
ホームページ >バックエンド開発 >Python チュートリアル >tensorflow を使用して Python で長期短期記憶 LSTM を構築する方法
tensorflow を使用して Python で長期短期記憶 LSTM を構築する方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-22 12:32:141457ブラウズ
LSTM の紹介
1. RNN の勾配消失問題
これまでに RNN リカレント ニューラル ネットワークについて学習しましたが、その構造図は次のとおりです:
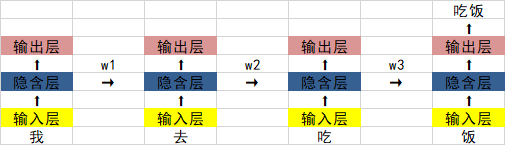
最大の問題は、w1、w2、w3 の値が 0 未満の場合、文が十分に長い場合、ニューラル ネットワークが逆伝播を実行するときに発生することです。順伝播では、勾配消失の問題が発生します。
0.925=0.07。文に 20 ~ 30 単語がある場合、最初の単語の隠れ層出力は最後の単語の出力より 0.07 倍大きくなり、影響は大幅に軽減されます。
具体的な状況は次のとおりです。
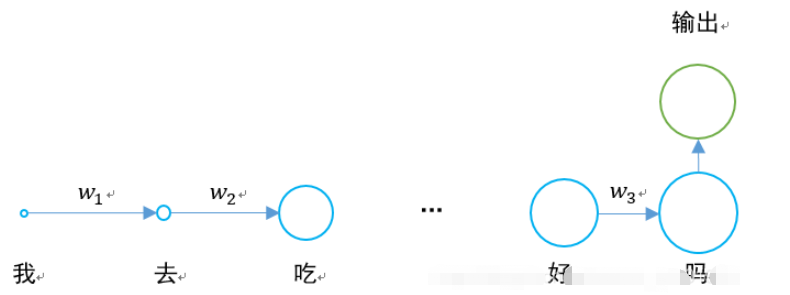
長期短期記憶ネットワークは、勾配消失の問題を解決するために登場しました。
2. LSTM の構造
元の RNN の隠れ層には、最初から最後まで渡される状態 h が 1 つだけあり、短期間の入力に非常に敏感です。
別の状態 c を追加して、長期状態を保存できるようにすると、問題は解決できます。
RNN と LSTM の場合、2 つのステップ ユニットの比較は次のとおりです。

時間次元に従って LSTM の構造を拡張します。
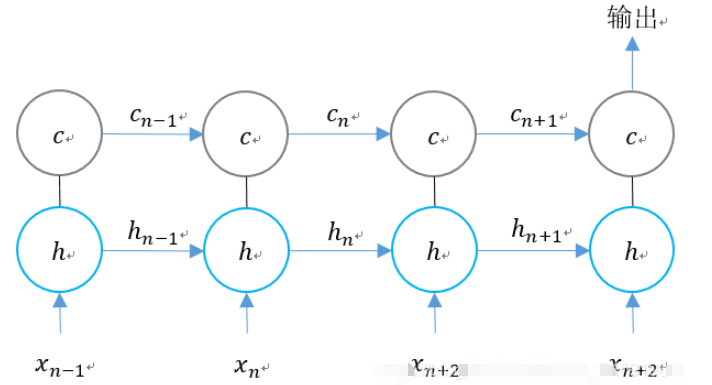
n 時間で次のようになります。 LSTM 3 つの入力があります:
1. 現時点でのネットワークの入力値;
2. 出力直前の時点の LSTM の値 ;
3. 直前の時点のユニットの状態。
LSTM には 2 つの出力があります:
1. 現時点での LSTM 出力値;
2. 現時点でのユニットのステータス。
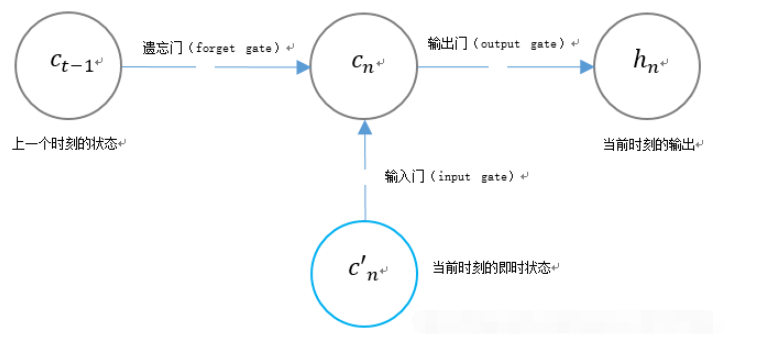
3. LSTM のユニークなゲート構造
LSTM は、ユニット状態 cn の内容を制御するために 2 つのゲートを使用します:
1. 忘却ゲート(忘却ゲート)、前の瞬間のユニット状態 cn-1 が現在の瞬間までどれだけ保持されるかを決定します;
2. 入力ゲート (入力ゲート) 、現時点でのネットワークの入力信号のどれだけがユニット状態に保存されるかを決定します。
LSTM は、ゲートを使用して現在の出力値 hn の内容を制御します。
出力ゲート (出力ゲート)。これは、ユニット状態 cn を決定します。現時点での出力の量。
tensorflow における LSTM の関連関数
tf.contrib.rnn.BasicLSTMCell
tf.contrib.rnn.BasicLSTMCell(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None
)num_units: RNN ユニットの数ニューロンの数、つまり出力ニューロンの数。
forget_bias: 忘却ゲートにバイアスを追加しました。復元された CudnnLSTM トレーニング チェックポイントを手動で 0.0 に設定します。
state_is_tuple: True の場合、受け入れられる状態と返される状態は c_state と m_state の 2 つのタプルであり、False の場合、それらは列軸に沿って接続されます。 False は廃止されようとしています。
activation: アクティベーション関数。
reuse: 既存のスコープ内の変数を再利用するかどうかを記述します。既存のスコープに指定された変数がすでに存在し、それが True でない場合、エラーが発生します。
name: レイヤーの名前。
dtype: このレイヤーのデータ型。
使用する場合は、次のように定義できます:
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
定義が完了したら、状態を初期化できます:
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
tf.nn.dynamic_rnn
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
) セル: 上記で定義した lstm_cell。
入力: RNN 入力。 time_major==false (デフォルト) の場合、形状のテンソル: [batch_size, max_time, …]、またはそのような要素のネストされたタプルである必要があります。 time_major==true の場合、それは形状 [max_time,batch_size,…] のテンソル、またはそのような要素のネストされたタプルである必要があります。
ベクトルのサイズは sequence_length パラメーターによって決まり、その型は Int32/Int64 です。バッチ要素のシーケンス長を超えた場合に、ステータスとゼロ出力をコピーするために使用されます。したがって、正確さよりもパフォーマンスが重要です。
initial_state: _init_state は上記で定義されています。
dtype: データ型。
Parallel_iterations: 並行して実行する反復の数。これらの操作は時間に依存せず、並行して実行できるものになります。このパラメータは時間を空間と引き換えにします。値が大きいほどメモリ消費量は多くなりますが、動作は速くなります。値が小さいほどメモリ使用量は少なくなりますが、必要な計算時間は長くなります。
time_major:输入和输出tensor的形状格式。这些张量的形状必须为[max_time, batch_size, depth],若表述正确,则它为真。这些张量的形状必须是[batch_size,max_time,depth],如果为假。time_major=true可以提高效率,因为它避免了在RNN计算的开头和结尾进行转置操作。默认情况下,此函数为False,因为大多数的 TensorFlow 数据以批处理主数据的形式存在。
