
ホームページ >テクノロジー周辺機器 >AI >大規模モデルが「オープンソースの季節」の到来を告げ、過去 1 か月間でオープンソース LLM とデータセットを総括
大規模モデルが「オープンソースの季節」の到来を告げ、過去 1 か月間でオープンソース LLM とデータセットを総括

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-18 16:31:131887ブラウズ
少し前に、Google が漏洩した内部文書では、表面的には OpenAI と Google が大規模な AI モデルで互いに追いかけ合っているように見えても、本当の勝者はこの 2 社にはないかもしれない、という見解が表明されていました。静かに台頭しつつある第三勢力。この力は「オープンソース」です。
Meta の LLaMA オープン ソース モデルを中心に、コミュニティ全体が OpenAI や Google の大規模モデルと同様の機能を備えたモデルを急速に構築しています。さらに、オープン ソース モデルは反復処理が速く、よりカスタマイズ可能です。プライバシー。
最近、ウィスコンシン大学マディソン校の元助教授であり、新興企業 Lightning AI の最高 AI 教育責任者である Sebastian Raschka 氏は、この 1 か月間で次のように述べました。オープンソースにとっては非常に困難でした。素晴らしい。
しかし、非常に多くの大規模言語モデル (LLM) が次々と登場するため、すべてのモデルをしっかりと把握しておくのは簡単ではありません。そこで、この記事では、Sebastian が最新のオープンソース LLM とデータセットに関するリソースと調査洞察を共有します。
論文と動向
先月、非常に多くの研究論文が発表されました。その中から選択するのは難しい場合があります。詳細な議論のために最もお気に入りのものを選択してください。セバスチャンは、より強力なモデルを単に実証するよりも、追加の洞察を提供する論文を好みます。この点を考慮して、最初に彼の目に留まったのは、Eleuther AI とイェール大学などの研究機関の研究者が共著した Pythia 論文でした。

#論文アドレス: https://arxiv.org/pdf/2304.01373.pdf
#Pythia: 大規模トレーニングから洞察を得る
