



大規模な言語モデルには素晴らしい機能がありますが、規模が大きいため、その展開に必要なコストが膨大になることがよくあります。ワシントン大学は、Google Cloud Computing Artificial Intelligence Research Institute および Google Research と協力して、この問題をさらに解決し、モデルのトレーニングを支援するステップバイステップ蒸留パラダイムを提案しました。 LLM と比較して、この方法は小さなモデルをトレーニングして特定のタスクに適用する場合に効果的であり、従来の微調整や蒸留よりも必要なトレーニング データが少なくなります。ベンチマーク タスクでは、770M T5 モデルが 540B PaLM モデルよりも優れたパフォーマンスを示しました。印象的なことに、彼らのモデルは利用可能なデータの 80% しか使用していませんでした。

大規模言語モデル (LLM) は優れた少数ショット学習を実証していますが、しかし、このような大規模なモデルを実際のアプリケーションに展開することは困難です。 1,750 億パラメータ規模の LLM に対応する専用インフラストラクチャには、少なくとも 350 GB の GPU メモリが必要です。さらに、今日の最先端の LLM は 5,000 億を超えるパラメータで構成されており、より多くのメモリとコンピューティング リソースが必要になります。このようなコンピューティング要件は、低遅延を必要とするアプリケーションはもちろんのこと、ほとんどのメーカーにとっては手の届かないものです。
大規模モデルの問題を解決するために、デプロイ担当者は多くの場合、代わりに小規模な特定のモデルを使用します。これらの小さなモデルは、微調整や蒸留などの一般的なパラダイムを使用してトレーニングされます。微調整では、人間が注釈を付けた下流のデータを使用して、事前トレーニングされた小規模なモデルをアップグレードします。蒸留では、より大きな LLM によって生成されたラベルを使用して、同様に小さなモデルをトレーニングします。残念ながら、これらのパラダイムにはモデル サイズを縮小する一方でコストがかかります。LLM と同等のパフォーマンスを達成するには、微調整には高価な人間によるラベルが必要であり、蒸留には入手が困難な大量のラベルなしデータが必要です。
「Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes」というタイトルの論文で、ワシントン大学と Google の研究者が新しいシンプルなメカニズムを発表しました。 , ステップバイステップの蒸留は、より少ないトレーニング データを使用して小規模なモデルをトレーニングするために導入されています。このメカニズムにより、LLM の微調整と抽出に必要なトレーニング データの量が削減され、その結果、モデル サイズが小さくなります。

#紙のリンク: https://arxiv.org/pdf/2305.02301 v1.pdf
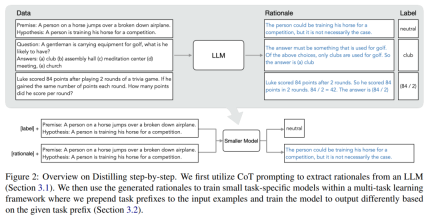
#このメカニズムの核心は、視点を変えて、LLM をノイズ ラベルのソースとしてではなく、推論できるエージェントとしてみなすことです。 LLM は、モデルによって予測されたラベルを説明およびサポートするために使用できる自然言語の理論的根拠を生成できます。たとえば、「紳士はゴルフ用品を持ち歩いていますが、何を持っていると思いますか? (a) クラブ、(b) 講堂、(c) 瞑想センター、(d) 会議、(e) 教会」と質問された場合、LLM は「(a)」と答えることができます。 ) クラブ」を思考連鎖 (CoT) 推論によって解釈し、「答えはゴルフをプレイするために使用されるものに違いない」と説明することでこのラベルを合理化します。上記の選択肢のうち、ゴルフに使用するクラブのみです。これらの位置合わせを、マルチタスク トレーニング設定で小規模なモデルをトレーニングし、ラベル予測と位置合わせ予測を実行するための追加の豊富な情報として使用します。
図 1 に示すように、段階的蒸留では、LLM の 1/500 未満のパラメーター数でタスク固有の小さなモデルを学習できます。また、段階的蒸留では、従来の微調整や蒸留よりもはるかに少ないトレーニング サンプルを使用します。

