
ホームページ >テクノロジー周辺機器 >AI >ディープラーニングに最適な GPU の選択
ディープラーニングに最適な GPU の選択

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-20 17:04:061887ブラウズ
機械学習プロジェクトに取り組むとき、特にディープ ラーニングとニューラル ネットワークを扱うときは、CPU よりも GPU を使用した方がよいでしょう。これは、ニューラル ネットワークに関しては、非常に基本的な GPU であっても CPU よりも優れたパフォーマンスを発揮するためです。

しかし、どの GPU を購入すべきでしょうか? この記事では、予算と特定のモデリング要件に基づいて情報に基づいた選択ができるように、考慮すべき関連要素をまとめます。
機械学習には CPU よりも GPU の方が優れているのはなぜですか?
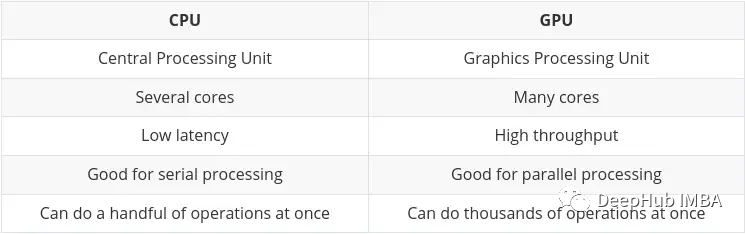
CPU (Central Processing Unit) はコンピュータの主要な機能であり、非常に柔軟で、さまざまなプログラムやハードウェアからの命令を処理する必要があるだけでなく、一定の処理速度も要求されます。このマルチタスク環境で適切なパフォーマンスを発揮するために、CPU には少数の柔軟で高速な処理ユニット (コアとも呼ばれます) が搭載されています。
GPU (グラフィックス プロセッシング ユニット) GPU は、マルチタスクに関してはそれほど柔軟性がありません。ただし、大量の複雑な数学的計算を並行して実行できます。これは、多くの単純な計算を同時に処理できる、より多くの単純なコア (数千から数万) を使用することで実現されます。
複数の計算を並行して実行するという要件は、次の場合に最適です。
- グラフィックのレンダリング - 移動するグラフィック オブジェクトは、その軌道を常に計算する必要があるため、常に大量の並列計算が必要になります。計算を繰り返しました。
- 機械学習と深層学習 - 多数の行列/テンソル計算を GPU で並列処理できます。
- あらゆる種類の数学的計算を分割して並列実行できます。
CPU と GPU の主な違いは、Nvidia 自身のブログにまとめられています:
Tensor Processing Unit (TPU)
人工知能と機械学習/深層学習の発展に伴い、テンソルコアと呼ばれる、より特化した処理コアが登場しました。テンソル/行列計算を実行する場合、より高速かつ効率的です。機械学習/深層学習で扱うデータ型はテンソルだからです。
専用の TPU もありますが、最新の GPU の一部には多くの Tensor コアも含まれており、これについては後ほどまとめます。
Nvidia と AMD
この質問に対する答えは間違いなく Nvidia であるため、これはかなり短いセクションになります
AMD の GPU を機械/深層学習に使用することは可能ですが、 , しかし、この記事の執筆時点では、Nvidia の GPU は互換性が高く、一般に TensorFlow や PyTorch などのツールとの統合がより適切です (たとえば、PyTorch による AMD GPU のサポートは、現在 Linux でのみ利用可能です)。
AMD GPU を使用するには、追加のツール (ROCm) を使用する必要があり、追加の作業が必要になり、バージョンがすぐに更新されない可能性があります。この状況は将来的には改善される可能性がありますが、今のところは Nvidia を使い続ける方が良いでしょう。
GPU 選択の主な属性
機械学習タスクに適しており、予算に合った GPU を選択するには、基本的に次の 4 つの主要な要素のバランスが重要です。
- GPU にはどのくらいのメモリが搭載されていますか?