大規模モデルのオープンソース Pythia ファミリは、実際には別のものです。自己回帰デコード コンテナ スタイル モデル (GPT のようなモデル) に代わる興味深い代替手段。この論文では、トレーニング メカニズムに関するいくつかの興味深い洞察が明らかにされ、70M から 12B パラメーターにわたる対応するモデルが紹介されています。
Pythia モデル アーキテクチャは GPT-3 に似ていますが、フラッシュ アテンション (LLaMA など) や回転位置埋め込み (PaLM など) などの改良が含まれています。同時に、Pythia は 800 GB の多様なテキスト データ セット Pile 上で 300B トークンを使用してトレーニングされました (通常の Pile では 1 エポック、重複排除 Pile では 1.5 エポック)。
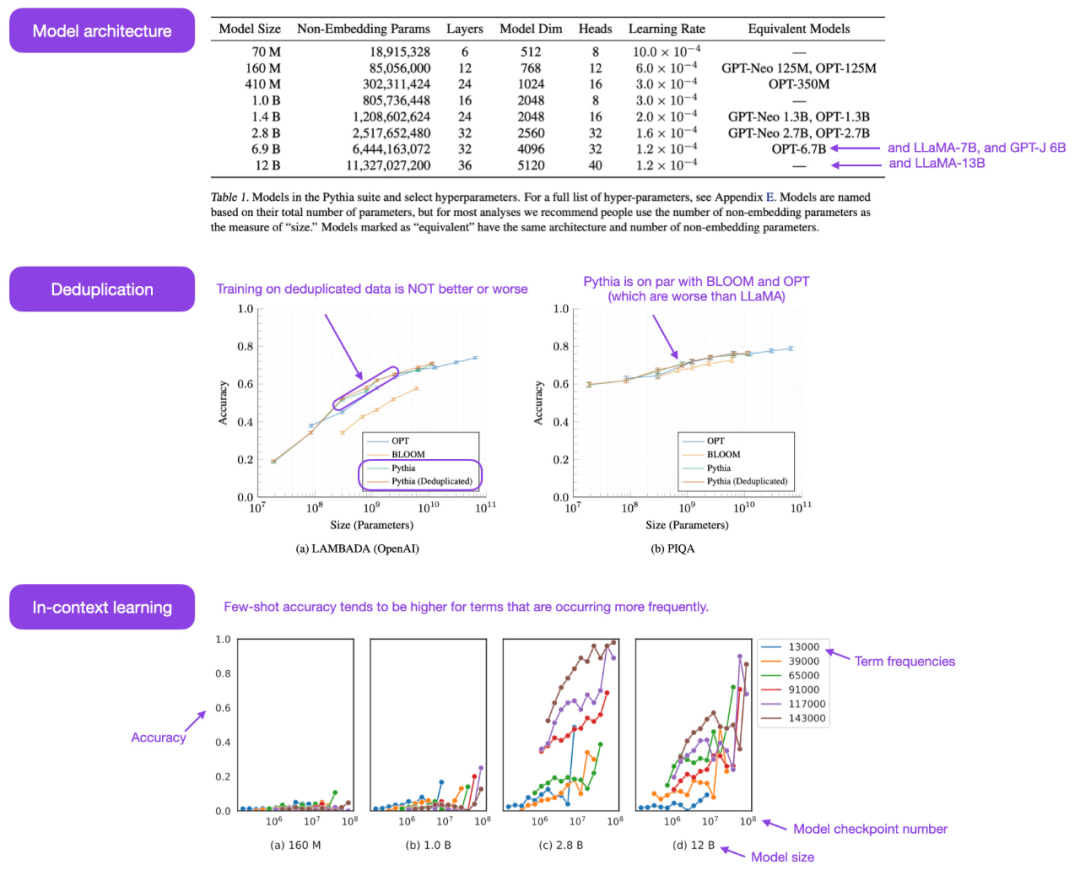
以下は、Pythia 論文からのいくつかの洞察と考察です:
- In Will繰り返されるデータ (つまり、トレーニング エポック > 1) に対するトレーニングが何らかの影響を与える場合、影響はありますか?結果は、データ重複排除がパフォーマンスを向上させたり、悪影響を与えたりしないことを示しています;
- トレーニング コマンドはメモリに影響しますか?残念ながら、そうではないことが判明しました。申し訳ありませんが、そうなった場合、トレーニング データの順序を変更することで厄介な逐語的記憶の問題を軽減できるためです。
- バッチ サイズを 2 倍にするとトレーニング時間を半分にできますが、収束は損なわれません。
オープンソース データ
先月は、オープンソース AI にとって特に刺激的な出来事がいくつかありました。 LLM のオープンソース実装とオープンソース データ セットの大規模なセット。これらのデータセットには、Databricks Dolly 15k、命令の微調整用の OpenAssistant Conversations (OASST1)、および事前トレーニング用の RedPajama が含まれます。データの収集とクリーニングは現実世界の機械学習プロジェクトの 90% を占めているにもかかわらず、この作業を楽しんでいる人はほとんどいないため、これらのデータセットの取り組みは特に賞賛に値します。
