
ホームページ >テクノロジー周辺機器 >AI >ビデオセグメンテーションのフィナーレ!浙江大学は最近 SAM-Track をリリースしました: ワンクリックでユニバーサルなインテリジェントビデオセグメンテーション
ビデオセグメンテーションのフィナーレ!浙江大学は最近 SAM-Track をリリースしました: ワンクリックでユニバーサルなインテリジェントビデオセグメンテーション

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-23 14:07:061502ブラウズ
最近、浙江大学の ReLER 研究室は、SAM とビデオ セグメンテーションを深く組み合わせ、Segment-and-Track Anything (SAM-Track) をリリースしました。
SAM-Track は、SAM にビデオ ターゲットを追跡する機能を提供し、複数のインタラクション方法 (ポイント、ブラシ、テキスト) をサポートします。
これに基づいて、SAM-Track は複数の従来のビデオ セグメンテーション タスクを統合し、ワンクリックであらゆるビデオ内のあらゆるターゲットのセグメンテーションと追跡を実現し、従来のビデオ セグメンテーションをユニバーサルなビデオ セグメンテーションに推定します。
SAM-Track は優れたパフォーマンスを備えており、複雑なシナリオでも 1 枚のカードで数百のターゲットを高品質で安定して追跡できます。

プロジェクトアドレス: https://github.com/z-x-yang/Segment-and-Track -Anything
##論文アドレス: https://arxiv.org/abs/2305.06558
エフェクト表示SAM-Track は、プロンプトとしての言語入力をサポートしています。たとえば、カテゴリ テキスト「パンダ」がある場合、ワンクリックのインスタンス レベルのセグメンテーションを使用して、カテゴリ「パンダ」に属するすべてのターゲットを追跡できます。

「左端のパンダ」というテキストを入力するなど、より詳細な説明を入力することもできます。SAM-Trackセグメンテーション追跡の特定のターゲットを見つけることができます。

従来のビデオ追跡アルゴリズムと比較して、SAM-Track のもう 1 つの強力な特徴は、多数のビデオ トラッキング アルゴリズムをターゲットにできることです。追跡セグメンテーションを実行し、出現するオブジェクトを自動的に検出します。

SAM-Track は、複数の対話型メソッドの組み合わせもサポートしており、ユーザーは実際のニーズに応じてそれらを組み合わせることができます。たとえば、ブラシを使用して人体に密接に関係するスケートボードのフレームを作成し、冗長なオブジェクトのセグメント化を防ぎ、クリックを使用して人体を選択します。
全自動のビデオ ターゲットのセグメンテーションと追跡が当然の問題になります。ストリート ビュー、航空写真、AR、アニメーション、医療画像などのさまざまなアプリケーション シナリオはすべてセグメント化できます。ワンクリックで自動的に追跡され、出現するオブジェクトを検出します。


