
ホームページ >Java >&#&チュートリアル >SpringBoot が機密単語のフィルタリングを実装する方法
SpringBoot が機密単語のフィルタリングを実装する方法

- 王林転載
- 2023-05-20 19:28:042267ブラウズ
機密用語のフィルタリング

1. フィルタリングする機密用語を保存するテキスト ファイルを作成します
最初に、フィルタリングする機密単語を保存するテキスト ファイルを作成します
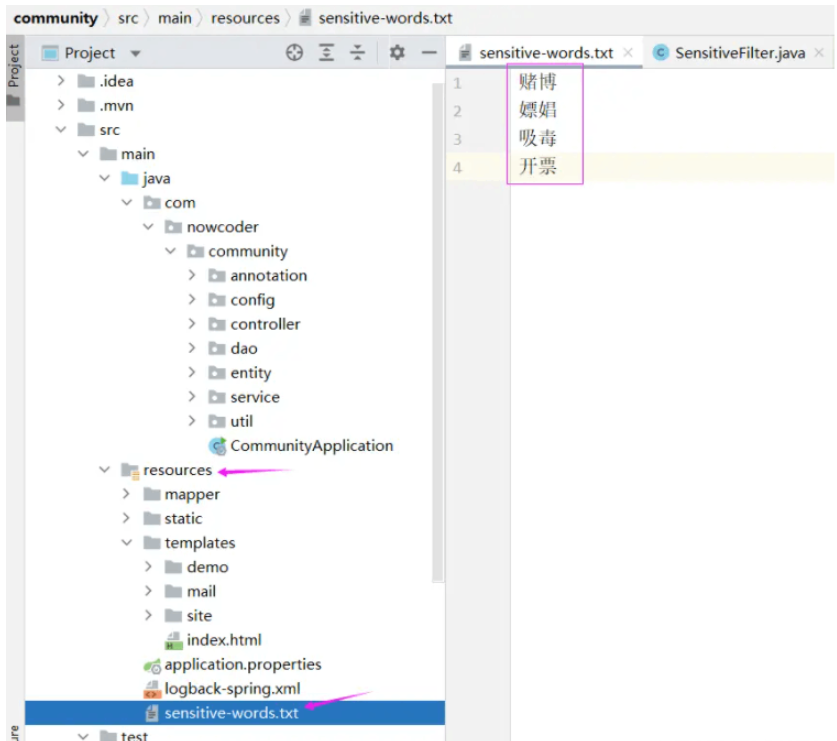
#次のツール クラスでは、事前に指定されたこのテキスト ファイルを読み取ります
@PostConstruct // 这个注解表示当容器实例化这个bean(服务启动的时候)之后在调用构造器之后这个方法会自动的调用
public void init(){
try(
// 读取写有“敏感词”的文件,getClass表示从程序编译之后的target/classes读配置文件,读之后是字节流
// java7语法,在这里的句子最后会自动执行close语句
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
// 字节流 -> 字符流 -> 缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
// 从文件中一行一行读
while ((keyword = reader.readLine()) != null){
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
} 2. 機密性の高い単語をフィルタリングするためのツール クラスを開発する
機密性の高い単語をフィルタリングするためのコンポーネントを開発する
将来の再利用を容易にするために、次のように書きます。機密性の高い単語をフィルタリングするためのツール クラス SensitiveFilter。
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
// 当检测到敏感词后我们要把敏感词替换成什么符号
private static final String REPLACEMENT = "***";
// 根节点
private TrieNode rootNode = new TrieNode();
@PostConstruct // 这个注解表示当容器实例化这个bean(服务启动的时候)之后在调用构造器之后这个方法会自动的调用
public void init(){
try(
// 读取写有“敏感词”的文件,getClass表示从程序编译之后的target/classes读配置文件,读之后是字节流
// java7语法,在这里的句子最后会自动执行close语句
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
// 字节流 -> 字符流 -> 缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
// 从文件中一行一行读
while ((keyword = reader.readLine()) != null){
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword){
// 首先默认指向根
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if(subNode == null){
// subNode为空,初始化子节点;subNode不为空,直接用就可以了
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指针指向子节点,进入下一轮循环
tempNode = subNode;
}
// 最后要设置结束标识
tempNode.setKeywordEnd(true);
}
/**
* 过滤敏感词
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public String filter(String text){
if(StringUtils.isBlank(text)){
// 待过滤的文本为空,直接返回null
return null;
}
// 指针1,指向树
