
ホームページ >テクノロジー周辺機器 >AI >5 種類の機械学習アクセラレータについて簡単に説明する
5 種類の機械学習アクセラレータについて簡単に説明する

- 王林転載
- 2023-05-25 14:55:251701ブラウズ
翻訳者 | Bugatti
レビュアー | Sun Shujuan
過去 10 年間はディープラーニングの時代でした。私たちは、AlphaGo から DELL-E 2 まで、一連の大きなイベントに興奮しています。 Alexa デバイス、広告レコメンデーション、倉庫ロボット、自動運転車など、人工知能 (AI) によって駆動される無数の製品やサービスが日常生活に登場しています。

# 近年、深層学習モデルのサイズは飛躍的に増大しています。これはニュースではありません。Wu Dao 2.0 モデルには 1 兆 7,500 億のパラメーターが含まれており、SageMaker トレーニング プラットフォームの 240 ml.p4d.24xlarge インスタンスで GPT-3 をトレーニングするのにかかる時間はわずか約 25 日です。
しかし、ディープラーニングのトレーニングと導入が進化するにつれて、それはますます困難になってきています。深層学習モデルが進化するにつれて、スケーラビリティと効率がトレーニングと展開における 2 つの大きな課題になります。
この記事では、5 つの主要なタイプの機械学習 (ML) アクセラレータを要約します。
AI エンジニアリングにおける ML ライフ サイクルを理解する
ML アクセラレータを包括的な方法で導入する前に、ML ライフ サイクルを確認しておくとよいでしょう。
ML ライフ サイクルは、データとモデルのライフ サイクルです。データは ML の根幹とも言え、モデルの品質を決定します。ライフサイクルのあらゆる側面に加速の機会があります。
MLOps は、ML モデルのデプロイメントのプロセスを自動化できます。ただし、運用の性質上、AI ワークフローの水平プロセスに限定され、トレーニングと導入を根本的に改善することはできません。
AI エンジニアリングは MLOps の範囲をはるかに超えており、機械学習のワークフロー プロセスだけでなく、トレーニングとデプロイメントのアーキテクチャ全体 (水平的および垂直的) を設計できます。さらに、ML ライフサイクル全体の効率的なオーケストレーションを通じて、導入とトレーニングを加速します。
総合的な ML ライフ サイクルと AI エンジニアリングに基づいて、ML アクセラレータ (またはアクセラレーションの側面) には、ハードウェア アクセラレータ、AI コンピューティング プラットフォーム、AI フレームワーク、ML コンパイラ、クラウド サービスの 5 つの主要なタイプがあります。まずは下の関係図をご覧ください。
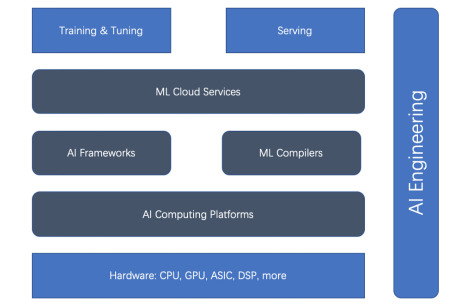
TensorFlow: TensorFlow は、主力の AI フレームワークです。 TensorFlow は、当初からディープ ラーニング オープンソース コミュニティを支配してきました。 TensorFlow Serving は、明確に定義された成熟したプラットフォームです。インターネットと IoT に関しては、TensorFlow.js と TensorFlow Lite も成熟しています。
しかし、深層学習の初期の探索には限界があるため、TensorFlow 1.x は非 Python の方法で静的グラフを構築するように設計されました。これは、研究分野で PyTorch を急速に改善できる「eager」モードを使用した即時評価の障壁になります。 TensorFlow 2.x は追いつくように努めていますが、残念ながら TensorFlow 1.x から 2.x へのアップグレードは面倒です。 TensorFlow では、全体的に使いやすくするために Keras を導入し、最下層を高速化するために最適化コンパイラーである XLA (Accelerated Linear Algebra) も導入しています。PyTorch: PyTorch は、そのイーガー モードと Python のようなアプローチにより、今日のディープ ラーニング コミュニティの主力であり、研究から運用まであらゆる場面で使用されています。 TorchServe に加えて、PyTorch は Kubeflow などのフレームワークに依存しないプラットフォームとも統合します。さらに、PyTorch の人気は、Hugging Face の Transformers ライブラリの成功と切り離すことができません。
JAX: Google は、デバイス高速化された NumPy と JIT に基づいた JAX を導入しました。 PyTorch が数年前に行ったように、これはよりネイティブな深層学習フレームワークであり、研究コミュニティで急速に人気が高まっています。しかし、Googleが主張しているように、これはまだ「公式」Google製品ではない。
