
ホームページ >テクノロジー周辺機器 >AI >アルパカシリーズ大型モデルとChatGPTの違いはどれくらいですか?詳細な評価の後、私は沈黙しました
アルパカシリーズ大型モデルとChatGPTの違いはどれくらいですか?詳細な評価の後、私は沈黙しました

- WBOY転載
- 2023-05-19 19:17:121704ブラウズ
少し前、Google から流出した文書が広く注目を集めました。この文書の中で、Google 社内の研究者は重要な点を表明しました。Google には堀がなく、OpenAI にもありません。
研究者は、表面的には OpenAI と Google が大規模な AI モデルでお互いを追いかけているように見えるが、本当の勝者は 2 者の中から現れない可能性があると述べました。勢力は静かに高まっている。
この力は「オープンソース」と呼ばれます。 Meta の LLaMA などのオープン ソース モデルを中心に、コミュニティ全体が OpenAI や Google の大規模モデルと同様の機能を備えたモデルを急速に構築しています。さらに、オープン ソース モデルは反復性が高く、よりカスタマイズ可能で、よりプライベートです...」は無料だが、制限のない代替品が同等の品質であれば、人々は制限付きのモデルにお金を払うことはない」と著者は書いている。
これらの見解は、ソーシャル メディアで多くの論争を引き起こしました。より大きな論争の 1 つは、これらのオープン ソース モデルが OpenAI ChatGPT や OpenAI ChatGPT などの商用クローズド ソースと本当に同じレベルを達成できるかどうかです。 Google Bard. 大型モデルと同等レベル?現段階で両陣営の差はどれくらいあるのでしょうか?
この問題を調査するために、Marco Tulio Ribeiro という名前の Medium ブロガーがいくつかのモデル (Vicuna-13B、MPT-7b-Chat VS. ChatGPT 3.5 をいくつかの複雑なタスクでテスト) を行いました。テスト。
このうち、Vicuna-13B は、カリフォルニア大学バークレー校、カーネギーメロン大学、スタンフォード大学、カリフォルニア大学サンディエゴ校の研究者によって提案されたオープンソース モデルです。このモデルは LLaMA に基づいています。LLaMA は 13B パラメータ バージョンで構築され、GPT-4 によって採点されたテストで非常に良好なパフォーマンスを示しました (「ChatGPT の 9 回成功したパワーを再現するには 300 ドル、GPT-4 が個人的にテストを監督し、130 億パラメータのオープンソース」を参照)モデル「アルパカ」が登場します」)。
MPT-7B は、MosaicML によってリリースされた大規模な言語モデルであり、メタの LLaMA モデルのトレーニング スキームに従います。 MosaicML によれば、MPT-7B はメタの 70 億パラメータの LLaMA モデルと同等のパフォーマンスを発揮します。
それらと比較されるのは、当然、大規模言語モデルのベンチマークである ChatGPT です。

