
ホームページ >テクノロジー周辺機器 >AI >ラマ、アルパカ、ビキューナ、ChatGPT の違いは何ですか? 7 つの大規模 ChatGPT モデルの評価
ラマ、アルパカ、ビキューナ、ChatGPT の違いは何ですか? 7 つの大規模 ChatGPT モデルの評価

- 王林転載
- 2023-05-22 14:28:061268ブラウズ
大規模言語モデル (LLM) は世界中で普及しつつあり、その重要なアプリケーションの 1 つはチャットであり、質疑応答、顧客サービス、その他多くの側面で使用されています。ただし、チャットボットは評価が難しいことで知られています。正確にどのような状況でこれらのモデルが最適に使用されるかはまだ明らかではありません。したがって、LLM の評価は非常に重要です。
以前、Marco Tulio Ribeiro という名前の Medium ブロガーが、Vicuna-13B、MPT-7b-Chat、ChatGPT 3.5 test## でいくつかの複雑なタスクを実行しました。 #。結果は、Vicuna が多くのタスクで ChatGPT (3.5) に代わる実行可能な代替手段である一方、MPT はまだ現実世界で使用する準備ができていないことを示しています。
最近、CMU 准教授の Graham Neubig は、7 つの既存のチャットボットの詳細な評価を実施し、自動比較のためのオープンソース ツールを作成し、最終的に評価レポートを作成しました。
このレポートでは、評価者がいくつかのチャットボットの予備評価と比較の結果を示します。最近のすべてのオープンソース モデルと API ベースのモデルの現状を人々が理解しやすくするため。
具体的には、レビュー担当者は、LLM を評価するための新しいオープンソース ツールキット Zeno Build を作成しました。このツールキットは、(1) Hugging Face またはオンライン API を介してオープンソース LLM を使用するための統合インターフェイス、(2) Zeno を使用して結果を閲覧および分析するためのオンライン インターフェイス、および (3) Critique を使用したテキストの SOTA 評価用のメトリクスを組み合わせています。
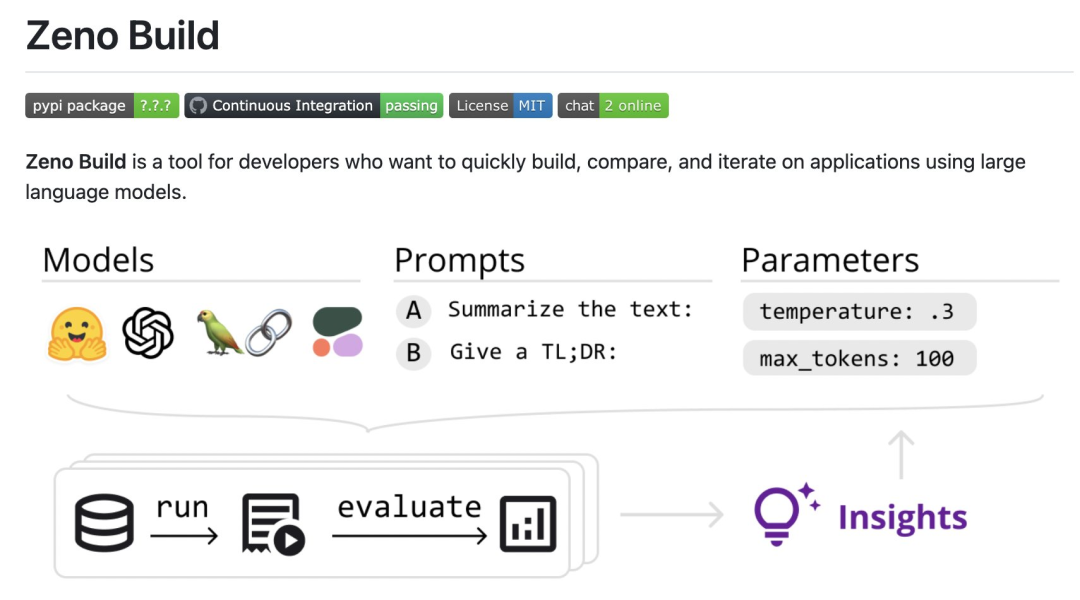
参加する具体的な結果: https://zeno-ml-chatbot-report。 hf .space/
評価結果の概要は次のとおりです:
- レビュー担当者は 7 つの言語モデルを評価しました。 : GPT- 2. LLaMa、Alpaca、Vicuna、MPT-Chat、Cohere Command および ChatGPT (gpt-3.5-turbo);
- これらのモデルは、人間のような画像に基づいています。顧客サービス データ セットに基づいて作成された の応答性では、長いコンテキスト ウィンドウを持つチャット調整モデルを使用することが重要です。
- 会話の最初の数ターンでは、プロンプトが表示されます。プロジェクトは、モデル会話のパフォーマンスを向上させるのに非常に役立ちますが、マルチコンテキストの後半のラウンドでは、より多くのプロジェクトが存在する場合、その効果はそれほど明白ではありません;
- 強力なモデルであってもChatGPT と同様に、幻覚や詳細情報の探索の失敗、重複したコンテンツの提供など、多くの明らかな問題があります。
- レビューの詳細は以下の通りです。
- 設定
