



分類モデルは、生成モデルと識別モデルの 2 つのカテゴリに分類できます。この記事では、これら 2 つのモデル タイプの違いを説明し、それぞれのアプローチの長所と短所について説明します。

- ロジスティック回帰 (LR)
- サポート ベクター マシン (SVM)
- デシジョン ツリー (DT)


- Naive Bayes(ナイーブ ベイズ)
- ガウス混合モデル (GMM)
- 隠れマルコフ モデル (hmm)
- 線形判別分析 (LDA)
- # ディープ生成モデル (DGM) は、生成モデルとディープ ニューラル ネットワークを組み合わせます:
- Generative Adversarial Network (GAN)
- GPT (Generative Pretrained Transformer) などの自己回帰モデルは、数十億のパラメトリック自己回帰言語モデルを含むモデルです。
- 違い、長所と短所
生成モデルと判別モデルの主な違いは、学習目標の違いにあります。生成モデルは入力データの分布を学習し、新しいデータ サンプルを生成できます。識別モデルは入力データと出力ラベルの関係を学習し、新しいラベルを予測できます。
生成モデル:
生成モデルは入力分布とクラス確率を同時に学習するため、より多くの情報を提供します。学習された入力分布から新しいサンプルを生成できます。また、欠損値を使用せずに入力分布を推定できるため、欠損データを処理できます。ただし、ほとんどの識別モデルでは、すべての特徴が存在することが必要です。
生成モデルでは入力データと出力データの間の結合分布を確立するために大量のコンピューティング リソースとストレージ リソースが必要となるため、トレーニングの複雑さは高くなります。生成モデルは入力データと出力データの間の結合分布を確立する必要があり、データの分布を仮定してモデル化する必要があるため、データ分布の仮定は比較的強力です。したがって、複雑なデータ分布の場合、生成モデルは小規模な環境に適しています。コンピューティング リソースには適用されません。
生成モデルは入力データと出力データの間で多変量結合分布を確立できるため、生成モデルは多峰性データを処理できるようになり、多峰性データを処理できるようになります。
判別モデル:
データについて何らかの仮定を置かずに入力分布 P(x|y) を学習することは、生成モデルにとって計算上困難です。たとえば、x が m で構成されている場合、バイナリ特徴構成。P(x|y) をモデル化するには、各クラスのデータから 2 ᵐ パラメーターを推定する必要があります (これらのパラメーターは、m 特徴の 2 ᵐ 組み合わせのそれぞれの条件付き確率を表します)。 Naïve Bayes などのモデルは、学習する必要があるパラメーターの数を減らすために特徴の条件付き独立性を前提としているため、トレーニングの複雑さは低くなります。しかし、そのような仮定により、生成モデルのパフォーマンスが判別モデルよりも悪くなることがよくあります。
識別モデルは入力データと出力データの間のマッピング関係を柔軟にモデル化できるため、複雑なデータ分布や高次元データに対して優れたパフォーマンスを発揮します。
識別モデルは、入力データと出力データの間のマッピング関係のみを考慮し、欠損値を埋めるために入力データ内の情報を使用しないため、ノイズ データと欠損データの影響を受けやすくなります。そしてノイズを除去します。
概要
生成モデルと判別モデルはどちらも機械学習における重要なモデル タイプであり、それぞれに独自の利点と適用可能なシナリオがあります。実際のアプリケーションでは、特定のタスクのニーズに応じて適切なモデルを選択し、ハイブリッド モデルや他の技術的手段を組み合わせてモデルのパフォーマンスと効果を向上させる必要があります。
以上が生成モデルと識別モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 GoogleによるFirebase:カーソルやウィンドサーフよりも優れていますか? - 分析VidhyaApr 26, 2025 am 09:39 AM
GoogleによるFirebase:カーソルやウィンドサーフよりも優れていますか? - 分析VidhyaApr 26, 2025 am 09:39 AMFireBase Studio:AIを搭載したアプリ開発のための共同操縦団 アプリを構築して起動するクラウドベースのワークスペースを想像してみてください。これは、Googleのインテリジェントな開発環境であるFirebase Studioです。 ブレーンストーミングかr