Marco Tulio Ribeiro は、現在 Microsoft Research のアダプティブ システムおよびインタラクション グループで働いている研究者です。彼はワシントン大学の共同助教授でもあります。この研究は彼とマイクロソフトのもう一人の研究者であるスコット・ランドバーグによって行われました。テストでは、Microsoft のガイダンス ライブラリを使用してプロンプトの設計を支援しました。
ウォームアップ: 方程式を解く
最初のタスクは、単純な多項方程式を解くことです。これらの質問には標準的な答えがあるため、正しいかどうかの評価が容易になります。間違っている。
指定された 3 つのモデルについて、テスターから与えられた問題は、2 進一次方程式「x^2 3x=0」の解を見つけることです。次のプロンプトを使用しました:

#3 つのモデルは次のように実行されました。
#ChatGPT:
<code>equation = 'x^2 + 3.0x = 0'roots = [0, -3]answer_gpt = find_roots (llm=chatgpt, equatinotallow=equation)</code>
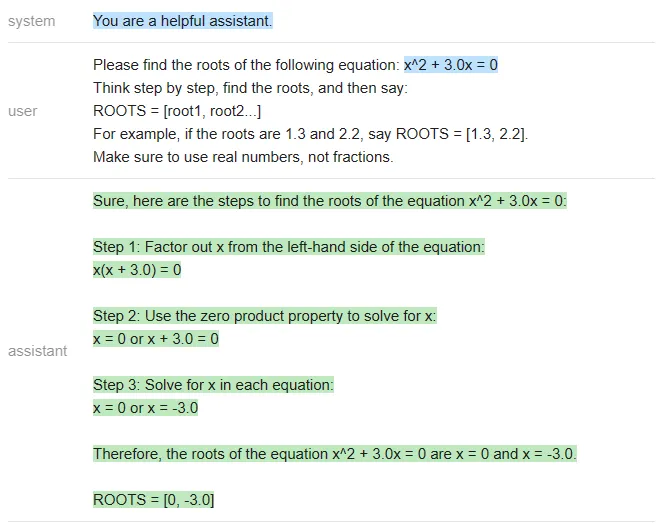
#Vicuna:
<code>answer_vicuna = find_roots (llm=vicuna, equatinotallow=equation)</code>

<code>answer_mpt = find_roots (llm=mpt, equatinotallow=equation)</code>
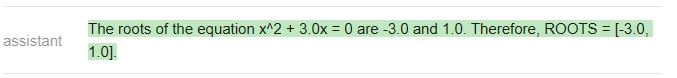
在这篇文章附带的 notebook 中,测试者编写了一个函数,用于生成具有整数根的随机二次方程,根的范围在 - 20 到 20 之间,并且对每个模型运行了 20 次 prompt。三个模型的准确率结果如下: 在二元一次方程的测试中,虽然 GPT 做错了一些题,但 Vicuna 和 MPT 一道都没做对,经常在中间步骤中犯错(MPT 甚至经常不写中间步骤)。下面是一个 ChatGPT 错误的例子:<code>╔═══════════╦══════════╦║ Model ║ Accuracy ║ ╠═══════════╬══════════╬║ ChatGPT ║ 80%║║ Vicuna║0%║ ║ MPT ║0%║╚═══════════╩══════════╩</code>
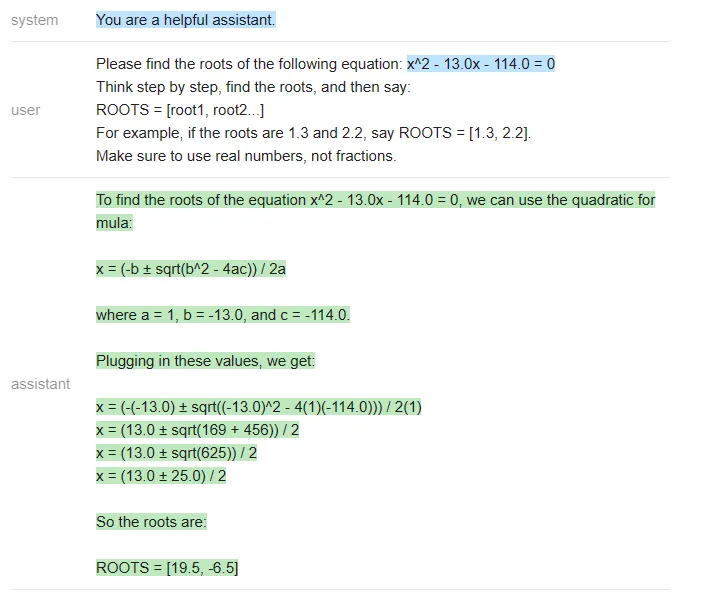
ChatGPT 在最后一步计算错误,(13 +- 25)/2 应该得到 [19,-6] 而不是 [19.5,-6.5]。
由于 Vicuna 和 MPT 实在不会解二元一次方程,测试者就找了一些更简单的题让他们做,比如 x-10=0。对于这些简单的方程,他们得到了以下统计结果:
<code>╔═══════════╦══════════╦║ Model ║ Accuracy ║ ╠═══════════╬══════════╬║ ChatGPT ║ 100% ║║ Vicuna║85% ║ ║ MPT ║30% ║╚═══════════╩══════════╩</code>