- GPU には CUDA および/または tensor コアがいくつありますか?
- カードはどのようなチップ アーキテクチャを使用していますか?
- 何電力要件はありますか?
自分にとって何が重要なのかをより深く理解できるように、これらの側面を 1 つずつ見ていきましょう。
GPU メモリ
答えは、多ければ多いほど良いです!
実際には、タスクとモデルの大きさによって異なります。たとえば、画像、ビデオ、またはオーディオを処理する場合、定義上、かなり大量のデータを処理することになり、GPU RAM が非常に重要な考慮事項になります。
メモリ不足の問題を解決する方法は常にあります (バッチ サイズを減らすなど)。ただし、これではトレーニング時間が無駄になるため、ニーズのバランスをうまくとる必要があります。
経験に基づく私の提案は次のとおりです:
- 4GB: 過度に複雑なモデルや大きな画像を扱っていない限り、これが絶対的な最小値だと思います。 、ビデオまたはオーディオ。ほとんどの場合機能しますが、日常的な使用には十分ではありません。始めたばかりで、全力を尽くしずに試してみたい場合は、
- 8GB から始めることができます。毎日の学習に最適なスタートであり、RAM 制限を超えることなくほとんどのタスクを完了できますが、問題があります。より複雑な画像、ビデオ、またはオーディオ モデルを操作するときに発生する可能性があります。
- 12GB: これは科学研究の最も基本的な要件だと思います。画像、ビデオ、またはオーディオを扱うモデルも含め、ほとんどの大きなモデルを処理できます。
- 12GB: 多ければ多いほど、より大きなデータ セットやより大きなバッチ サイズを処理できるようになります。 12GBを超えると、実際に価格が上昇し始めます。
一般的に、コストが同じであれば、より多くのメモリを備えた「低速」のカードを選択する方が良いでしょう。 GPU の利点は高いスループットであり、GPU を介してデータを転送するには利用可能な RAM に大きく依存することに注意してください。
CUDA コアと Tensor コア
これは実際には非常に単純で、多ければ多いほど良いのです。
最初に RAM、次に CUDA を検討してください。機械/ディープ ラーニングの場合、Tensor コアは CUDA コアよりも優れています (高速で効率的)。これは、機械/深層学習の分野で必要な計算に合わせて正確に設計されているためです。
しかし、CUDA カーネルはすでに十分に高速であるため、これは問題ではありません。 Tensor コアを含むカードを入手できれば、それは大きなメリットですが、あまりこだわりすぎないでください。
「CUDA」については後で何度も出てくるので、最初に要約しましょう:
CUDA コア - これらはグラフィック カード上の物理プロセッサであり、通常は数千個あります。 , 4090はすでに16,000です。
CUDA 11 - 数字は変更される場合がありますが、これはグラフィックス カードが適切に機能するためにインストールされるソフトウェア/ドライバーを指します。 NV は定期的に新しいバージョンをリリースしており、他のソフトウェアと同様にインストールおよび更新できます。
CUDA 生成 (または計算能力) - これは、更新反復におけるグラフィックス カードのコード番号を示します。これはハードウェアで固定されているため、新しいカードにアップグレードすることによってのみ変更できます。番号とコードネームで区別されます。例: 3. ×[ケプラー]、5. x[マクスウェル]、6. × [パスカル]、7. x[チューリング]と8. x(アンペア)。
