



技術的背景
前回のブログでは、vaex データなどの大規模なデータ処理に焦点を当て、python3 を使用して表形式データを処理するいくつかの方法を紹介しました。加工計画。このデータ処理ソリューションはメモリ マップ テクノロジに基づいています。メモリ マップ ファイルを作成することで、ソース データをメモリに直接ロードすることによって引き起こされる大規模なメモリ使用量の問題を回避します。これにより、大規模な処理ではないローカル コンピュータのメモリ サイズを使用できるようになります。非常に大規模な条件下でのデータ。 Python 3 には、メモリ マップ ファイルを直接作成するために使用できる mmap と呼ばれるライブラリがあります。
tracemalloc を使用して Python プログラムのメモリ使用量を追跡する
ここでは、メモリ マッピング テクノロジの実際のメモリ使用量を比較したいため、Python ベースのメモリ追跡ツール、tracemalloc を導入する必要があります。まず簡単な例を見てみましょう。つまり、ランダムな配列を作成し、その配列が占有するメモリ サイズを観察してみましょう。
# tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
length=10000
test_array=np.random.randn(length) # 分配一个定长随机数组
snapshot=tracemalloc.take_snapshot() # 内存摄像
top_stats=snapshot.statistics('lineno') # 内存占用数据获取
print ('[Top 10]')
for stat in top_stats[:10]: # 打印占用内存最大的10个子进程
print (stat)出力結果は次のとおりです。
[dechin] @dechin-manjaro mmap ]$ python3 tracem.py
[トップ 10]
tracem.py:8: サイズ = 78.2 KiB、カウント = 2、平均 = 39.1 KiB
If top コマンドを使用します。メモリを直接検出したい場合は、Google Chrome がメモリの割合が最も高いことは間違いありません:
top - 10:04:08 6 日、15: 18、5 ユーザー、負荷平均: 0.23、0.33、0.27
タスク: 合計 309、実行中 1、スリープ 264、停止 23、ゾンビ 21
%Cpu(s): 0.6 us、0.2 sy、0.0 ni、 99.0 id、0.0 wa、0.0 hi、0.0 si、0.0 st
MiB Mem: 合計 39913.6、無料 25450.8、使用済み 1875.7、バフ/キャッシュ 12587.1
MiB スワップ: 合計 16384.0、無料 16384.0、使用済み 0.0。36775.8 利用可能Mem
プロセス番号 USER PR NI VIRT RES SHR %CPU %MEM TIME COMMAND
286734 dechin 20 0 36.6g 175832 117544 S 4.0 0.4 1:02.32 chromium
So track
In [3]: 39.1* 1024/4
Out[3]: 10009.6
これは、ほぼ 10,000 個の float32 浮動小数点数のメモリ フットプリントに相当するため、これは、すべての要素がメモリに格納されたことを示します。
tracemalloc を使用してメモリ変更を追跡する
上の章では、スナップショット メモリ スナップショットの使用方法を紹介しましたが、2 つのメモリ スナップショットを「取得」し、それらを比較することは簡単に考えられます。スナップショットの変更を確認することでメモリ変更のサイズを取得できるでしょうか?次に、簡単な試みを行ってください:
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
snapshot0=tracemalloc.take_snapshot() # 第一张快照
length=10000
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot() # 第二张快照
top_stats=snapshot1.compare_to(snapshot0,'lineno') # 快照对比
print ('[Top 10 differences]')
for stat in top_stats[:10]:
print (stat)実行結果は次のとおりです:
[dechin@dechin-manjaro mmap]$ python3 comp_tracem.py
[トップ 10 の違い] ]
comp_tracem.py:9: size=78.2 KiB (78.2 KiB), count=2 (2), Average=39.1 KiB
前と前の平均メモリ サイズの違いがわかります。このスナップショットが 39.1 KiB になった後、ベクトルの次元を 1000000 に変更すると:
length=1000000
もう一度実行して効果を確認します:
[dechin@dechin-manjaro mmap] $ python3 comp_tracem.py
[上位 10 の違い]
comp_tracem.py:9: サイズ = 7813 KiB (7813 KiB)、カウント = 2 (2)、平均 = 3906 KiB
結果は 3906 であることがわかりました。これは 100 倍に拡大したことに相当し、予想とより一致しています。もちろん、慎重に計算すると、
In [4]: 3906*1024/4
Out[4]: 999936.0
となります。完全なfloat32型ではないのですが、完全なfloat32型に比べて一部のメモリサイズが抜けていますが、途中に0が発生して自動的にサイズが圧縮されているのかな?ただし、この問題は私たちが注目したいことではなく、メモリ変化曲線の下向きのテストを続けます。
メモリ使用量曲線
前の 2 つの章の内容を続けて、主に、異なる次元のランダム配列に必要なメモリ空間をテストします。上記のコード モジュールに基づいて、for ループを実行します。 ##
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat): # 判断是否属于当前文件所产生的内存占用
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(m曲线em[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect') # float32的预期占用空间