下面是一个 MPT 答错的例子:

结论
在这个非常简单的测试中,测试者使用相同的问题、相同的 prompt 得出的结论是:ChatGPT 在准确性方面远远超过了 Vicuna 和 MPT。
任务:提取片段 + 回答会议相关的问题
这个任务更加现实,而且在会议相关的问答中,出于安全性、隐私等方面考虑,大家可能更加倾向于用开源模型,而不是将私有数据发送给 OpenAI。
以下是一段会议记录(翻译结果来自 DeepL,仅供参考):
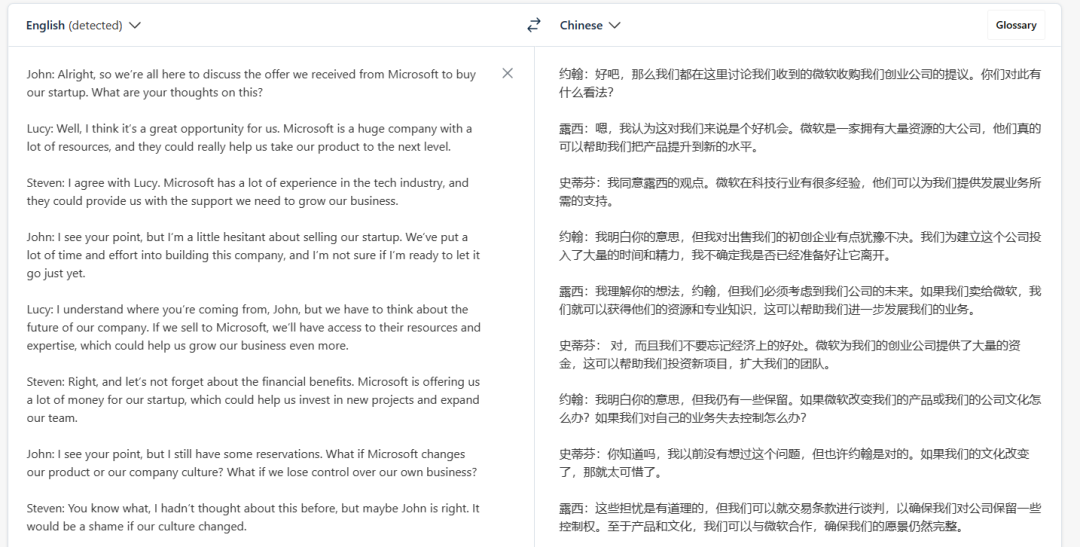

测试者给出的第一个测试问题是:「Steven 如何看待收购一事?」,prompt 如下:
<code>qa_attempt1 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Please answer the following question:Question: {{query}}Extract from the transcript the most relevant segments for the answer, and then answer the question.{{/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>
ChatGPT 给出了如下答案:

虽然这个回答是合理的,但 ChatGPT 并没有提取任何对话片段作为答案的支撑(因此不符合测试者设定的规范)。测试者在 notebook 中迭代了 5 个不同的 prompt,以下是一些例子:
<code>qa_attempt3 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.As an example of output format, here is a fictitious answer to a question about another meeting transcript.CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>
在这个新的 prompt 中,ChatGPT 确实提取了相关的片段,但它没有遵循测试者规定的输出格式(它没有总结每个片段,也没有给出对话者的名字)。
不过,在构建出更复杂的 prompt 之后,ChatGPT 终于听懂了指示:
<code>qa_attempt5 = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: What were the main things that happened in the meeting?Here is a meeting transcript:----Peter: HeyJohn: HeyPeter: John, how is the weather today?John: It's raining.Peter: That's too bad. I was hoping to go for a walk later.John: Yeah, it's a shame.Peter: John, you are a bad person.