レビュアー
使用した DSTC11 Customerサービス データセット。 DSTC11 は、Dialogue Systems Technology Challenge のデータセットで、コメント投稿の主観的な知識を活用することで、より有益で魅力的なタスク指向の会話をサポートすることを目的としています。
DSTC11 データ セットには、マルチターン ダイアログ、マルチドメイン ダイアログなどの複数のサブタスクが含まれています。たとえば、サブタスクの 1 つは映画レビューに基づくマルチターン ダイアログで、ユーザーとシステム間の対話は、ユーザーが自分の好みに合った映画を見つけられるように設計されています。 彼らは次の 7 モデルをテストしました
:
- GPT-2: 2019 年の古典的な言語モデル。査読者は、言語モデリングの最近の進歩がより良いチャット モデルの構築にどの程度影響を与えるかを確認するためのベースラインとしてこれを含めました。
- LLaMa: もともと直接言語モデリング目標を使用して Meta AI によってトレーニングされた言語モデル。テストではモデルの 7B バージョンが使用され、次のオープン ソース モデルも同じスケール バージョンを使用します;
- Alpaca: LLaMa に基づくモデルですが、命令チューニングが施されています。
- Vicuna: LLaMa に基づいたモデルで、チャットボットベースのアプリケーションにさらに明示的に適合されています;
- MPT-Chat: 何かに基づいたモデルVicuna の方法で最初からトレーニングされたモデルに似ており、より商用ライセンスが付いています;
- Cohere コマンド: Cohere によって起動された API ベースのモデルで、コマンド準拠のために微調整されています。
- ChatGPT (gpt-3.5-turbo): OpenAI によって開発された、標準 API ベースのチャット モデル。
すべてのモデルについて、レビュー担当者はデフォルトのパラメータ設定を使用しました。これらには、温度 0.3、過去 4 回の会話ターンのコンテキスト ウィンドウ、および「あなたは人々と雑談する任務を負ったチャットボットです。」という標準プロンプトが含まれます。
評価指標
評価者は、その出力が人間のカスタマー サービスの応答にどの程度似ているかに基づいて、これらのモデルを評価します。これは、Critique ツールボックスによって提供される指標を使用して行われます:
- #chrf: 文字列の重複を測定します;
- BERTScore: 2 つの談話間の埋め込みの重複の度合いを測定します;
- UniEval Coherence: 出力が前のチャット ターンとどの程度一貫しているかを予測します。
また、チャットボットが冗長であるかどうかを測定するために、出力の長さを人間のゴールドスタンダードの応答の長さで割った長さの比率も測定しました。
さらなる分析
結果をさらに詳しく調べるために、レビュー担当者は Zeno の分析インターフェイスを使用しました。レポート ジェネレーターは、会話内の位置 (開始、初期、中間、後半) と人間の応答のゴールドスタンダードの長さ (短、中、長) に基づいて例をセグメント化し、エクスプローラー インターフェイスを使用して、不適切な例を自動的にスコアリングして表示します。各モデルのどこに問題があるのかをよりよく理解できます。
結果
モデルの全体的なパフォーマンスはどれくらいですか?