Databricks-Dolly-15 データセット
Databricks-Dolly-15 は、LLM Fine-15 に使用されるデータセットです。数千人の DataBricks 従業員によって作成された 15,000 を超える命令ペアのチューニング セット (InstructGPT や ChatGPT などのトレーニング システムと同様)。
OASST1 データセット
OASST1 データセットは、作成された ChatGPT アシスタントのような会話のコレクションで事前トレーニングされた LLM を微調整するために使用されます。人間によって注釈が付けられ、35 の言語で書かれた 161,443 件のメッセージと 461,292 件の品質評価が含まれています。これらは、完全に注釈が付けられた 10,000 を超えるダイアログ ツリーに編成されています。
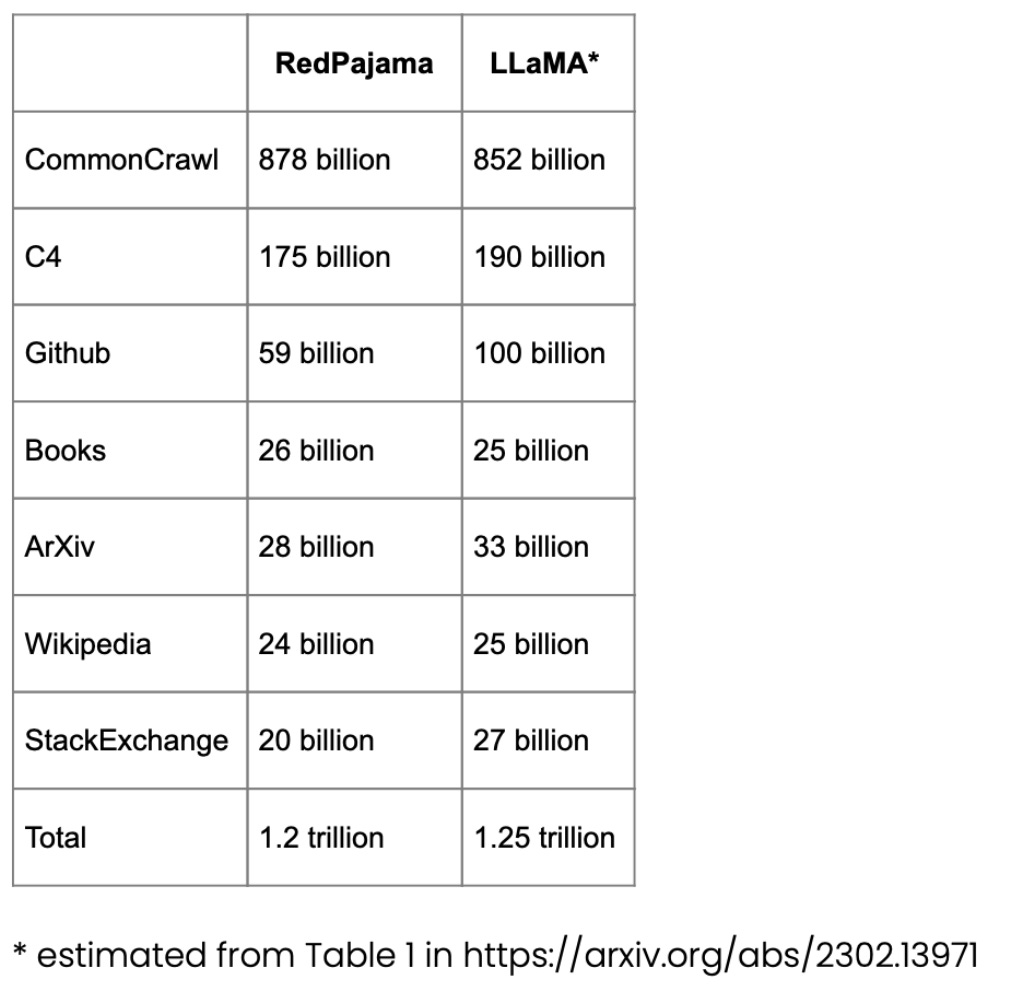
#事前トレーニングに使用される RedPajama データセット

RedPajama は、Meta の SOTA LLaMA モデルに似た、LLM 事前トレーニング用のオープンソース データ セットです。このデータセットは、現在クローズド ソース ビジネス モデルか部分的にのみオープン ソースである最も一般的な LLM に対するオープン ソースの競合相手を作成することを目的としています。
RedPajama の大部分は、英語のサイトをフィルタリングする CommonCrawl で構成されていますが、Wikipedia の記事は 20 の異なる言語をカバーしています。
#LongForm Dataset
Paper《 「LongForm: コーパス抽出による長文生成のための命令チューニングの最適化」では、C4やWikipediaなどの既存のコーパスとその命令をもとに手動で作成した文書群を紹介し、長文生成に適した命令チューニングデータセットを作成します。
論文アドレス: https://arxiv.org/abs/2304.08460
Alpaca Libre プロジェクト
#Alpaca Libre プロジェクトは、Anthropics HH-RLHF リポジトリにある 100,000 個の MIT ライセンス デモを Alpaca 互換形式に変換することで、Alpaca プロジェクトを再作成することを目的としています。