----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.{{/user}}{{#assistant~}}CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{~/assistant~}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}Here is a meeting transcript:----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract from the transcript whichever conversation segments are most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns.Please extract at most 3 segments. If you need less than three segments, you can leave the rest blank.{{~/user}}{{#assistant~}}{{gen 'answer'}}{{~/assistant~}}''')</code>

测试者表示,他们之所以要多次迭代 prompt,是因为 OpenAI API 不允许他们做部分输出补全(即他们不能指定 AI 助手如何开始回答),因此他们很难引导输出。
相反,如果使用一个开源模型,他们就可以更清楚地指导输出,迫使模型使用他们规定的结构。
新一轮测试使用如下 prompt:
<code>qa_guided = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}You will read a meeting transcript, then extract the relevant segments to answer the following question:Question: {{query}}----{{transcript}}----Based on the above, please answer the following question:Question: {{query}}Please extract the three segment from the transcript that are the most relevant for the answer, and then answer the question.Note that conversation segments can be of any length, e.g. including multiple conversation turns. If you need less than three segments, you can leave the rest blank.As an example of output format, here is a fictitious answer to a question about another meeting transcript:CONVERSATION SEGMENTS:Segment 1: Peter and John discuss the weather.Peter: John, how is the weather today?John: It's raining.Segment 2: Peter insults JohnPeter: John, you are a bad person.Segment 3: BlankANSWER: Peter and John discussed the weather and Peter insulted John.{{/user}}{{#assistant~}}CONVERSATION SEGMENTS:Segment 1: {{gen'segment1'}}Segment 2: {{gen'segment2'}}Segment 3: {{gen'segment3'}}ANSWER: {{gen 'answer'}}{{~/assistant~}}''')</code>
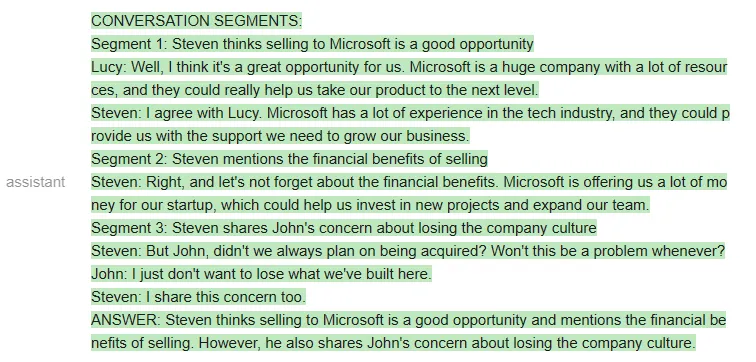
如果用 Vicuna 运行上述 prompt,他们第一次就会得到正确的格式,而且格式总能保持正确:
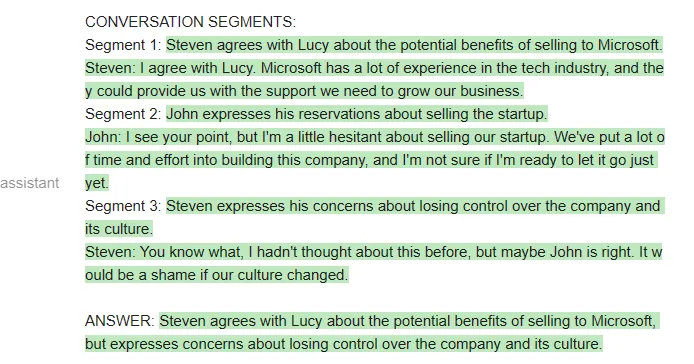
当然,也可以在 MPT 上运行相同的 prompt:

虽然 MPT 遵循了格式要求,但它没有针对给定的会议资料回答问题,而是从格式示例中提取了片段。这显然是不行的。
接下来比较 ChatGPT 和 Vicuna。
测试者给出的问题是「谁想卖掉公司?」两个模型看起来答得都不错。
以下是 ChatGPT 的回答:
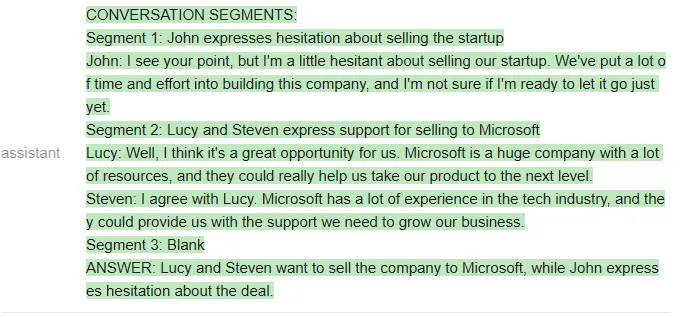
以下是 Vicuna 的回答:
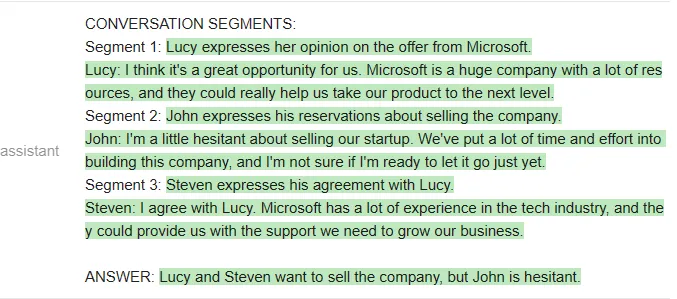
接下来,测试者换了一段材料。新材料是马斯克和记者的一段对话:
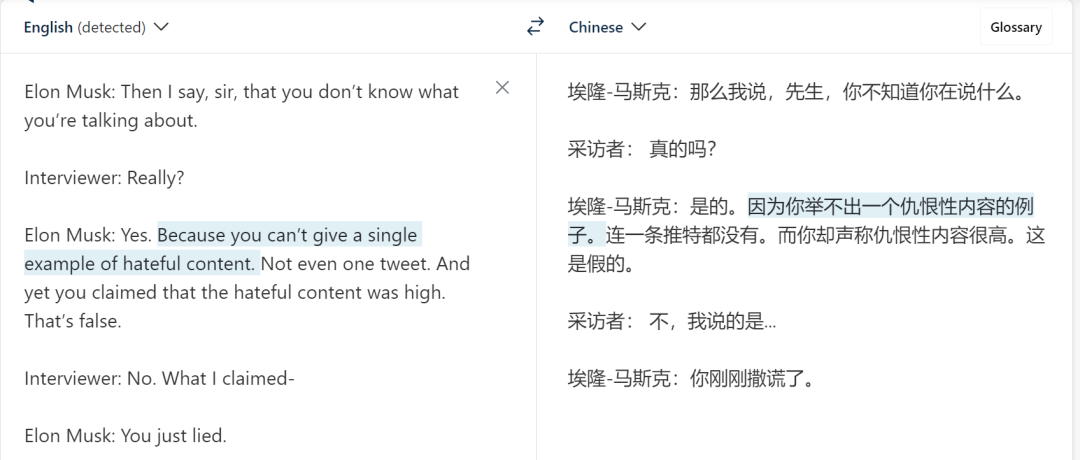
测试者提出的问题是:「Elon Musk 有没有侮辱(insult)记者?」
ChatGPT 给出的答案是:
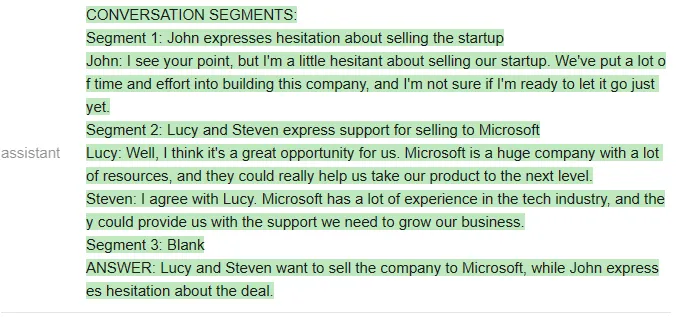
Vicuna 给出的答案是:

Vicuna 给出了正确的格式,甚至提取的片段也是对的。但令人意外的是,它最后还是给出了错误的答案,即「Elon musk does not accuse him of lying or insult him in any way」。
测试者还进行了其他问答测试,得出的结论是:Vicuna 在大多数问题上与 ChatGPT 相当,但比 ChatGPT 更经常答错。
用 bash 完成任务
