
ホームページ >データベース >mysql チュートリアル >MySQLチューニングにおけるSQLクエリのディープページング問題を解決する方法
MySQLチューニングにおけるSQLクエリのディープページング問題を解決する方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-27 09:58:371932ブラウズ
1. 問題の紹介
たとえば、現在 test_user というテーブルがあり、このテーブルに 300 万のデータを挿入します:
CREATE TABLE `test_user` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键id', `user_id` varchar(36) NOT NULL COMMENT '用户id', `user_name` varchar(30) NOT NULL COMMENT '用户名称', `phone` varchar(20) NOT NULL COMMENT '手机号码', `lan_id` int(9) NOT NULL COMMENT '本地网', `region_id` int(9) NOT NULL COMMENT '区域', `create_time` datetime NOT NULL COMMENT '创建时间', PRIMARY KEY (`id`), KEY `idx_user_id` (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT;
データベース開発のプロセスでは、よく次のようなものを使用します。 paging のコア技術は、limit start, count ページング ステートメントを使用してデータを読み取ることです。
0、10000、100000、500000、1000000、1800000 (1 ページあたり 100 エントリ) から始まるページングの実行時間を見てみましょう。
SELECT * FROM test_user LIMIT 0,100; # 0.031 SELECT * FROM test_user LIMIT 10000,100; # 0.047 SELECT * FROM test_user LIMIT 100000,100; # 0.109 SELECT * FROM test_user LIMIT 500000,100; # 0.219 SELECT * FROM test_user LIMIT 1000000,100; # 0.547s SELECT * FROM test_user LIMIT 1800000,100; # 1.625s
開始記録が増加すると、時間も増加することがわかりました。開始レコードを 290 万に変更した後、ページング ステートメントの制限と開始ページ番号
SELECT * FROM test_user LIMIT 2900000,100; # 3.062s
の間に大きな相関関係があることがわかります。データの量が大きい値が大きいほど、クエリ速度が遅くなります。
では、なぜ上記のような状況が起こるのでしょうか?
回答: limit 2900000,100 の構文は、実際には、mysql が最初の 2900100 個のデータをスキャンし、最初の 3000000 行を破棄することを意味するため、このステップは実際には無駄です。
これから、次の 2 つのことが結論付けられます。
limit ステートメントのクエリ時間は、開始レコードの位置に比例します。
Mysql の limit ステートメントは非常に便利ですが、多数のレコードを持つテーブルで直接使用するのには適していません。
2. MySQL での使用制限
limit 句を使用すると、select ステートメントに指定された数のレコードを強制的に返すことができます。その構文形式は次のとおりです:
SELECT * FROM 表名 limit m,n; SELECT * FROM table LIMIT [offset,] rows;
制限は 1 つまたは 2 つの数値パラメータを受け入れます。パラメータは整数定数である必要があります。2 つのパラメータが指定された場合:
最初のパラメータは、最初に返されたレコード行のオフセットを指定します。
2 番目のパラメータは、
2.1 m は m 1 レコード行から検索を開始することを意味し、n は n 個のデータを取得することを意味します。 (mは0でも可)
SELECT * FROM 表名 limit 6,5;
上記SQLはレコード7行目から5個のデータを取り出すことを示しています
2.2 n は -1 に設定できることに注意してください。n が -1 の場合、データの最後の部分が取得されるまで行 m1 から取得することを意味します。
SELECT * FROM 表名 limit 6,-1;
上記の SQL は、すべてのデータが取得されることを示します。 6 番目のレコード行が取得された後
2.3 m のみを指定すると、最初のレコード行から m 個のレコードが取り出されることを意味します
#SELECT * FROM 表名 limit 6;
2.4 最初の 3 レコードを年齢の逆順に取得します。 Row
select * from student order by age desc limit 3;
2.5 最初の 3 行をスキップし、次の 2 行をフェッチします
select * from student order by age desc limit 3,2;
3. ディープページングの最適化戦略
方法 1: 主キー ID または一意のインデックスの最適化を使用する
つまり、最初に最後のページングの最大 ID を見つけてから、その ID のインデックスを使用します。クエリ:
SELECT * FROM test_user WHERE id>1000000 LIMIT 100; # 0.047秒
この最適化された SQL を使用すると、前のクエリよりも高速になります。すでに 11 倍高速です。主キー ID の使用に加えて、一意のインデックスを使用して特定のデータをすばやく見つけることもできるため、テーブル全体のスキャンを回避できます。以下は、1000 ~ 1019 の範囲の一意のキー (pk) を持つデータを読み取るための、対応する SQL 最適化コードです。
SELECT * FROM 表名称 WHERE pk>=1000 ORDER BY pk ASC LIMIT 0,20
理由: インデックスのスキャンは非常に高速になります。
該当するシナリオ: データがクエリされ、pk または id に従って並べ替えられ、すべてのデータが欠落していない場合は、この方法で最適化できます。そうしないと、ページング操作によってデータが漏洩します。
方法 2: インデックス カバレッジの最適化を使用する
インデックス クエリを使用するステートメントにそのインデックス列のみが含まれている場合 (つまり、インデックス カバレッジ)、そうすれば、この状況はすぐに質問されます。
インデックス カバレッジ クエリがなぜこれほど高速なのでしょうか?