2. ハードウェア アクセラレータNVIDIA の GPU がディープ ラーニング トレーニングを高速化できることは間違いありませんが、元々はビデオ カード用に設計されました。 汎用 GPU の登場後、ニューラル ネットワークのトレーニングに使用されるグラフィック カードが非常に普及しました。これらの汎用 GPU は、サブルーチンのレンダリングだけでなく、任意のコードを実行できます。 NVIDIA の CUDA プログラミング言語は、C に似た言語で任意のコードを作成する方法を提供します。汎用 GPU は、比較的便利なプログラミング モデル、大規模な並列処理メカニズム、および高いメモリ帯域幅を備えており、ニューラル ネットワーク プログラミングに理想的なプラットフォームを提供します。 現在、NVIDIA はデスクトップからモバイル、ワークステーション、モバイル ワークステーション、ゲーム コンソール、データ センターに至るまで、幅広い GPU をサポートしています。 NVIDIA GPU の大成功により、AMD の GPU や Google の TPU ASIC など、後継機が不足することはありませんでした。3. AI コンピューティング プラットフォーム
前述したように、ML のトレーニングとデプロイの速度はハードウェア (GPU や TPU など) に大きく依存します。これらのドライバー プラットフォーム (つまり、AI コンピューティング プラットフォーム) はパフォーマンスにとって重要です。 AI コンピューティング プラットフォームには、CUDA と OpenCL という 2 つのよく知られたプラットフォームがあります。
CUDA: CUDA (Compute Unified Device Architecture) は、2007 年に NVIDIA によってリリースされた並列プログラミング パラダイムです。グラフィックス プロセッサおよび GPU 上の多数の汎用アプリケーション向けに設計されています。 CUDA は、NVIDIA の Tesla アーキテクチャ GPU のみをサポートする独自の API です。 CUDA がサポートするグラフィックス カードには、GeForce 8 シリーズ、Tesla、Quadro が含まれます。
OpenCL: OpenCL (オープン コンピューティング言語) は元々 Apple によって開発され、現在は CPU、GPU、DSP、その他のタイプのプロセッサを含むヘテロジニアス コンピューティングのために Khronos チームによって保守されています。このポータブル言語は、Nvidia の GPU を含むあらゆるハードウェア プラットフォームで高いパフォーマンスを実現するのに十分な適応性を備えています。
NVIDIA は、R465 以降のドライバーで使用できる OpenCL 3.0 に準拠しました。 OpenCL API を使用すると、C プログラミング言語の限定されたサブセットで書かれた計算カーネルを GPU 上で起動できます。
4. ML コンパイラー
ML コンパイラーは、トレーニングとデプロイメントを加速する上で重要な役割を果たします。 ML コンパイラーは、大規模なモデルのデプロイメントの効率を大幅に向上させることができます。 Apache TVM、LLVM、Google MLIR、TensorFlow XLA、Meta Glow、PyTorch nvFuser、Intel PlaidML などの一般的なコンパイラが多数あります。
5. ML クラウド サービス
ML クラウド プラットフォームとサービスは、クラウド内の ML プラットフォームを管理します。効率を高めるために、いくつかの方法で最適化できます。
Amazon SageMaker を例に挙げます。これは、主要な ML クラウド プラットフォーム サービスです。 SageMaker は、準備、構築、トレーニング/チューニングから展開/管理に至るまで、ML ライフサイクルの幅広い機能を提供します。
GPU 上のマルチモデル エンドポイント、異種クラスターを使用したコスト効率の高いトレーニング、CPU ベースの ML 推論に適した独自の Graviton プロセッサなど、トレーニングとデプロイメントの効率を向上させるために多くの側面を最適化します。
結論
ディープラーニングのトレーニングと導入の規模が拡大し続けるにつれて、課題はますます困難になってきています。ディープラーニングのトレーニングと導入の効率を向上させるのは複雑です。 ML ライフサイクルに基づいて、ML のトレーニングと展開を加速できる 5 つの側面があります。それは、AI フレームワーク、ハードウェア アクセラレータ、コンピューティング プラットフォーム、ML コンパイラー、クラウド サービスです。 AI エンジニアリングはこれらすべてを調整し、エンジニアリング原則を使用して全体的な効率を向上させることができます。
原題: 5 Types of ML Accelerators 、著者: Luhui胡
以上が5 種類の機械学習アクセラレータについて簡単に説明するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。