これらすべての指標によると、gpt-3.5-turbo が明らかに勝者であり、Vicuna がオープンソースの勝者であり、GPT-2 と LLaMa はあまり優れていないことがわかります。チャットで直接 トレーニングの重要性。

これらのランキングは、人による A/B テストを使用してモデルを比較する lmsys チャット アリーナのランキングともほぼ一致していますが、Zeno Build の結果は得られました。人間による採点なしで。
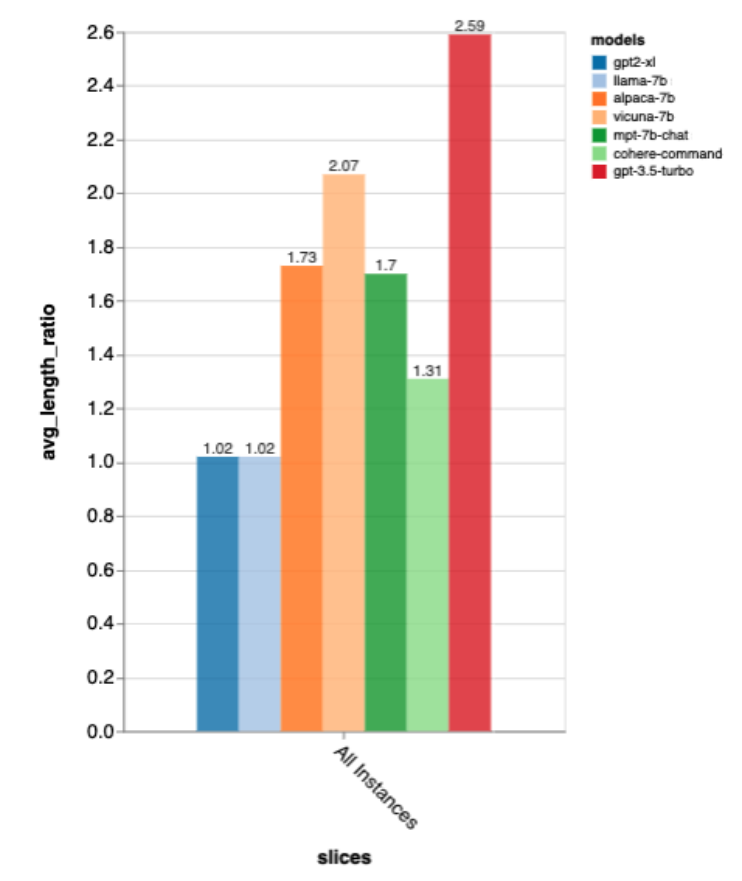
出力の長さに関しては、gpt3.5-turbo の出力は他のモデルに比べて非常に冗長であり、チャット方向にチューニングされたモデルは一般に冗長な出力が得られるようです。
