
ホームページ >運用・保守 >Linuxの運用と保守 >Linuxのパフォーマンスを確認するコマンドは何ですか
Linuxのパフォーマンスを確認するコマンドは何ですか

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-20 15:37:072538ブラウズ
1.uptime

#このコマンドは、マシンの負荷状況を素早く確認できます。 Linux システムでは、これらのデータは、CPU リソースを待機しており、無中断 IO プロセスでブロックされているプロセス (プロセス ステータスは D) の数を表します。このデータにより、システム リソースの使用状況をマクロに理解できます。
コマンドの出力は、1 分、5 分、15 分の平均負荷状態をそれぞれ示します。これら 3 つのデータを通じて、そのエリアのサーバー負荷が逼迫しているか緩和しているかを把握できます。 1 分間の平均負荷が非常に高く、15 分間の平均負荷が非常に低い場合は、サーバーが高い負荷を要求していることを意味するため、CPU リソースがどこで消費されているかをさらに調査する必要があります。一方、15 分間の負荷平均が高く、1 分間の負荷平均が低い場合は、CPU リソースが逼迫する時期が過ぎている可能性があります。過去 1 分間の平均負荷が 15 分間の負荷よりも大幅に高い場合は、vmstat および mpstat コマンドを使用してトラブルシューティングを行う必要があります。
2.dmesg|tail
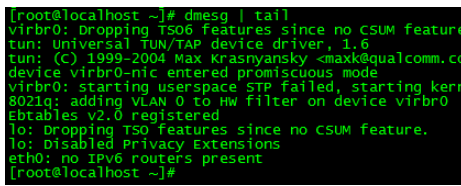
dmesgこのコマンドはブート情報を表示するために使用されます
dmesg|tailこのコマンドはシステム ログを出力します
3.vmstat1

の最後の 10 行各行は、システムの状態をより詳細に理解できるようにするいくつかのコア システム インジケーターを出力します。次のパラメータ 2 は、統計情報が 2 秒ごとに出力されることを示します。ヘッダーは各列の意味を示します。これらの列には、パフォーマンス チューニングに関連するいくつかの列が紹介されています。
r: CPU リソースを待機しているプロセスの数。このデータは平均負荷よりも CPU 負荷を反映していますが、IO を待機しているプロセスは含まれていません。この値がマシンの CPU コアの数より大きい場合、マシンの CPU リソースは飽和状態になります。
free: システムで利用可能なメモリの量 (キロバイト単位) 残りのメモリが不十分な場合は、システムのパフォーマンスの問題も発生します。以下に紹介する無料コマンドを使用すると、システム メモリの使用状況をより詳細に把握できます。
si,so: スワップ領域の書き込みおよび読み取りの数。このデータが 0 でない場合は、システムがすでにスワップ領域 (スワップ) を使用しており、マシンの物理メモリが不足していることを意味します。
us,sy,id,wa,st: これらはすべて CPU 時間の消費を表し、それぞれユーザー時間 (user)、システム (カーネル) 時間 (sys)、アイドル時間 (idle)、IO を表します。待機時間 (待機) と盗まれた時間 (盗まれ、通常は他の仮想マシンによって消費されます)。
上記の CPU 時間により、CPU がビジーかどうかをすぐに理解できます。一般に、ユーザー時間とシステム時間の合計が非常に大きい場合、CPU は命令の実行でビジーになります。 IO 待ち時間が長い場合、システムのボトルネックはディスク IO である可能性があります。
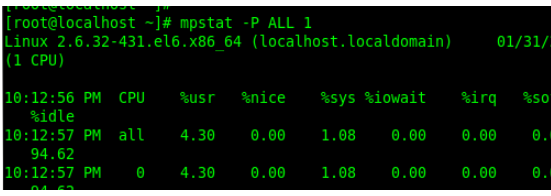
4.mpstat-PALL1