オープンソース データ セットの拡張
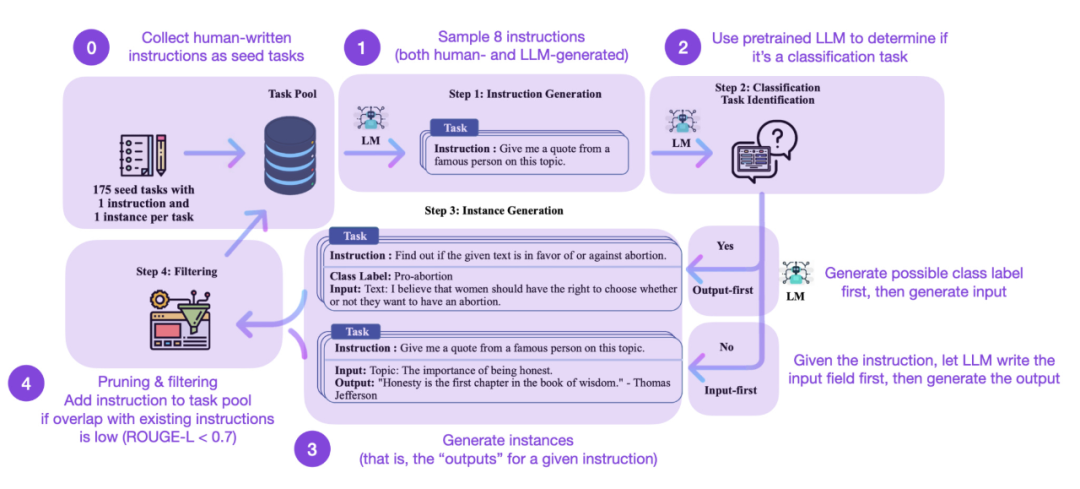
命令の微調整は、GPT-3 から進化する方法です。事前トレーニングされた基本モデルのようなものから、より強力な ChatGPT のような大規模言語モデルへの鍵となります。 Databricks-Dolly-15 などのオープンソースの人生成命令データセットは、これを達成するのに役立ちます。しかし、さらに規模を拡大するにはどうすればよいでしょうか?追加のデータを収集しないことはできますか? 1 つのアプローチは、LLM を独自の反復からブートストラップすることです。 Self-Instruct メソッドは 5 か月前に提案されましたが (今日の標準からすると時代遅れです)、それでも非常に興味深いメソッドです。アノテーションをほとんど必要としない方法である Self-Instruct のおかげで、事前トレーニングされた LLM を命令と調整できることを強調する価値があります。それはどのように機能しますか?つまり、次の 4 つのステップに分けることができます。
- 最初のステップは、一連の手動で書かれた命令 (この場合は 175) とサンプルを含むシード タスク プールです。指示;
- 次に、事前トレーニング LLM (GPT-3 など) を使用してタスク カテゴリを決定します;
- 次に、新しい指示を与えますLLM は応答を生成します;
- # そして最後に、命令をタスク プールに追加する前に応答を収集、トリミング、およびフィルタリングします。
しかし、もちろん、LLM を評価するための最も重要な基準は人間の評価者に尋ねることです。人間の評価に基づくと、Self-Instruct は、基本的な LLM だけでなく、教師ありの方法で人間の指示データセットでトレーニングされた LLM (SuperNI、T0 Trainer など) よりも優れています。しかし、興味深いことに、Self-Instruct は、ヒューマン フィードバックを伴う強化学習 (RLHF) でトレーニングされたメソッドよりも優れたパフォーマンスを発揮するわけではありません。