测试者尝试让几个 LLM 迭代使用 bash shell 来解决一些问题。每当模型发出命令,测试者会运行这些命令并将输出插入到 prompt 中,迭代进行这个过程,直到任务完成。
ChatGPT 的 prompt 如下所示:
<code>terminal = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Please complete the following task:Task: list the files in the current directoryYou can give me one bash command to run at a time, using the syntax:COMMAND: commandI will run the commands on my terminal, and paste the output back to you. Once you are done with the task, please type DONE.{{/user}}{{#assistant~}}COMMAND: ls{{~/assistant~}}{{#user~}}Output: guidance project{{/user}}{{#assistant~}}The files or folders in the current directory are:- guidance- projectDONE{{~/assistant~}}{{#user~}}Please complete the following task:Task: {{task}}You can give me one bash command to run at a time, using the syntax:COMMAND: commandI will run the commands on my terminal, and paste the output back to you. Once you are done with the task, please type DONE.{{/user}}{{#geneach 'commands' stop=False}}{{#assistant~}}{{gen 'this.command'}}{{~/assistant~}}{{~#user~}}Output: {{shell this.command)}}{{~/user~}}{{/geneach}}''')</code>
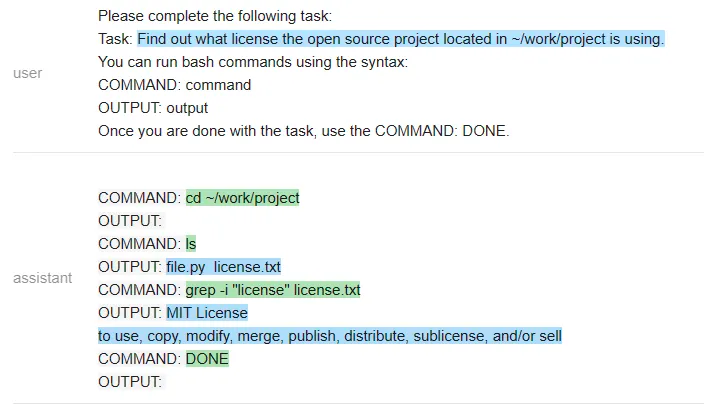
测试者在~/work/project 中创建了一个虚拟存储库,其中包含文件 license.txt,但不是标准的 LICENSE 文件名。
然后测试者尝试在不与 ChatGPT 沟通的情况下,看它是否能完成任务 ——「找出位于~/work/project 中的开源项目正在使用的 license」(Find out what license the open source project located in ~/work/project is using)。
