


火山エンジン ツール テクノロジーの共有: AI を使用してデータ マイニングを完了し、ゼロしきい値で SQL 書き込みを完了します


BI ツールを使用するときに、よく遭遇する質問は次のとおりです。「SQL を知らない場合、データをどのように生成および処理できますか? 知らない場合、マイニング分析を行うことはできますか?」
プロのアルゴリズム チームがデータ マイニングを行う場合、データ分析と視覚化も比較的断片化されているように見えます。アルゴリズムのモデリングとデータ分析の作業を合理的な方法で完了することも、効率を向上させる良い方法です。
同時に、プロのデータ ウェアハウス チームにとって、同じテーマのデータ コンテンツは「繰り返し構築され、比較的分散して使用および管理される」という問題に直面しています。それを同時に作成する方法はあるのでしょうか?同じテーマの 1 つのタスクですか? 異なるコンテンツのデータセットですか?生成されたデータセットをデータ構築に再参加するための入力として使用できますか?
1. DataWind のビジュアル モデリング機能はこちらです
Volcano Engine によって開始された BI プラットフォーム DataWind インテリジェント データ インサイトは、新しい高度な機能ビジュアル モデリングを開始しました。
ユーザーは、視覚的なドラッグ、プル、接続操作を通じて、複雑なデータ処理とモデリングのプロセスを明確で理解しやすいキャンバス プロセスに簡素化できます。あらゆる種類のユーザーが、彼らが何を考えているか、それが得られるものであるというアイデアを実現し、それによってデータの生成と取得の敷居を下げます。
Canvas は、キャンバス プロセスの複数グループの同時構築をサポートしており、1 つのピクチャで複数のデータ モデリング タスクの構築を実現できるため、データ構築の効率が向上し、タスク管理コストが削減されます。さらに、Canvas は統合およびカプセル化を行います。 40 種類を超えるデータ クリーニング、特徴量エンジニアリング オペレーターにより、複雑なデータ機能を完成させるためのコーディングを必要とせずに、主要なデータ生成機能から高レベルのデータ生成機能までカバーします。
2. ゼロしきい値 SQL ツール
データの生成と処理は、データを取得して分析するための最初のステップです。
技術者以外のユーザーの場合、SQL 構文の使用には一定のしきい値があり、同時にローカル ファイルを定期的に更新できないため、毎回ダッシュボードを手動でやり直す必要があります。データを取得するために必要な技術的な人員は多くの場合スケジュール設定が必要であり、データ取得の適時性と満足度が大幅に低下するため、ゼロコード データ構築ツールを使用することが特に重要です。
以下に、ゼロしきい値データ処理が業務にどのように適用されるかを示す 2 つの典型的なシナリオを示します。
2.1 [シナリオ 1] 思ったとおりの結果が得られ、データ処理プロセスは視覚的に完了します。
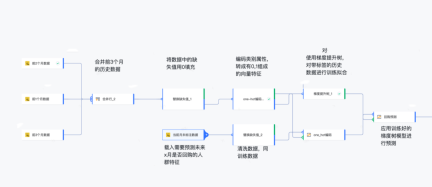
製品操作の繰り返しでさまざまなデータのタイムリーな入力フィードバックが緊急に必要な場合、データ処理プロセスは視覚化によって抽象化および構築できます。モジュラー ドラッグ オペレーターはデータ処理プロセスを構築します。
日付と都市の粒度で注文件数と注文金額を取得し、日別消費量データ上位10位の都市データを取得したい場合の操作は以下のとおりです。
#一般的なデータ処理プロセス | ビジュアル モデリング プロセス # |
||||
|
|

一般的なデータ処理プロセス |
ビジュアルモデリングプロセス |
|
CSV ファイル/LaskSheet をアップロードしてデータ入力を構築できます
3. AI データ マイニングはもはや手の届かないものではありません基本的なデータ クリーニングではデータ構築とデータ分析を満足できなくなった場合、AI アルゴリズムのサポートが必要になりますデータにさらに隠れた価値がある場合。アルゴリズム チームの学生は、ビジュアル チャートをうまく操作できず、すぐに適用できる優れたデータを生成できないことに悩む可能性がありますが、一般のユーザーは、このアルゴリズムの出現を抑制するための AI コードの高いしきい値によって直接抑制される可能性があり、需要が高まっていますしかし需要が怖い 浅すぎて価値が評価できない 現時点ではアルゴリズムマイニングは贅沢品になってしまいます。 DataWind のビジュアル モデリングには、30 を超える一般的な AI オペレーター機能がカプセル化されています。ユーザーは、アルゴリズムの機能を理解し、構成を通じてアルゴリズム オペレーターの入力とトレーニング目標を構成するだけで、モデルのトレーニングを完了できます。予測を迅速に取得できます。他の構成されたデータコンテンツに基づく結果。
4. マルチシナリオとマルチタスクの構築、管理はもはや分散化ではないデータ アナリストとして、データ セットを構築し、データ ダッシュボードを構築するための日々の作業もたくさんあります。ただし、通常、データ ウェアハウスから取得される下部テーブルは幅の広いテーブルになり、これに基づいて、さまざまなシナリオ要件に従ってさまざまなデータ セット タスクが構築されます。 その後の使用では、類似したデータ セットがさらに多くなることがよくありますが、特定のロジックを十分に比較および確認することはできません。このとき、すべてのデータセットロジックが 1 つのデータセット内に構成および生成され、各データセットがタスクプロセスを通じて判断および定義できるようになれば素晴らしいと思います。 このシナリオでは、DataWind のビジュアル モデリング機能も非常にうまく完成させることができます。ビジュアル モデリング機能は、単一のデータ セットを複数のロジック プロセスで同時に処理して複数のデータ セットを生成することをサポートします。注文データとユーザー データの処理を例に挙げます。 このように、1 つのタスクと 2 つのデータ入力によって 4 つのデータ セットが生成され、これら 4 つのデータ セットでデータ主体ドメインを構築し、以降の関連データを使用できるようになります。タスクが出力したデータセットが使用されます。
5. 会社概要Volcano Engine Intelligent Data Insight DataWind は、詳細なレベルでのセルフサービス分析をサポートする強化されたプラットフォームです。ビッグデータのレベル、ABI プラットフォーム。データ アクセス、データ統合からクエリと分析に至るまで、データは最終的にビジュアル データ ポータル、デジタル大型スクリーン、管理コックピットの形でビジネス ユーザーに提供され、データが価値を発揮できるようになります。 |








以上が火山エンジン ツール テクノロジーの共有: AI を使用してデータ マイニングを完了し、ゼロしきい値で SQL 書き込みを完了しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

WebStorm Mac版
便利なJavaScript開発ツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