scope:创建的子图的可变作用域;默认为“RNN”。
在LSTM的最后,需要用该函数得出结果。
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn( lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
返回的是一个元组 (outputs, state):
outputs:LSTM的最后一层的输出,是一个tensor。如果为time_major== False,则它的shape为[batch_size,max_time,cell.output_size]。如果为time_major== True,则它的shape为[max_time,batch_size,cell.output_size]。
states:states是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, cell.output_size],但当输入的cell为BasicLSTMCell时,states的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。
整个LSTM的定义过程为:
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out全部代码
该例子为手写体识别例子,将手写体的28行分别作为每一个step的输入,输入维度均为28列。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
BATCH_SIZE = 256 # 每一个batch的数据数量
TIME_STEPS = 28 # 图像共28行,分为28个step进行传输
INPUT_SIZE = 28 # 图像共28列
OUTPUT_SIZE = 10 # 共10个输出
CELL_SIZE = 256 # RNN 的 hidden unit size,隐含层神经元的个数
LR = 1e-3 # learning rate,学习率
def get_batch(): #获取训练的batch
batch_xs,batch_ys = mnist.train.next_batch(BATCH_SIZE)
batch_xs = batch_xs.reshape([BATCH_SIZE,TIME_STEPS,INPUT_SIZE])
return [batch_xs,batch_ys]
class LSTMRNN(object): #构建LSTM的类
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
#输入输出
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, output_size], name='ys')
#直接加层
with tf.variable_scope('in_hidden'):
self.add_input_layer()
#增加LSTM的cell
with tf.variable_scope('LSTM_cell'):
self.add_cell()
#直接加层
with tf.variable_scope('out_hidden'):
self.add_output_layer()
#计算损失值
with tf.name_scope('cost'):
self.compute_cost()
#训练
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
#正确率计算
self.correct_pre = tf.equal(tf.argmax(self.ys,1),tf.argmax(self.pred,1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_pre,tf.float32))
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out
def compute_cost(self):
self.cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = self.pred,labels = self.ys)
)
def _weight_variable(self, shape, name='weights'):
initializer = np.random.normal(0.0,1.0 ,size=shape)
return tf.Variable(initializer, name=name,dtype = tf.float32)
def _bias_variable(self, shape, name='biases'):
initializer = np.ones(shape=shape)*0.1
return tf.Variable(initializer, name=name,dtype = tf.float32)
if __name__ == '__main__':
#搭建 LSTMRNN 模型
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#训练10000次
for i in range(10000):
xs, ys = get_batch() #提取 batch data
if i == 0:
#初始化data
feed_dict = {
model.xs: xs,
model.ys: ys,
}
else:
feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}
#训练
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
#打印精确度结果
if i % 20 == 0:
print(sess.run(model.accuracy,feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}))以上がtensorflow を使用して Python で長期短期記憶 LSTM を構築する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。