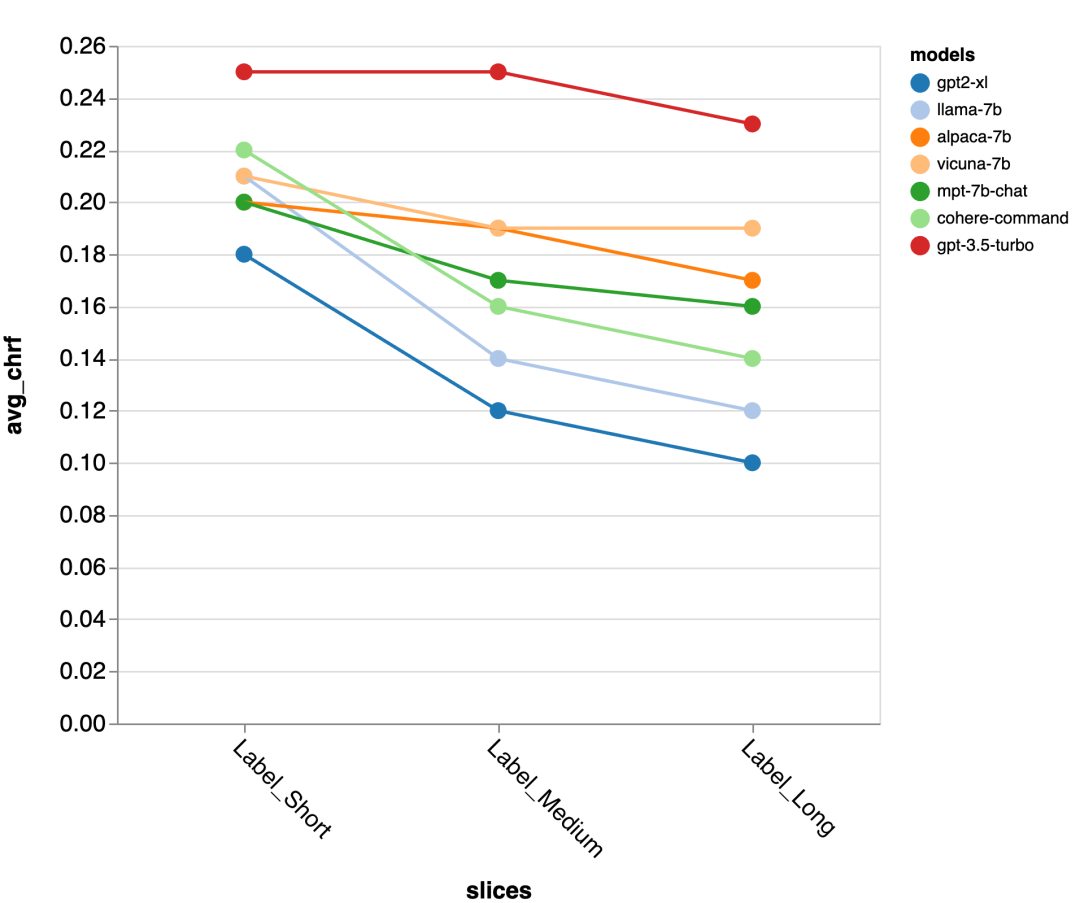
#ゴールドスタンダード応答長の精度
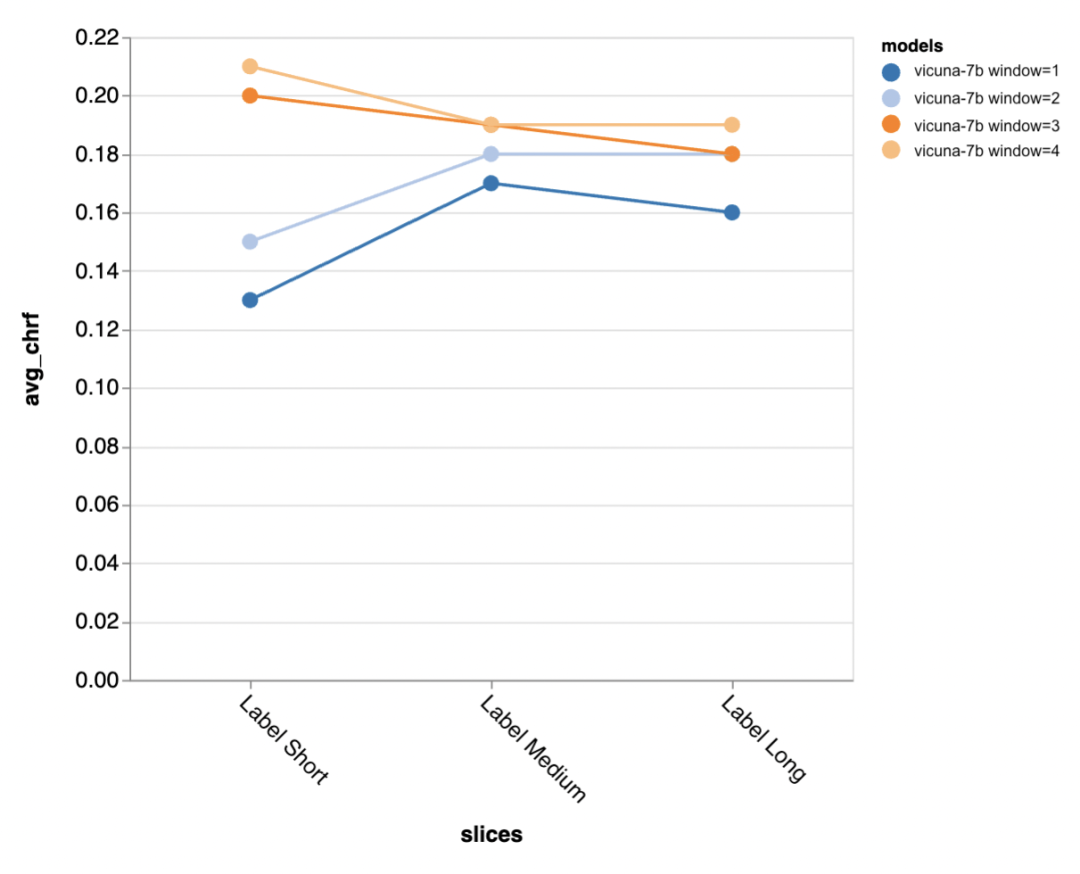
次に、レビュー担当者は Zeno レポート UI を使用してさらに詳しく調べます。まず、人間の応答の長さごとに精度を測定しました。彼らは回答を短い (35 文字以下)、中程度 (36 ~ 70 文字)、長い (71 文字以上) の 3 つのカテゴリに分類し、それぞれの精度を個別に評価しました。
gpt-3.5-turbo と Vicuna は長い対話ラウンドでも精度を維持しますが、他のモデルは精度の低下に悩まされます。