人工的に生成されたトレーニング データ セットと合成トレーニング データ セット 人工的に生成された命令データ セットと自己命令データ セット、どちらがより有望ですか? Woolen布?セバスチャンは両方に未来を見ています。手動で生成した命令データ セット (例: 15k 命令の databricks-dolly-15k) から始めて、自己命令を使用して拡張してみてはいかがでしょうか?論文「拡散モデルからの合成データにより ImageNet 分類が向上」では、実際の画像トレーニング セットと AI 生成画像を組み合わせることでモデルのパフォーマンスを向上できることが示されています。これがテキスト データにも当てはまるかどうかを調査してみると興味深いでしょう。 論文アドレス: https://arxiv.org/abs/2304.08466 最近の論文「Better Language」 「自己改善によるコードのモデル」は、この方向の研究です。研究者らは、事前トレーニングされた LLM が独自に生成したデータを使用すると、コード生成タスクを改善できることを発見しました。 論文アドレス: https://arxiv.org/abs/2304.01228 少ないほど良い少ないほど良い? さらに、ますます大規模なデータ セットでのモデルの事前トレーニングと微調整に加えて、より小さなデータのパフォーマンスを向上させるにはどうすればよいでしょうか?効率はどうですか?論文「Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes」では、蒸留メカニズムを使用して、使用するトレーニング データは少ないが標準の微調整パフォーマンスを超える、タスク固有の小さなモデルを管理することを提案しています。 論文アドレス: https://arxiv.org/abs/2305.02301 オープンソース LLM の追跡 オープンソース LLM の数は爆発的に増加しており、一方で、これは非常に良い開発傾向です (管理するものと比較して)。有料 API を介してモデルを取得します)が、その一方で、すべてを追跡するのは面倒になる可能性があります。次の 4 つのリソースは、モデルの関係、基礎となるデータセット、さまざまなライセンス情報など、最も関連性の高いモデルのさまざまな概要を提供します。 最初のリソースは、論文「エコシステム グラフ: 基盤モデルのソーシャル フットプリント」に基づくエコシステム グラフ Web サイトです。ここには、次の表と対話型の依存関係グラフ (ここには示されていません) が提供されています。 