TrieNode tempNode = rootNode;
// 指针2,指向正在检测的字符串段的首
int begin = 0;
// 指针3,指向正在检测的字符串段的尾
int position = 0;
// 储存过滤后的文本
StringBuilder sb = new StringBuilder();
while (begin < text.length()){
char c = text.charAt(position);
// 跳过符号,比如 “开票”是敏感词 #开#票# 这个字符串中间的 '#' 应该跳过
if(isSymbol(c)){
// 是特殊字符
// 若指针1处于根节点,将此符号计入结果,指针2、3向右走一步
if(tempNode == rootNode){
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
// 符号处理完,进入下一轮循环
continue;
}
// 执行到这里说明字符不是特殊符号
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if(tempNode == null){
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
} else if(tempNode.isKeywordEnd()){
// 发现敏感词,将begin~position字符串替换掉,存 REPLACEMENT (里面是***)
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = rootNode;
} else {
// 检查下一个字符
position++;
}
}
return sb.toString();
}
// 判断是否为特殊符号,是则返回true,不是则返回false
private boolean isSymbol(Character c){
// CharUtils.isAsciiAlphanumeric(c)方法:a、b、1、2···返回true,特殊字符返回false
// 0x2E80 ~ 0x9FFF 是东亚的文字范围,东亚文字范围我们不认为是符号
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
// 前缀树
private class TrieNode{
// 关键词结束标识
private boolean isKeywordEnd = false;
// 当前节点的子节点(key是下级字符、value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node){
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c){
return subNodes.get(c);
}
}
}
上記は機密単語フィルタリング ツール クラスのコードのすべてです。次に、開発手順を説明します。
開発には 3 つの手順があります。機密単語フィルタリング コンポーネント :
1. プレフィックス ツリー (ツリー) の定義
プレフィックス ツリー を定義し、# として記述します。 ##SensitiveFilter ツール クラスの内部クラス// 前缀树
private class TrieNode{
// 关键词结束标识
private boolean isKeywordEnd = false;
// 当前节点的子节点(key是下级字符、value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node){
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c){
return subNodes.get(c);
}
}
プレフィックス ツリーに機密単語を追加します
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword){
// 首先默认指向根
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if(subNode == null){
// subNode为空,初始化子节点;subNode不为空,直接用就可以了