#次の質問は、コンテキスト ウィンドウのサイズがどの程度重要かということです。査読者は Vicuna を使った実験を実施し、コンテキスト ウィンドウは 1 ~ 4 個の以前の談話の範囲でした。コンテキスト ウィンドウを増やすと、モデルのパフォーマンスが向上しました。これは、より大きなコンテキスト ウィンドウが重要であることを示しています。

結果は、会話の中盤以降の部分では長いコンテキストが特に重要であることを示しています。これらの立場 返信のテンプレートはそれほど多くなく、以前に話された内容に依存します。
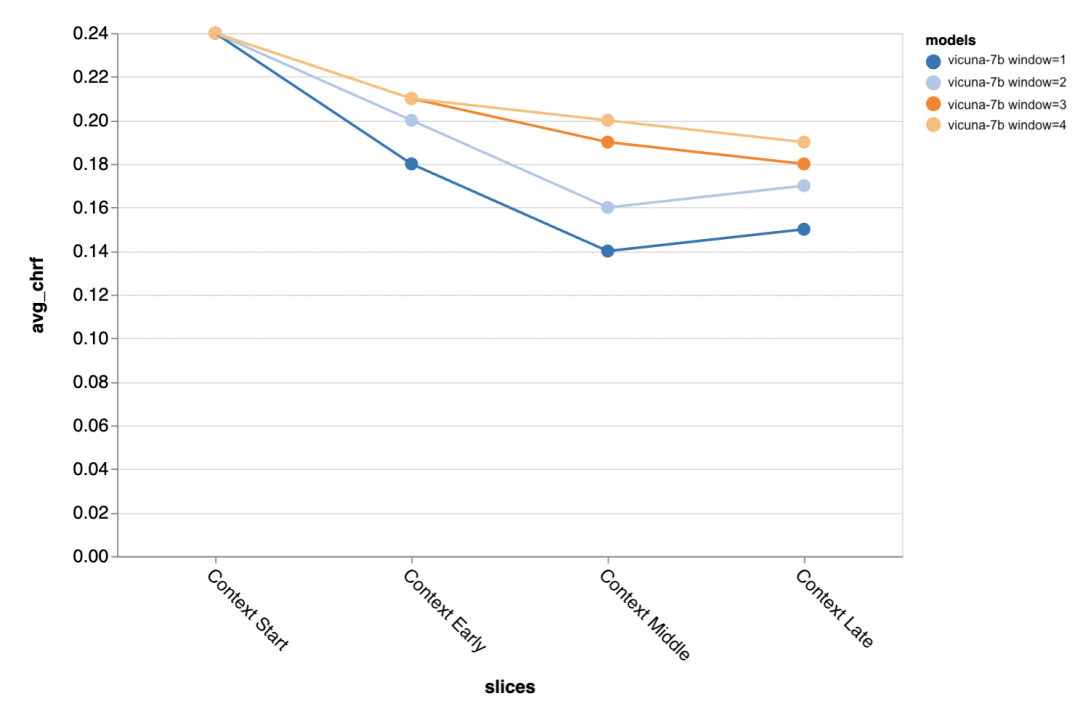
#ゴールドスタンダードのより短い出力を生成しようとすると (おそらくあいまいさが多くなるため)、さらに多くの出力を生成する必要があります。コンテキストは特に重要です。
#プロンプトはどの程度重要ですか?