 #ユーザーのオンライン エクスペリエンスを容易にするために、このプロジェクトでは、Colab を介してワンクリックでデプロイできる WebUI を提供します。
#ユーザーのオンライン エクスペリエンスを容易にするために、このプロジェクトでは、Colab を介してワンクリックでデプロイできる WebUI を提供します。
モデル構成
SAM-Track モデルは、ECCV'22 VOT ワークショップの 4 トラックチャンピオンシップスキーム DeAOT に基づいています。
DeAOT は効率的な多目的 VOS モデルであり、最初のフレームのオブジェクト アノテーションが与えられると、ビデオの残りのフレーム内のオブジェクトを追跡してセグメント化できます。
DeAOT は、認識メカニズムを使用してビデオ内の複数のターゲットを同じ高次元空間に埋め込み、それによって複数のオブジェクトの同時追跡を実現します。
DeAOT の複数オブジェクト追跡における速度パフォーマンスは、単一オブジェクト追跡の他の VOS 方式と同等です。
さらに、DeAOT は、階層化された Transformer ベースの伝播メカニズムを通じて、長期情報と短期情報をより適切に集約し、優れた追跡パフォーマンスを示します。
DeAOT では初期化に参照フレームのアノテーションが必要なため、利便性を高めるために、SAM-Track では最近画像分野で話題になっている Segment Anything Model (SAM) モデルを使用しています。ラベル情報を取得するためのセグメンテーション。
SAM の優れたゼロサンプル マイグレーション機能と複数のインタラクション手法を使用して、SAM-Track は DeAOT の高品質の参照フレーム アノテーション情報を効率的に取得できます。
SAM モデルは画像セグメンテーションの分野では良好に機能しますが、セマンティック ラベルを出力できず、テキスト プロンプトはオブジェクトのセグメンテーションの参照や、セマンティックの深い理解に依存するその他のタスクを十分にサポートできません。
したがって、SAM-Track モデルは、Grounding-DINO をさらに統合して、高精度の言語ガイド付きビデオ セグメンテーションを実現します。 Grounding DINO は、優れた言語理解機能を備えたオープンセットの物体検出モデルです。
入力カテゴリまたはターゲット オブジェクトの詳細な説明に基づいて、Grounding-DINO はターゲットを検出し、ロケーション ボックスを返すことができます。
SAM-Track モデル アーキテクチャ
下の図に示すように、SAM-Track モデルは、対話型追跡モード、自動追跡モード、およびフュージョンモード。
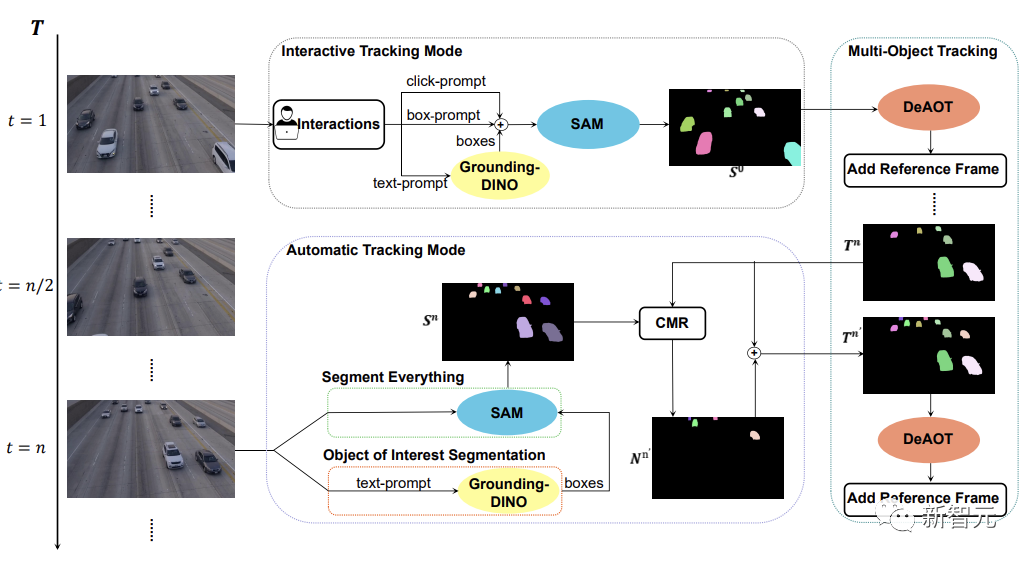
インタラクティブ トラッキング モードの場合、SAM-Track モデルはまず、参照フレーム内のクリックまたはフレームを使用して SAM を適用します。このようにして、ユーザーが満足するインタラクティブなセグメンテーション結果が得られるまでターゲットを絞り込みます。
言語ガイド付きビデオ オブジェクト セグメンテーションを実装する場合、SAM-Track は入力テキストに基づいて Grounding-DINO を呼び出し、まずターゲット オブジェクトの位置フレームを取得します。 SAM を通じて対象オブジェクトのセグメンテーション結果を取得します。
最後に、DeAOT は、選択されたターゲットを追跡するための参照フレームとしてインタラクティブ セグメンテーションの結果を使用します。追跡プロセス中に、DeAOT は、過去のフレームに埋め込まれた視覚的埋め込みと高次元 ID 埋め込みを現在のフレームに階層的に伝播させ、複数のターゲット オブジェクトのフレームごとの追跡とセグメンテーションを実現します。したがって、SAM-Track は、マルチモーダル インタラクションをサポートすることで、セグメント化されたビデオ内の対象オブジェクトを追跡できます。
ただし、インタラクティブ追跡モードでは、ビデオ内に出現する新たに出現したオブジェクトを処理できません。自動運転、スマートシティなどの特定の分野での SAM-Track の適用を制限します。
SAM-Track の適用範囲とパフォーマンスをさらに拡張するために、SAM-Track はビデオに表示される新しいオブジェクトを追跡する自動追跡モードを実装しています。
自動追跡モードは、すべてをセグメント化および対象オブジェクトのセグメント化を使用して、n フレームごとに出現する新しいオブジェクトの注釈を取得します。新しく出現したオブジェクトの ID 割り当ての問題については、SAM-Track は比較マスク モジュール (CMR) を使用して新しいオブジェクトの ID を決定します。
フュージョン モードは、インタラクティブ トラッキング モードと自動トラッキング モードを組み合わせたものです。インタラクティブ トラッキング モードでは、ビデオの最初のフレームの注釈を簡単に取得できます。一方、自動トラッキング モードでは、ビデオの後続のフレームに表示される選択されていない新しいオブジェクトを処理します。追跡方法を組み合わせることで、SAM-Track の適用範囲が広がり、SAM-Track の実用性が高まります。
以上がビデオセグメンテーションのフィナーレ!浙江大学は最近 SAM-Track をリリースしました: ワンクリックでユニバーサルなインテリジェントビデオセグメンテーションの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。