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指针指向子节点,进入下一轮循环
tempNode = subNode;
}
// 最后要设置结束标识
tempNode.setKeywordEnd(true);
}
機密単語をフィルターする方法text:
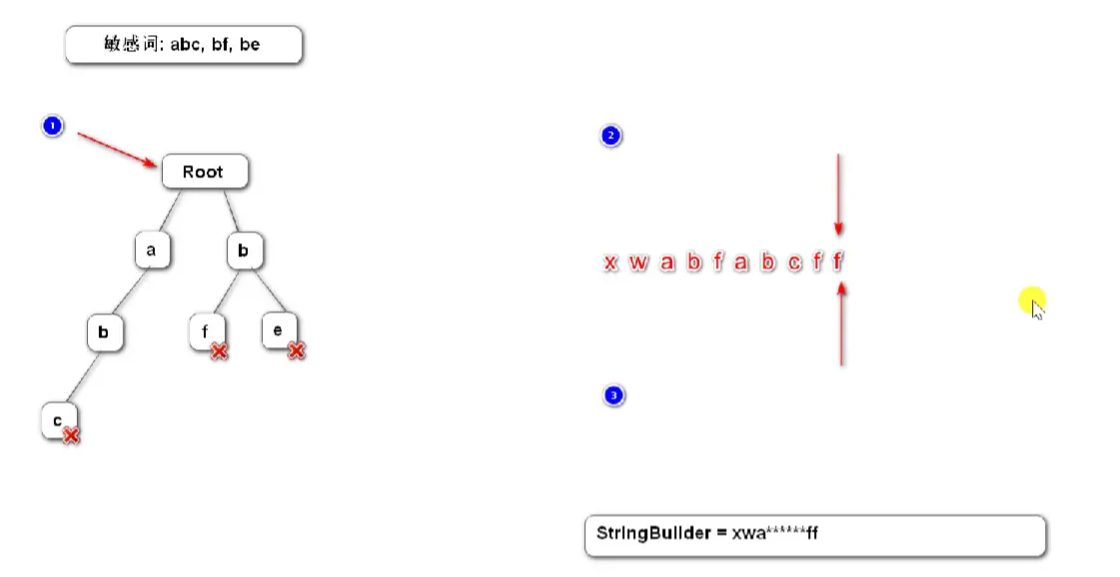 特殊記号の扱い方:
特殊記号の扱い方:
##センシティブワードプレフィックスツリーが初期化された後、テキスト内の機密単語のフィルタリングは次のようにする必要があります: 
- ポインター 1
- は
Tree ツリー#を指します。
## ポインタ 2 は、フィルタリングされる - 文字列セグメント
の ヘッダーを指します ## ポインタ 3
は、フィルタリングされる を指します。 文字列セグメントの - 末尾をフィルタリングします。
##
/** * 过滤敏感词 * @param text 待过滤的文本 * @return 过滤后的文本 */ public String filter(String text){ if(StringUtils.isBlank(text)){ // 待过滤的文本为空,直接返回null return null; } // 指针1,指向树 TrieNode tempNode = rootNode; // 指针2,指向正在检测的字符串段的首 int begin = 0; // 指针3,指向正在检测的字符串段的尾 int position = 0; // 储存过滤后的文本 StringBuilder sb = new StringBuilder(); while (begin < text.length()){ char c = text.charAt(position); // 跳过符号,比如 “开票”是敏感词 #开#票# 这个字符串中间的 '#' 应该跳过 if(isSymbol(c)){ // 是特殊字符 // 若指针1处于根节点,将此符号计入结果,指针2、3向右走一步 if(tempNode == rootNode){ sb.append(c); begin++; } // 无论符号在开头或中间,指针3都向下走一步 position++; // 符号处理完,进入下一轮循环 continue; } // 执行到这里说明字符不是特殊符号 // 检查下级节点 tempNode = tempNode.getSubNode(c); if(tempNode == null){ // 以begin开头的字符串不是敏感词 sb.append(text.charAt(begin)); // 进入下一个位置 position = ++begin; // 重新指向根节点 tempNode = rootNode; } else if(tempNode.isKeywordEnd()){ // 发现敏感词,将begin~position字符串替换掉,存 REPLACEMENT (里面是***) sb.append(REPLACEMENT); // 进入下一个位置 begin = ++position; // 重新指向根节点 tempNode = rootNode; } else { // 检查下一个字符 position++; } } return sb.toString(); } // 判断是否为特殊符号,是则返回true,不是则返回false private boolean isSymbol(Character c){ // CharUtils.isAsciiAlphanumeric(c)方法:a、b、1、2···返回true,特殊字符返回false // 0x2E80 ~ 0x9FFF 是东亚的文字范围,东亚文字范围我们不认为是符号 return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF); }##最後に: テスト クラスでテストすることをお勧めします
 テスト後、機密単語をフィルタリングするツールの開発が完了しました。このツールは、次の
テスト後、機密単語をフィルタリングするツールの開発が完了しました。このツールは、次の
機能で使用されます。
以上がSpringBoot が機密単語のフィルタリングを実装する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。