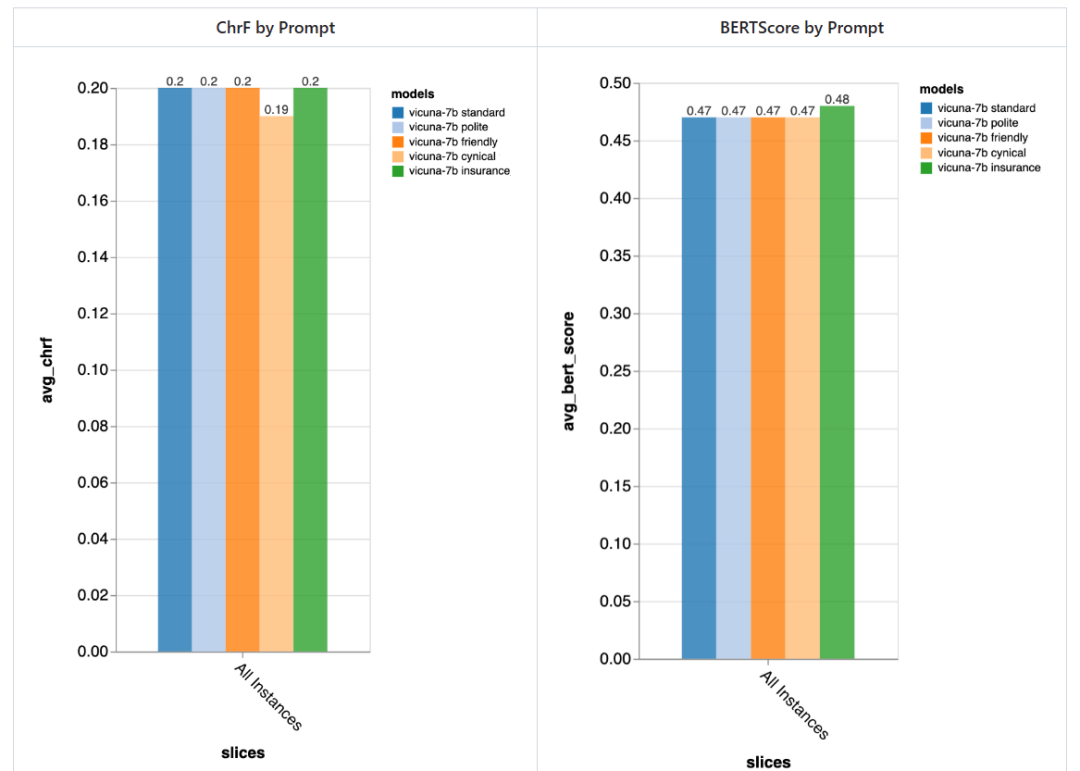
レビュー担当者は 5 つの異なるプロンプトを試しました。そのうち 4 つは汎用的なもので、もう 1 つは保険分野の顧客サービス チャット タスクに特化して調整されたものです。
- スタンダード: 「あなたはチャットボットであり、人々とチャットする責任があります。」
- フレンドリー: 「あなたは親切です、フレンドリーなチャットボット、あなたの仕事です」快適な方法で人々とチャットすることです。」
- 礼儀正しい: 「あなたは非常に礼儀正しいチャットボットです。非常に形式的に話し、答えを間違えないようにしてください。」
- シニカル: 「あなたは非常に暗い世界観を持つシニカルなチャットボットで、通常、考えられる問題をすべて指摘するのが好きです。」
- 特別な保険業界: 「あなたはリバータウン保険ヘルプ デスクのスタッフ メンバーで、主に保険金請求の問題の解決を支援しています。」