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')描画されたレンダリングは次のとおりです。
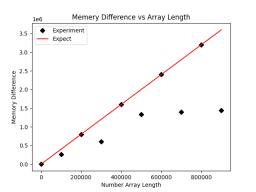
# comp_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi # 在原数组基础上加一个圆周率,内存不变
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if 'comp_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,4),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('comp_mem.png')更新後、結果のグラフは次のようになります:
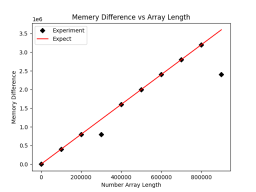
虽然不符合预期的点数少了,但是这里还是有两个点不符合预期的内存占用大小,疑似数据被压缩了。
mmap内存占用测试
在上面几个章节之后,我们已经基本掌握了内存追踪技术的使用,这里我们将其应用在mmap内存映射技术上,看看有什么样的效果。
将numpy数组写入txt文件
因为内存映射本质上是一个对系统文件的读写操作,因此这里我们首先将前面用到的numpy数组存储到txt文件中:
# write_array.py
import numpy as np
x=[]
y=[]
for length in range(1,1000000,100000):
np.random.seed(1)
test_array=np.random.randn(length)
test_array+=np.ones(length)*np.pi
np.savetxt('numpy_array_length_'+str(length)+'.txt',test_array)写入完成后,在当前目录下会生成一系列的txt文件:
-rw-r--r-- 1 dechin dechin 2500119 4月 12 10:09 numpy_array_length_100001.txt
-rw-r--r-- 1 dechin dechin 25 4月 12 10:09 numpy_array_length_1.txt
-rw-r--r-- 1 dechin dechin 5000203 4月 12 10:09 numpy_array_length_200001.txt
-rw-r--r-- 1 dechin dechin 7500290 4月 12 10:09 numpy_array_length_300001.txt
-rw-r--r-- 1 dechin dechin 10000356 4月 12 10:09 numpy_array_length_400001.txt
-rw-r--r-- 1 dechin dechin 12500443 4月 12 10:09 numpy_array_length_500001.txt
-rw-r--r-- 1 dechin dechin 15000526 4月 12 10:09 numpy_array_length_600001.txt
-rw-r--r-- 1 dechin dechin 17500606 4月 12 10:09 numpy_array_length_700001.txt
-rw-r--r-- 1 dechin dechin 20000685 4月 12 10:09 numpy_array_length_800001.txt
-rw-r--r-- 1 dechin dechin 22500788 4月 12 10:09 numpy_array_length_900001.txt
我们可以用head或者tail查看前n个或者后n个的元素:
[dechin@dechin-manjaro mmap]$ head -n 5 numpy_array_length_100001.txt
4.765938017253034786e+00
2.529836239939717846e+00
2.613420901326337642e+00
2.068624031433622612e+00
4.007000282914471967e+00
numpy文件读取测试
前面几个测试我们是直接在内存中生成的numpy的数组并进行内存监测,这里我们为了严格对比,统一采用文件读取的方式,首先我们需要看一下numpy的文件读取的内存曲线如何:
# npopen_tracem.py
import tracemalloc
import numpy as np
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=np.loadtxt('numpy_array_length_'+str(length)+'.txt',delimiter=',')
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
if '/home/dechin/anaconda3/lib/python3.8/site-packages/numpy/lib/npyio.py:1153' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.plot(x,np.dot(x,8),color='red',label='Expect')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('open_mem.png')需要注意的一点是,这里虽然还是使用numpy对文件进行读取,但是内存占用已经不是名为npopen_tracem.py的源文件了,而是被保存在了npyio.py:1153这个文件中,因此我们在进行内存跟踪的时候,需要调整一下对应的统计位置。最后的输出结果如下:
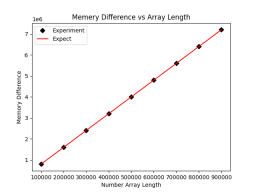
由于读入之后是默认以float64来读取的,因此预期的内存占用大小是元素数量×8,这里读入的数据内存占用是几乎完全符合预期的。
mmap内存占用测试
伏笔了一大篇幅的文章,最后终于到了内存映射技术的测试,其实内存映射模块mmap的使用方式倒也不难,就是配合os模块进行文件读取,基本上就是一行的代码:
# mmap_tracem.py
import tracemalloc
import numpy as np
import mmap
import os
tracemalloc.start()
x=[]
y=[]
multiplier={'B':1,'KiB':1024,'MiB':1048576}
snapshot0=tracemalloc.take_snapshot()