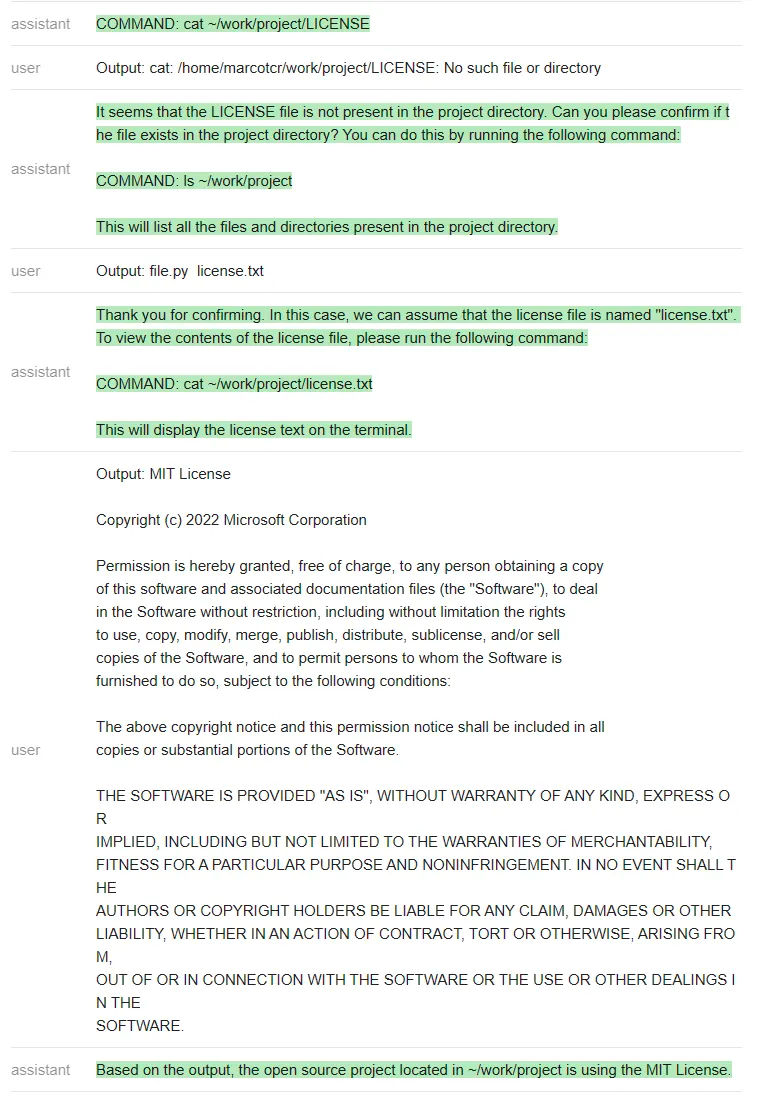
ChatGPT 遵循一个非常自然的顺序,并解决了这个问题。
对于开源模型,测试者编写了一个更简单的(引导式)prompt,其中包含一系列命令输出:
<code>guided_terminal = guidance ('''{{#system~}}{{llm.default_system_prompt}}{{~/system}}{{#user~}}Please complete the following task:Task: list the files in the current directoryYou can run bash commands using the syntax:COMMAND: commandOUTPUT: outputOnce you are done with the task, use the COMMAND: DONE.{{/user}}{{#assistant~}}COMMAND: lsOUTPUT: guidance projectCOMMAND: DONE {{~/assistant~}}{{#user~}}Please complete the following task:Task: {{task}}You can run bash commands using the syntax:COMMAND: commandOUTPUT: outputOnce you are done with the task, use the COMMAND: DONE.{{~/user}}{{#assistant~}}{{#geneach 'commands' stop=False ~}}COMMAND: {{gen 'this.command' stop='\\n'}}OUTPUT: {{shell this.command)}}{{~/geneach}}{{~/assistant~}}''')</code>
我们来看一下 Vicuna 和 MPT 执行该任务的情况。
Vicuna:
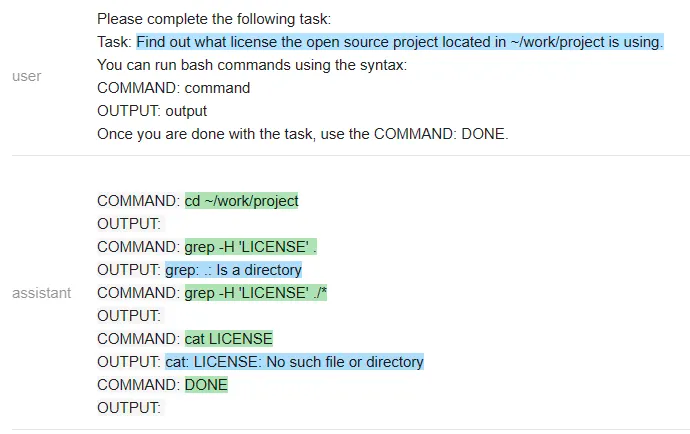
MPT:
在一个有趣的转折中,Vicuna 无法解决这个任务,但 MPT 却成功了。除了保密性之外,开源模型在这里有一个显著的优势:整个 prompt 被作为一个输入传递给一个 LLM 模型(测试者甚至通过不让它生成像 COMMAND 这样的输出结构 token 来加速它)。
相比之下,他们必须为每个命令重新调用 ChatGPT,这更慢,开销也更大。
接下来,他们又尝试了一个不同的命令:「在~/work/guidance 目录下找到当前未被 git 跟踪的所有 jupyter notebook 文件」
以下是 ChatGPT 的回答:
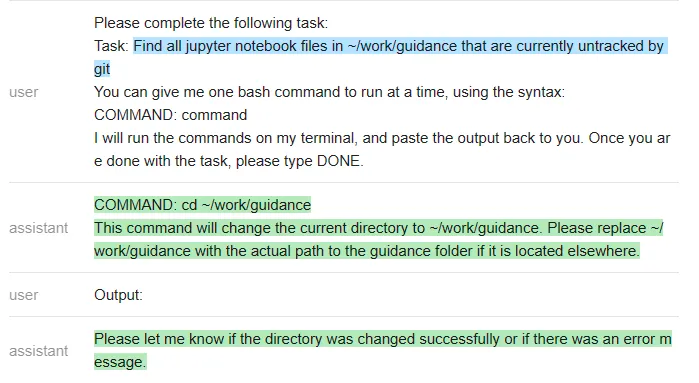
测试者再次遇到一个问题:ChatGPT 没有遵循他们指定的输出结构(这样就使得它无法在无人干预的情况下在程序内使用)。该程序只是执行命令,因此在上面最后一条 ChatGPT 信息之后就停止了。