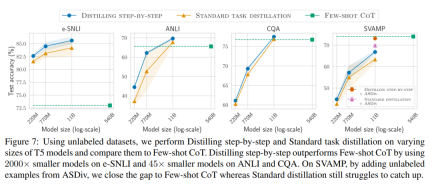
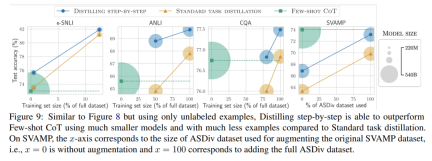
ラベルのないデータのみがある場合、小規模モデルのパフォーマンスは LLM のパフォーマンスより優れています。11B T5 モデルを使用した場合のみ、540B の PaLM のパフォーマンスを超えます。改善されました。 研究ではさらに、小規模なモデルのパフォーマンスが LLM よりも悪い場合、段階的蒸留の方が標準的な蒸留方法よりも追加のラベルなしデータを効果的に利用できることが示されています。LLM のパフォーマンスと同等の小規模なモデルを作成します。 研究者らは、LLM の推論能力を使用して予測を予測し、データ効率の高い方法で小規模なモデルをトレーニングする、段階的蒸留の新しいパラダイムを提案しました。マナー、モデル。全体的なフレームワークを図 2 に示します。 パラダイムには 2 つの簡単なステップがあります。まず、LLM とラベルのないデータを与えます。 set は、LLM に出力ラベルとラベルの位置揃えを生成するように指示します。理論的根拠は自然言語で説明され、モデルによって予測されたラベルのサポートを提供します (図 2 を参照)。正当化は、現在の自己教師あり LLM の新たな動作特性です。 次に、タスク ラベルに加えて、これらの理由を使用して、より小さな下流モデルをトレーニングします。率直に言って、理由は、入力が特定の出力ラベルにマップされる理由を説明するための、より豊富で詳細な情報を提供します。 研究者らは、実験で段階的蒸留の有効性を検証しました。まず、標準的な微調整およびタスク蒸留手法と比較して、段階的蒸留ははるかに少ない数のトレーニング サンプルでより優れたパフォーマンスを達成するのに役立ち、小さなタスク固有のモデルを学習する際のデータ効率が大幅に向上します。
段階的蒸留
実験結果
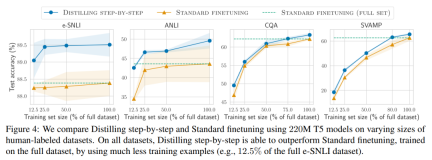
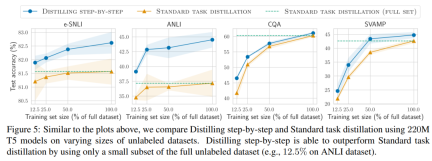
#第二に、研究は次のことを示しています。段階的蒸留方法は、より小さいモデル サイズで LLM のパフォーマンスを上回り、LLM と比較して導入コストが大幅に削減されることがわかりました。
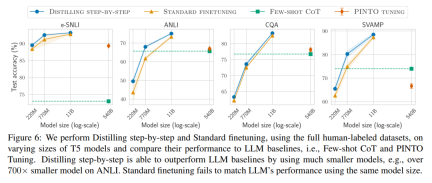
#
以上が蒸留は段階的に行うこともできます。新しい方法により、小型モデルを 2000 倍のサイズの大型モデルと同等にできるようになります。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM
踊りましょう:私たちの人間のニューラルネットを微調整するための構造化された動きApr 27, 2025 am 11:09 AM科学者は、彼らの機能を理解するために、人間とより単純なニューラルネットワーク(C. elegansのものと同様)を広く研究してきました。 ただし、重要な疑問が生じます。新しいAIと一緒に効果的に作業するために独自のニューラルネットワークをどのように適応させるのか
 新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AM
新しいGoogleリークは、Gemini AIのサブスクリプションの変更を明らかにしますApr 27, 2025 am 11:08 AMGoogleのGemini Advanced:Horizonの新しいサブスクリプションティア 現在、Gemini Advancedにアクセスするには、1か月あたり19.99ドルのGoogle One AIプレミアムプランが必要です。 ただし、Android Authorityのレポートは、今後の変更を示唆しています。 最新のGoogle p
 データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM
データ分析の加速がAIの隠されたボトルネックをどのように解決しているかApr 27, 2025 am 11:07 AM高度なAI機能を取り巻く誇大宣伝にもかかわらず、エンタープライズAIの展開内に大きな課題が潜んでいます:データ処理ボトルネック。 CEOがAIの進歩を祝う間、エンジニアはクエリの遅い時間、過負荷のパイプライン、
 MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AM
MarkitDown MCPは、任意のドキュメントをマークダウンに変換できます!Apr 27, 2025 am 09:47 AMドキュメントの取り扱いは、AIプロジェクトでファイルを開くだけでなく、カオスを明確に変えることです。 PDF、PowerPoint、Wordなどのドキュメントは、あらゆる形状とサイズでワークフローをフラッシュします。構造化された取得
 建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AM
建物のエージェントにGoogle ADKを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:42 AMGoogleのエージェント開発キット(ADK)のパワーを活用して、実際の機能を備えたインテリジェントエージェントを作成します。このチュートリアルは、ADKを使用して会話エージェントを構築し、GeminiやGPTなどのさまざまな言語モデルをサポートすることをガイドします。 w
 効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AM
効果的な問題解決のためにLLMを介したSLMの使用 - 分析VidhyaApr 27, 2025 am 09:27 AMまとめ: Small Language Model(SLM)は、効率のために設計されています。それらは、リソース不足、リアルタイム、プライバシーに敏感な環境の大手言語モデル(LLM)よりも優れています。 特にドメインの特異性、制御可能性、解釈可能性が一般的な知識や創造性よりも重要である場合、フォーカスベースのタスクに最適です。 SLMはLLMSの代替品ではありませんが、精度、速度、費用対効果が重要な場合に理想的です。 テクノロジーは、より少ないリソースでより多くを達成するのに役立ちます。それは常にドライバーではなく、プロモーターでした。蒸気エンジンの時代からインターネットバブル時代まで、テクノロジーの力は、問題の解決に役立つ範囲にあります。人工知能(AI)および最近では生成AIも例外ではありません
 コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AM
コンピュータービジョンタスクにGoogle Geminiモデルを使用する方法は? - 分析VidhyaApr 27, 2025 am 09:26 AMコンピュータービジョンのためのGoogleGeminiの力を活用:包括的なガイド 大手AIチャットボットであるGoogle Geminiは、その機能を会話を超えて拡張して、強力なコンピュータービジョン機能を網羅しています。 このガイドの利用方法については、
 Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini:GoogleはOpenaiよりもうまくやることができますか?Apr 27, 2025 am 09:20 AM2025年のAIランドスケープは、GoogleのGemini 2.0 FlashとOpenaiのO4-Miniの到着とともに感動的です。 数週間離れたこれらの最先端のモデルは、同等の高度な機能と印象的なベンチマークスコアを誇っています。この詳細な比較


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

メモ帳++7.3.1
使いやすく無料のコードエディター

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

WebStorm Mac版
便利なJavaScript開発ツール

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール
ホットトピック
 7759
7759 15164414139952129325123429
15164414139952129325123429