チップ アーキテクチャ
これは実際、あなたが思っているよりも重要です。ここでは AMD について議論しているのではありません。私の目には「古い黄色」が残っているだけです。
上で述べたように、30 シリーズ カードは Ampere アーキテクチャであり、最新の 40 シリーズ カードは Ada Lovelace です。通常、フアン氏はアーキテクチャに有名な科学者や数学者の名前を付けるが、今回はループとサブルーチンの概念を確立した女性数学者でコンピュータープログラムの創始者である英国の有名な詩人バイロンの娘、エイダ・ラブレスを選んだ。
カードのコンピューティング能力を理解するには、次の 2 つの側面を理解する必要があります。
- 大幅な機能の改善
- ここでの重要な機能は、混合精度トレーニングです。
32 ビット浮動小数点より精度の低い数値形式を使用すると、多くの利点があります。まず、必要なメモリが少なくなり、より大規模なニューラル ネットワークのトレーニングと展開が可能になります。次に、必要なメモリ帯域幅が少なくなるため、データ転送操作が高速化されます。 3 番目の数学演算は、特に Tensor コアを搭載した GPU 上で、精度は低下しますが、より高速に実行されます。混合精度トレーニングは、完全精度トレーニングと比較してタスク固有の精度を損なうことなく、これらの利点をすべて実現します。これは、完全な精度を必要とするステップを識別し、それらのステップにのみ 32 ビット浮動小数点を使用し、それ以外の場合は 16 ビット浮動小数点を使用することによって行われます。
こちらが Nvidia の公式ドキュメントです。ご興味がございましたら、お読みください:
https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index .html
混合精度トレーニングは、GPU が 7.x (Turing) 以降のアーキテクチャを備えている場合にのみ可能です。つまり、デスクトップでは RTX 20 シリーズ以降、サーバーでは「T」または「A」シリーズを意味します。
混合精度トレーニングにこのような利点がある主な理由は、RAM の使用量が削減されることです。Tensor Core の GPU により混合精度トレーニングが高速化されます。そうでない場合は、FP16 を使用するとビデオ メモリも節約され、より大きなバッチ サイズをトレーニングできます。間接的にトレーニング速度が向上します。
それは放棄されますか
RAM に対する特に高い要件があるが、ハイエンド カードを購入する十分な資金がない場合は、2 番目のカードで古い GPU を選択することもできます。ハンドマーケット。これにはかなり大きな欠点があります...カードの寿命は終わりました。
典型的な例は、4992 個の CUDA コアと 24GB の RAM を搭載した Tesla K80 です。 2014年には約7,000ドルで販売されていました。現在の価格は 150 ~ 170 ドルです! (塩辛の価格は 600 ~ 700 ドル程度です) このような安い価格でこれだけのメモリが得られるのは非常に興奮するでしょう。
しかし、非常に大きな問題があります。 K80 のコンピューティング アーキテクチャは 3.7 (Kepler) ですが、CUDA 11 以降はサポートされなくなりました (現在の CUDA バージョンは 11.7)。これはカードの有効期限が切れていることを意味するため、非常に安く販売されています。