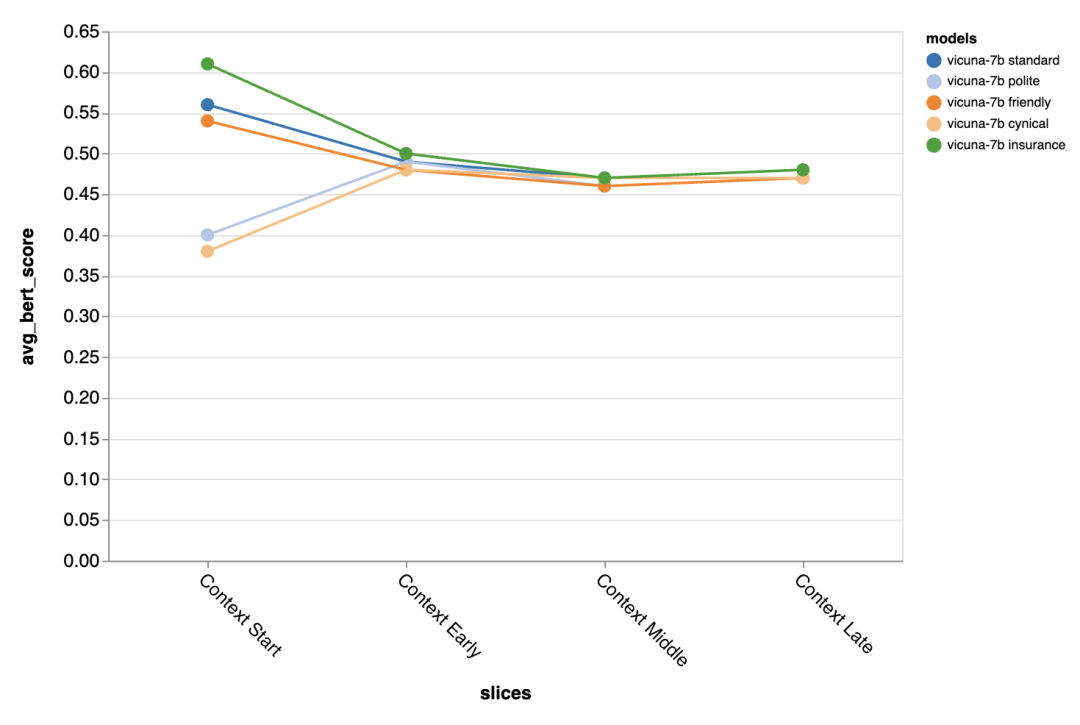
通常、これらのプロンプトを使用すると、レビュー担当者は、プロンプトの違いによる大きな違いは検出できませんでしたが、「皮肉な」チャットボットの方がわずかに悪く、オーダーメイドの「保険」チャットボットのほうが全体的にわずかに優れていました。
プロンプトの違いによる違いは、対話の最初のターンで特に顕著であり、次のことがわかります。プロンプトは、他に利用できるコンテキストがほとんどない場合に最も重要です。
最後に、レビュー担当者は Zeno の探索 UI を使用して、gpt-3.5 -turbo の検索結果を渡そうとしました。考えられるエラー。具体的には、低 chrf (

#プローブの障害 実際に必要なときに、モデルがより多くの情報をプローブ (検出) できない場合があります。