回答: インデックス検索には最適化アルゴリズムがあり、データはクエリ インデックス上にあるため、関連するデータ アドレスを見つける必要がなく、時間を大幅に節約できます。同時実行量が多い場合、Mysql はインデックスに関連付けられたキャッシュも提供します。このキャッシュを最大限に活用すると、より良い結果が得られます。
id フィールドはテスト テーブル test_user の主キーであるため、主キー インデックスがデフォルトで含まれています。次に、カバリング インデックスを使用したクエリがどのように実行されるかを見てみましょう。
今回は、行 1000001 から 1000100 のデータをクエリします (カバー インデックスを使用し、id 列のみを含みます):
SELECT id FROM test_user LIMIT 1000000,100; # 0.843秒
この結果から、クエリ速度がフルテーブルスキャン速度 (もちろん、この SQL を繰り返し実行すると、複数のクエリを実行した後は速度が大幅に速くなり、時間のほぼ半分が節約されます。これはキャッシュによるものです。) 次に、 Explain コマンドを使用して SQL の実行計画を表示します。 SQL 実行共通インデックスが使用されていることを確認します idx_user_id:
EXPLAIN SELECT id FROM test_user LIMIT 1000000,100;
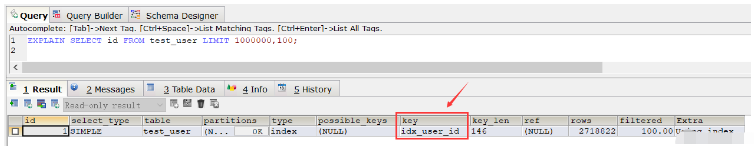
通常のインデックスを削除すると、実行時に主キー インデックスが使用されます。 SQL以上。通常のインデックスを削除しない場合、この場合、上記の SQL で主キー インデックスを使用する場合は、order by ステートメントを使用できます。
SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100; # 0.250秒
次に、すべての列もクエリしたい場合、id>= の形式で行う方法と、join を使用する方法の 2 つがあります。
最初の書き方:
SELECT * FROM test_user WHERE ID >= (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,1) LIMIT 100;
上記の SQL クエリ時間は 0.281 秒です
2 つ目の書き方:
SELECT * FROM (SELECT id FROM test_user ORDER BY id ASC LIMIT 1000000,100) a LEFT JOIN test_user b ON a.id = b.id;
上記の SQL クエリ時間は 0.252 秒です。
方法 3: インデックスに基づいて並べ替えます
PageNum はページ番号を表し、その値は 0 から始まり、pageSize はページごとのデータの数を表します。
SELECT * FROM 表名称 WHERE id_pk > (pageNum*pageSize) ORDER BY id_pk ASC LIMIT pageSize;
适应场景:
适用于数据量多的情况
最好ORDER BY后的列对象是主键或唯一索引
id数据没有缺失,可以作为序号使用
使用ORDER BY操作能利用索引被消除,但结果集是稳定的
原因:
索引扫描,速度会很快
但MySQL的排序操作,只有ASC没有DESC。在MySQL中,索引的存储顺序是升序ASC,没有降序DESC的索引。这就是为什么默认情况下,order by 是按照升序排序的原因
方法四:基于索引使用prepare
PREPARE预编译一个SQL语句,并为其分配一个名称 stmt_name,以便以后引用该语句,预编译好的语句用EXECUTE执行。
PREPARE stmt_name FROM 'SELECT * FROM test_user WHERE id > ? ORDER BY id ASC LIMIT ?'; SET @a = 1000000; SET @b = 100; EXECUTE stmt_name USING @a, @b;;

上述SQL查询时间为0.047秒。
对于定义好的PREPARE预编译语句,我们可以使用下述命令来释放该预编译语句:
DEALLOCATE PREPARE stmt_name;
原因:
索引扫描,速度会很快.
prepare语句又比一般的查询语句快一点。
方法五:利用"子查询+索引"快速定位数据
其中page表示页码,其取值从0开始;pagesize表示指的是每页多少条数据。
SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id DESC LIMIT ($page-1)*$pagesize ORDER BY id DESC LIMIT $pagesize);
方法六:利用复合索引进行优化
假设数据表 collect ( id, title ,info ,vtype) 就这4个字段,其中id是主键自增,title用定长,info用text, vtype是tinyint,vtype是一个普通索引。
现在往里面填充数据,填充10万条记录,数据库表占用硬1.6G。
select id,title from collect limit 1000,10;
执行上述SQL速度很快,基本上0.01秒就OK。
select id,title from collect limit 90000,10;
然后再执行上述SQL,就发现非常慢,基本上平均8~9秒完成。
这个时候如果我们执行下述,我们会发现速度又变的很快,0.04秒就OK。
select id from collect order by id limit 90000,10;
那么这个现象的原因是什么?
答案:因为用了id主键做索引, 这里实现了索引覆盖,当然快。
所以如果想一起查询其它列的话,可以按照索引覆盖进行优化,具体如下:
select id,title from collect where id >= (select id from collect order by id limit 90000,1) limit 10;
再看下面的语句,带上where 条件:
select id from collect where vtype=1 order by id limit 90000,10;
可以发现这个速度上也是很慢的,用了8~9秒!
这里有一个疑惑:vtype 做了索引了啊?怎么会慢呢?
vtype做了索引是不错,如果直接对vtype进行过滤:
select id from collect where vtype=1 limit 1000,10;
可以看到速度还是很快的,基本上0.05秒,如果从9万开始,那就是0.05*90=4.5秒的速度了。
其实加了 order by id 就不走索引,这样做还是全表扫描,解决的办法是:复合索引!
因此针对下述SQL深度分页优化时可以加一个search_index(vtype,id)复合索引:
select id from collect where vtype=1 order by id limit 90000,10;
综上:
在进行SQL查询深度分页优化时,如果对于有where条件,又想走索引用limit的,必须设计一个索引,将where放第一位,limit用到的主键放第二位,而且只能select 主键。
最后根据查询出的主键走一级索引找到对应的数据。
按这样的逻辑,百万级的limit 在0.0x秒就可以分完,完美解决了分页问题。
以上がMySQLチューニングにおけるSQLクエリのディープページング問題を解決する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。