 llama 4 vs. GPT-4o:ぼろきれに適しているのはどれですか?Apr 26, 2025 am 09:37 AM
llama 4 vs. GPT-4o:ぼろきれに適しているのはどれですか?Apr 26, 2025 am 09:37 AMこの記事では、MetaのLlama 4 ScoutとOpenaiのGPT-4oのパフォーマンスを検索された世代(RAG)システム内で比較します。 この評価は、Ragasフレームワークを利用して、忠実さ、回答の関連性、およびコンテキストのメトリックを提供します
 生成AIと人間のつながりの変革関係 - 分析vidhyaApr 26, 2025 am 09:36 AM
生成AIと人間のつながりの変革関係 - 分析vidhyaApr 26, 2025 am 09:36 AM2025:生成的AIは生産性ツールから個人的な仲間に進化します 生成AIの役割は2025年に劇的に拡大し、単純な生産性タスクを超えて個人的な生活の重要な存在になりました。その効率向上中
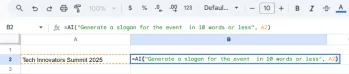 GoogleシートでGeminiを使用する方法は?Apr 26, 2025 am 09:34 AM
GoogleシートでGeminiを使用する方法は?Apr 26, 2025 am 09:34 AMGoogleシートは、Geminiの= AI関数の導入により、重要なアップグレードを取得し、以前に手動の努力を必要とするデータタスクを自動化します。このAIを搭載した式により、シンプルな分類、要約、および式の開発が簡素化されます
 Python One Linersデータクリーニング:クイックガイド - 分析VidhyaApr 26, 2025 am 09:33 AM
Python One Linersデータクリーニング:クイックガイド - 分析VidhyaApr 26, 2025 am 09:33 AMPython One-Linersで簡単にクリーニングしました 強力なPython One-Linersでデータクリーニングプロセスを合理化します!このガイドでは、欠損値、重複、問題のフォーマットなどを処理するための必須のパンダテクニックを紹介しています。
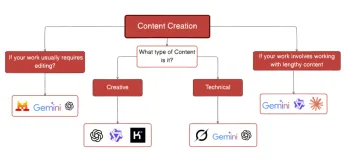 タスクに最適なAIチャットボットを選択するためのガイドApr 26, 2025 am 09:31 AM
タスクに最適なAIチャットボットを選択するためのガイドApr 26, 2025 am 09:31 AM最高の最新のLLMSをどのように追跡していますか?あなたがニュースを追跡しているなら、特にここ数ヶ月で、あなたはそこにあるモデルに圧倒されたと確信しています。今日、私たちはFIよりも多くのAIチャットボットを持っています
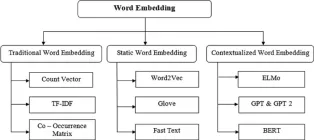 埋め込みの進化を定義する14の強力な手法 - 分析vidhyaApr 26, 2025 am 09:29 AM
埋め込みの進化を定義する14の強力な手法 - 分析vidhyaApr 26, 2025 am 09:29 AMこの記事では、単純なカウントベースの方法から洗練されたコンテキスト対応モデルまで、テキストの埋め込みの進化について説明します。 埋め込み性能と最先端のアクセシビリティを評価する際のMTEBのようなリーダーボードの役割を強調しています
 O3対O4 -Mini vs Gemini 2.5 Pro:究極の推論バトル-AnalyticsVidhyaApr 26, 2025 am 09:28 AM
O3対O4 -Mini vs Gemini 2.5 Pro:究極の推論バトル-AnalyticsVidhyaApr 26, 2025 am 09:28 AMこのブログは、厳密な推論課題で互いに並んでいる3つの主要なAIモデル(O3、O4-Mini、およびGemini 2.5 Pro)をピットします。 物理学、数学、コーディング、Webデザイン、画像分析にわたってそれらの能力をテストし、それらの強みを明らかにします


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

WebStorm Mac版
便利なJavaScript開発ツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。
ホットトピック
 7722
7722 15164214139652128925123329
15164214139652128925123329