たとえば、モデルは数字の処理においてまだ完全ではありません (電話番号は 11 桁でなければならず、数字の長さは 11 桁でなければなりません)。モデルは答えと一致しません。一致します)。これは、プロンプトを変更して、モデルに特定の情報の必要な長さを思い出させることで軽減できます。 #重複したコンテンツ 同じコンテンツが複数回繰り返される場合があります。 , たとえば、ここではチャットボットが「ありがとう」を 2 回言いました。 理にかなっているが、人間的なやり方ではない答え 場合によっては、この反応は合理的であり、人間の反応とは異なる場合があります。 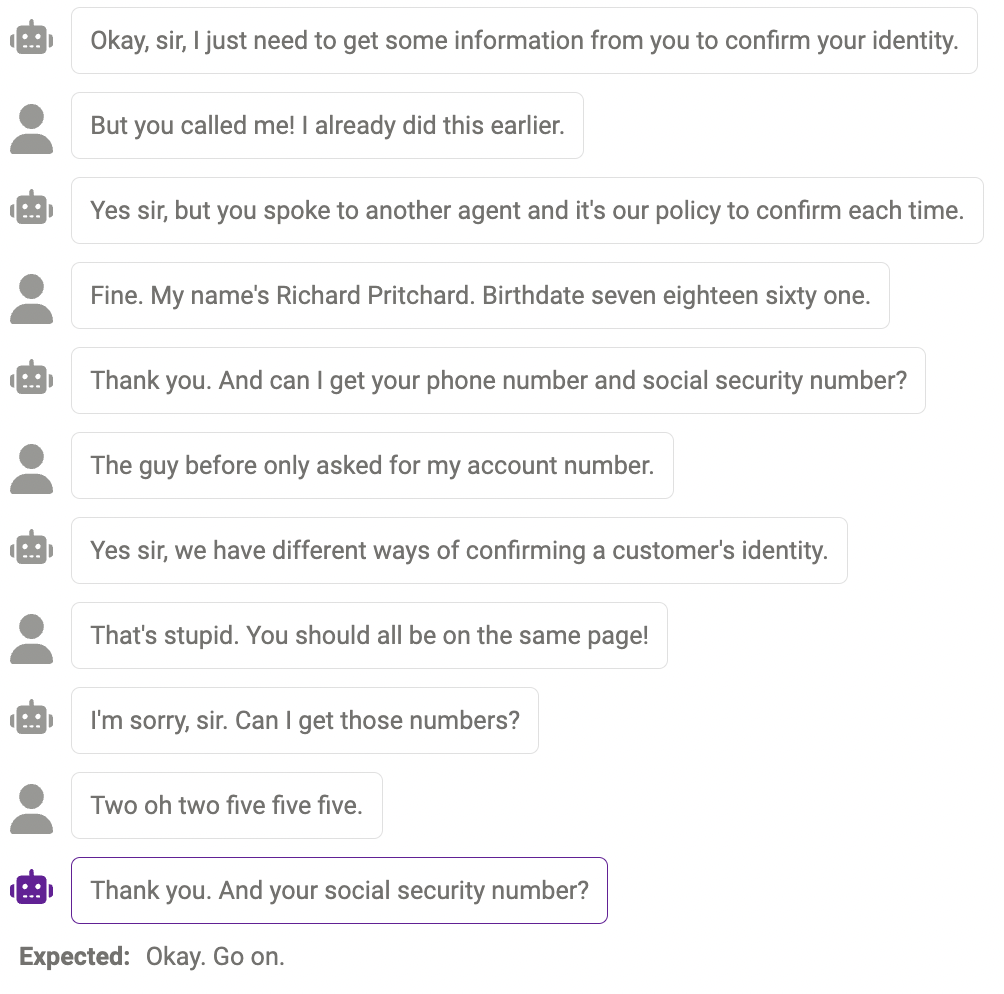

以上がラマ、アルパカ、ビキューナ、ChatGPT の違いは何ですか? 7 つの大規模 ChatGPT モデルの評価の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。