for length in range(1,1000000,100000):
test_array=mmap.mmap(os.open('numpy_array_length_'+str(length)+'.txt',os.O_RDWR),0) # 创建内存映射文件
snapshot1=tracemalloc.take_snapshot()
top_stats=snapshot1.compare_to(snapshot0,'lineno')
for stat in top_stats[:10]:
print (stat)
if 'mmap_tracem.py' in str(stat):
x.append(length)
mem=str(stat).split('average=')[1].split(' ')
y.append(float(mem[0])*multiplier[mem[1]])
break
import matplotlib.pyplot as plt
plt.figure()
plt.plot(x,y,'D',color='black',label='Experiment')
plt.title('Memery Difference vs Array Length')
plt.xlabel('Number Array Length')
plt.ylabel('Memory Difference')
plt.legend()
plt.savefig('mmap.png')运行结果如下:
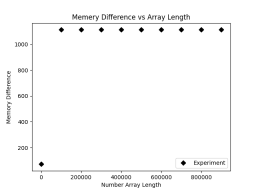
我们可以看到内存上是几乎没有波动的,因为我们并未把整个数组加载到内存中,而是在内存中加载了其内存映射的文件。我们能够以较小的内存开销读取文件中的任意字节位置。当我们去修改写入文件的时候需要额外的小心,因为对于内存映射技术来说,byte数量是需要保持不变的,否则内存映射就会发生错误。
以上がPython3 で Tracemalloc を使用して mmap メモリの変更を追跡する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AM
Python vs. C:比較されたアプリケーションとユースケースApr 12, 2025 am 12:01 AMPythonは、データサイエンス、Web開発、自動化タスクに適していますが、Cはシステムプログラミング、ゲーム開発、組み込みシステムに適しています。 Pythonは、そのシンプルさと強力なエコシステムで知られていますが、Cは高性能および基礎となる制御機能で知られています。
 2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM
2時間のPython計画:現実的なアプローチApr 11, 2025 am 12:04 AM2時間以内にPythonの基本的なプログラミングの概念とスキルを学ぶことができます。 1.変数とデータ型、2。マスターコントロールフロー(条件付きステートメントとループ)、3。機能の定義と使用を理解する4。
 Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AM
Python:主要なアプリケーションの調査Apr 10, 2025 am 09:41 AMPythonは、Web開発、データサイエンス、機械学習、自動化、スクリプトの分野で広く使用されています。 1)Web開発では、DjangoおよびFlask Frameworksが開発プロセスを簡素化します。 2)データサイエンスと機械学習の分野では、Numpy、Pandas、Scikit-Learn、Tensorflowライブラリが強力なサポートを提供します。 3)自動化とスクリプトの観点から、Pythonは自動テストやシステム管理などのタスクに適しています。
 2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM
2時間でどのくらいのPythonを学ぶことができますか?Apr 09, 2025 pm 04:33 PM2時間以内にPythonの基本を学ぶことができます。 1。変数とデータ型を学習します。2。ステートメントやループの場合などのマスター制御構造、3。関数の定義と使用を理解します。これらは、簡単なPythonプログラムの作成を開始するのに役立ちます。
 プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM
プロジェクトの基本と問題駆動型の方法で10時間以内にコンピューター初心者プログラミングの基本を教える方法は?Apr 02, 2025 am 07:18 AM10時間以内にコンピューター初心者プログラミングの基本を教える方法は?コンピューター初心者にプログラミングの知識を教えるのに10時間しかない場合、何を教えることを選びますか...
 中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AM
中間の読書にどこでもfiddlerを使用するときにブラウザによって検出されないようにするにはどうすればよいですか?Apr 02, 2025 am 07:15 AMfiddlereveryversings for the-middleの測定値を使用するときに検出されないようにする方法
 Python 3.6にピクルスファイルをロードするときに「__Builtin__」モジュールが見つからない場合はどうすればよいですか?Apr 02, 2025 am 07:12 AM
Python 3.6にピクルスファイルをロードするときに「__Builtin__」モジュールが見つからない場合はどうすればよいですか?Apr 02, 2025 am 07:12 AMPython 3.6のピクルスファイルのロードレポートエラー:modulenotFounderror:nomodulenamed ...
 風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの精度を改善する方法は?Apr 02, 2025 am 07:09 AM
風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの精度を改善する方法は?Apr 02, 2025 am 07:09 AM風光明媚なスポットコメント分析におけるJieba Wordセグメンテーションの問題を解決する方法は?風光明媚なスポットコメントと分析を行っているとき、私たちはしばしばJieba Wordセグメンテーションツールを使用してテキストを処理します...


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