free コマンドを使用して、システム メモリの使用状況を表示できます。最後の 2 列は、IO キャッシュに使用されるメモリの量とファイル システムのページ キャッシュに使用されるメモリの量をそれぞれ表します。 2 行目 -/buffers/cache は、キャッシュが多くのメモリ領域を占有しているように見えることに注意してください。これは Linux システムのメモリ使用戦略です。できるだけメモリを利用します。アプリケーションがメモリを必要とする場合、このメモリはすぐに回収され、アプリケーションに割り当てられます。したがって、メモリのこの部分は一般に使用可能なメモリとみなされます。
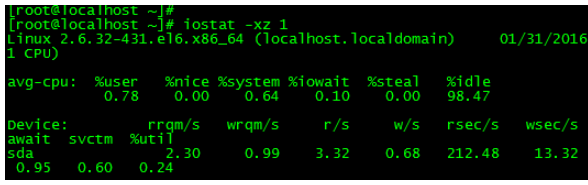
利用可能なメモリが非常に少ない場合、システムはスワップ領域 (構成されている場合) を使用する可能性があり、これにより IO オーバーヘッドが増加し (iostat コマンドで取り消すことができます)、システムのパフォーマンスが低下します。
8.sar-nDEV1
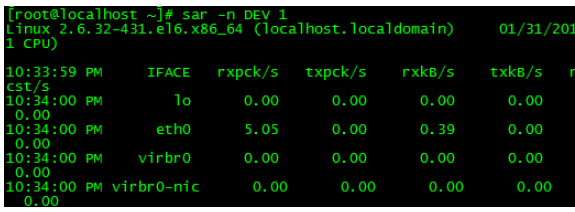
sar コマンドは、ここでネットワーク デバイスのスループット レートを確認できます。パフォーマンスの問題をトラブルシューティングする場合、ネットワーク デバイスのスループットが飽和しているかどうかを判断できます。サンプル出力に示されているように、eth0 ネットワーク カード デバイスのスループット レートはわずか約 0.39M バイト/秒です。
9.sar-nTCP,ETCP1
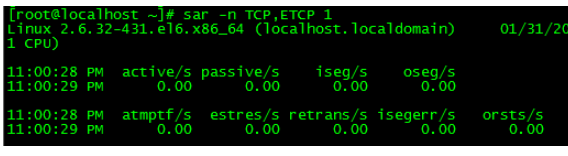
sar コマンドは、次のような TCP 接続ステータスを表示するために使用されます。
active/s: 1 秒あたりにローカルで開始された TCP 接続の数、つまり、connect 呼び出しを通じて作成された TCP 接続の数;
passive/s: each 1 秒あたりのリモートで開始された TCP 接続の数、つまり、accept 呼び出しを通じて作成された TCP 接続の数;
retrans/s: 1 あたりの TCP 再送信の数Second;
TCP 接続の数を使用して、パフォーマンスに問題があるかどうかを判断できます。確立された接続が多すぎるため、接続がアクティブに開始されたか受動的に受け入れられたかをさらに判断できます。 TCP の再送信は、ネットワーク環境の悪さやサーバーの過剰な負荷によって発生し、パケット損失が発生する可能性があります。
10.top
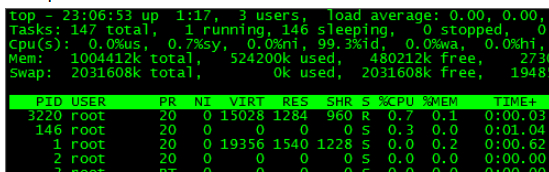
最初の行はタスク キューの情報で、uptime コマンドの実行結果と同じです。最初の列は次のことを表します。現在時刻、2 列目はシステムの稼働時間を示し、3 列目は現在ログインしている人数を示し、最後の負荷平均はシステム負荷を示します (3 つの値は 1 分、5 分、 15 分前から現在の負荷平均まで)
2 列目はプロセス情報を表しており、非常に直感的です。
以上がLinuxのパフォーマンスを確認するコマンドは何ですかの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。