したがって、中古カードを選ぶときは、最新バージョンのドライバーと CUDA をサポートしているかどうかを必ず確認してください。これが最も重要なことです。
ハイエンド ゲーム カード VS ワークステーション/サーバー カード
Lao Huang は基本的にカードを 2 つの部分に分割しました。コンシューマー向けグラフィックス カードおよびワークステーション/サーバー グラフィックス カード (つまり、プロフェッショナル向けグラフィックス カード)。
この 2 つの部分には明らかな違いがあり、同じ仕様 (RAM、CUDA コア、アーキテクチャ) の場合、一般に消費者向けグラフィック カードの方が安価です。ただし、プロ仕様のカードは通常、品質が高く、エネルギー消費量が低くなります (実際、タービンの騒音は非常に大きく、コンピューター室に置く場合には問題ありませんが、自宅や研究室に置く場合は少しうるさいです)。
ハイエンド (非常に高価な) プロフェッショナル カードでは、大量の RAM が搭載されていることに気づくかもしれません (例: RTX A6000 には 48GB、A100 には 80GB があります!)。これは、通常、高レベルの RAM を必要とする 3D モデリング、レンダリング、機械/深層学習のプロフェッショナル市場をターゲットにしているためです。繰り返しになりますが、お金があるなら A100 を買ってください! (H100 は A100 の新しいバージョンであり、現時点では評価できません)
しかし個人的には、コンシューマー向けハイエンド ゲーム カードを選択すべきだと考えています。十分なお金がない場合は、この記事を読まないでください。
提案の選択
それでは、最後に予算とニーズに基づいていくつかの提案をします。
- 低予算
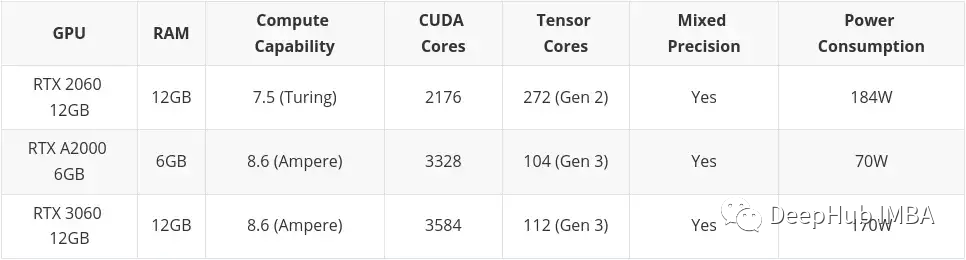
- 中予算
- 高予算
高予算では、それ以降は考慮されません。ハイエンドのコンシューマー向けグラフィックス カード。繰り返しますが、お金があるなら、A100 または H100 を購入してください。
この記事には中古市場で購入したカードも含まれます。これは主に、予算が低い場合は中古品を検討すべきだと思うからです。プロフェッショナル デスクトップ シリーズ カード (T600、A2000、および A4000) もここに含まれています。これは、構成の一部が同様のコンシューマー向けグラフィック カードよりわずかに劣るものの、消費電力が大幅に優れているためです。
#低予算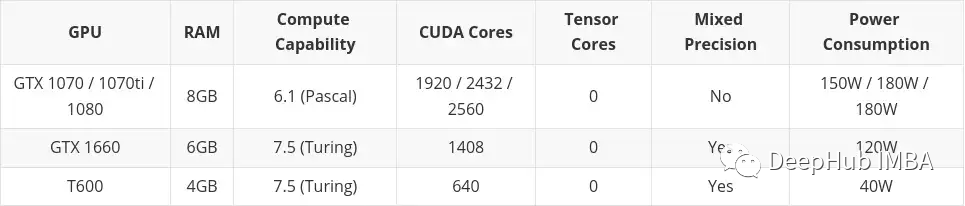
 ##高予算
##高予算
#オンライン/クラウド サービス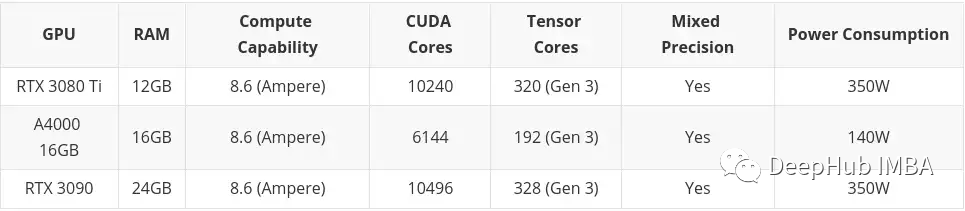
前述したように、K80 には 24GB の RAM と 4992 CUDA が搭載されています。基本的には 2 枚の K40 カードがリンクされています。これは、Colab で K80 を使用すると、実際にカードの半分にアクセスできることを意味します。つまり、12 GB と 2496 CUDA コアのみになります。 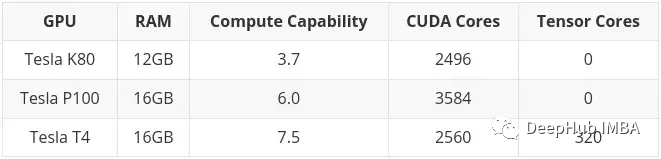
買わなければ、私が勝ちます買わないでください。明日は 200 円値下げされます
以上がディープラーニングに最適な GPU の選択の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。