变量@pdept用来保存上一次的分组id from (select * from t_user) b , (select @rownum :=0 , @pdept := null ,@rank:=0) c -- 初始化自定义变量值 order by b.user_name,b.last_login desc -- 该排序必须,否则结果会不对 ) result where rank = 1;
を使用します。データは重複排除されており、重複データは 1 つだけ保持されます。 。
以上がMySQL で重複したクエリを削除する方法は何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はyisu.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。