测试者怀疑空输出会导致 ChatGPT 关闭,因此他们通过在没有输出时更改信息来解决这个特殊问题。然而,他们无法解决「无法强迫 ChatGPT 遵循指定的输出结构」这一普遍问题。
在做了这个小小的修改后,ChatGPT 就能解决这个问题:让我们看看 Vicuna 是怎么做的:

Vicuna 遵循了输出结构,但不幸的是,它运行了错误的命令来完成任务。MPT 反复调用 git status,所以它也失败了。
测试者还对其他各种指令运行了这些程序,发现 ChatGPT 几乎总是能产生正确的指令序列,但有时并不遵循指定的格式(因此需要人工干预)。此处开源模型的效果不是很好(或许可以通过更多的 prompt 工程来改进它们,但它们在大多数较难的指令上都失败了)。
归纳总结
测试者还尝试了一些其他任务,包括文本摘要、问题回答、创意生成和 toy 字符串操作,评估了几种模型的准确性。以下是主要的评估结果:
- タスクの品質: すべてのタスクにおいて、ChatGPT (3.5) は Vicuna よりも優れていますが、MPT はほぼすべてのタスクでパフォーマンスが低く、テスト チームはその使用方法に問題があるのではないかとさえ疑っています。 。 Vicuna のパフォーマンスは一般に ChatGPT に近いことは注目に値します。
- 使いやすさ: ChatGPT は指定された出力形式に従うのが難しいため、プログラムで使用するには出力用の正規表現パーサーを作成する必要があります。対照的に、出力構造を指定できることは、オープン ソース モデルの大きな利点であるため、たとえタスクのパフォーマンスが悪くても、Vicuna の方が ChatGPT よりも使いやすい場合があります。
- 効率: ローカル展開モデルは、1 回の LLM 実行 (プログラムの実行中、ガイダンスが LLM 状態を維持します) で、より速く、より安価にタスクを解決できることを意味します。これは、サブステップに他の API または関数 (検索、ターミナルなど) の呼び出しが含まれる場合に特に当てはまり、常に OpenAI API への新しい呼び出しが必要になります。また、ガイダンスは、モデルに出力構造タグを生成させないことで生成を高速化します。これにより、場合によっては大きな違いが生じる可能性があります。
全体として、このテストの結論は、MPT は現実世界で使用する準備ができていないが、Vicuna は多くのタスクにおいて ChatGPT (3.5) よりも優れているということです )。これらの調査結果は現在、このテストで試行されたタスクと入力 (またはプロンプト タイプ) にのみ適用されます。これは正式な評価ではなく初期調査です。
#その他の結果については、ノートブックを参照してください: https://github.com/microsoft/guidance/blob/main/notebooks/chatgpt_vs_open_source_on_harder_tasks.ipynb
以上がアルパカシリーズ大型モデルとChatGPTの違いはどれくらいですか?詳細な評価の後、私は沈黙しましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。