。 このエコシステム図は、Sebastian がこれまでに見た中で最も包括的なリストですが、あまり人気のない LLM が多数含まれているため、少し混乱する可能性があります。対応する GitHub リポジトリを確認すると、少なくとも 1 か月間更新されていることがわかります。新しいモデルが追加されるかどうかも不明です。 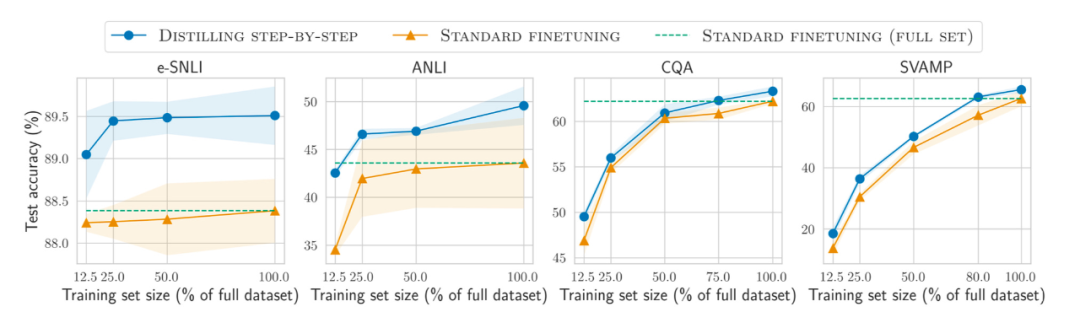
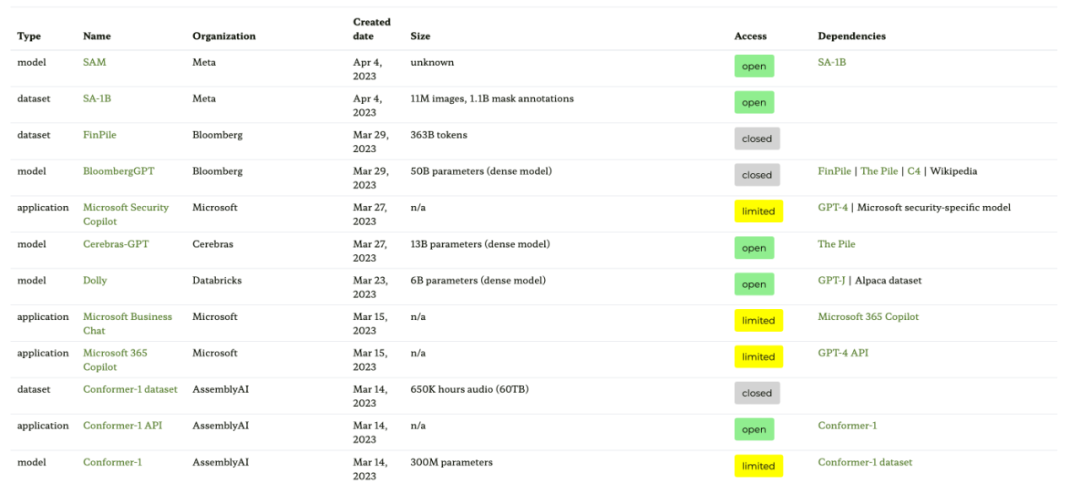
- 紙のアドレス: https://arxiv.org/abs/2303.15772
- # 生態系グラフ Web サイトのアドレス: https://crfm.stanford.edu/ecosystem-graphs/index.html?mode=table
読者は、非常に美しく明確な視覚的な LLM 進化ツリーを見てきましたが、いくつかの小さな疑問もあります。なぜ底部が元の変圧器アーキテクチャから始まらないのかは不明です。また、オープン ソースのラベルはあまり正確ではありません。たとえば、LLaMA はオープン ソースとしてリストされていますが、重みはオープン ソース ライセンスの下では利用できません (推論コードのみが利用可能です)。
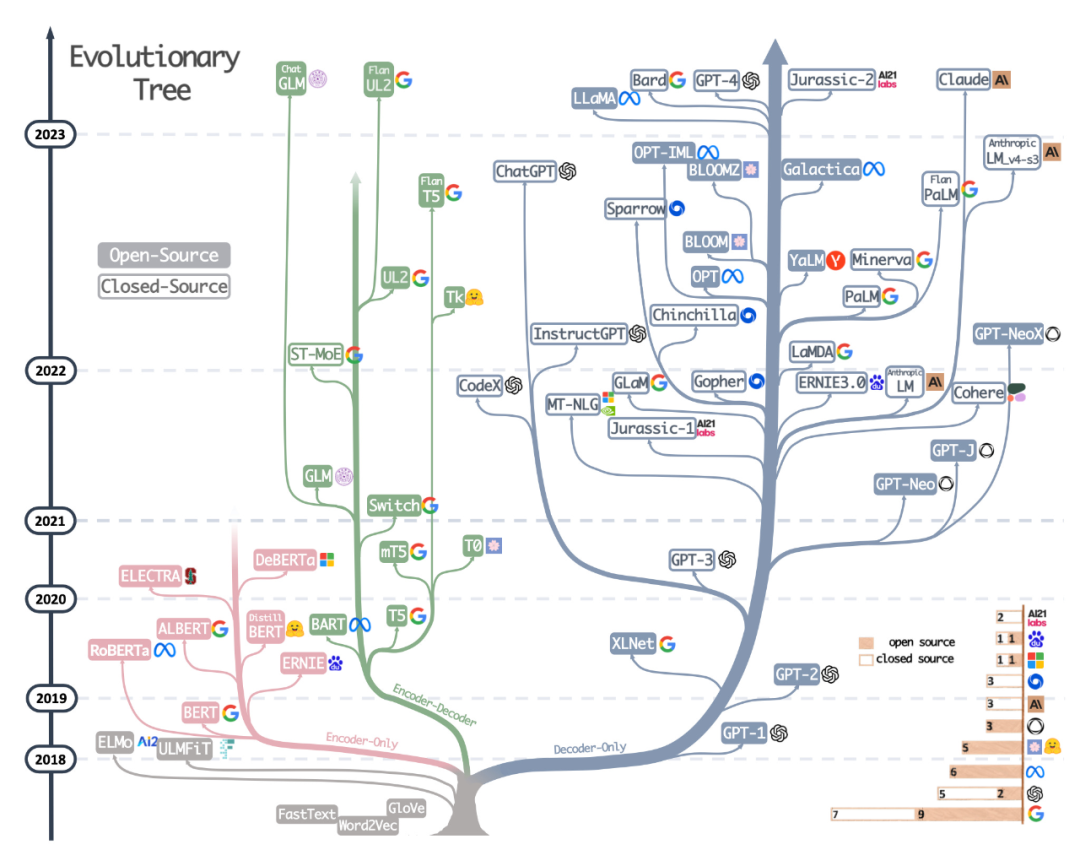
3 番目のリソースは、Sebastian の同僚 Daniela Dapena がブログ「言語モデルの究極の戦い: Lit-LLaMA vs GPT3.5 vs Bloom vs...」から作成した表です。 以下の表は他のリソースより小さいですが、モデルの寸法とライセンス情報が含まれているという利点があります。この表は、これらのモデルをプロジェクトで使用する予定がある場合に非常に役立ちます。 ブログアドレス: https://lightning.ai/pages/community/community-Discussions/the-ultimate-battle-of - language-models-lit-llama-vs-gpt3.5-vs-bloom-vs/ 4 番目のリソースは、LLaMA-Cult-and-More 概要表です。には、微調整方法とハードウェアのコストに関する追加情報が記載されています。 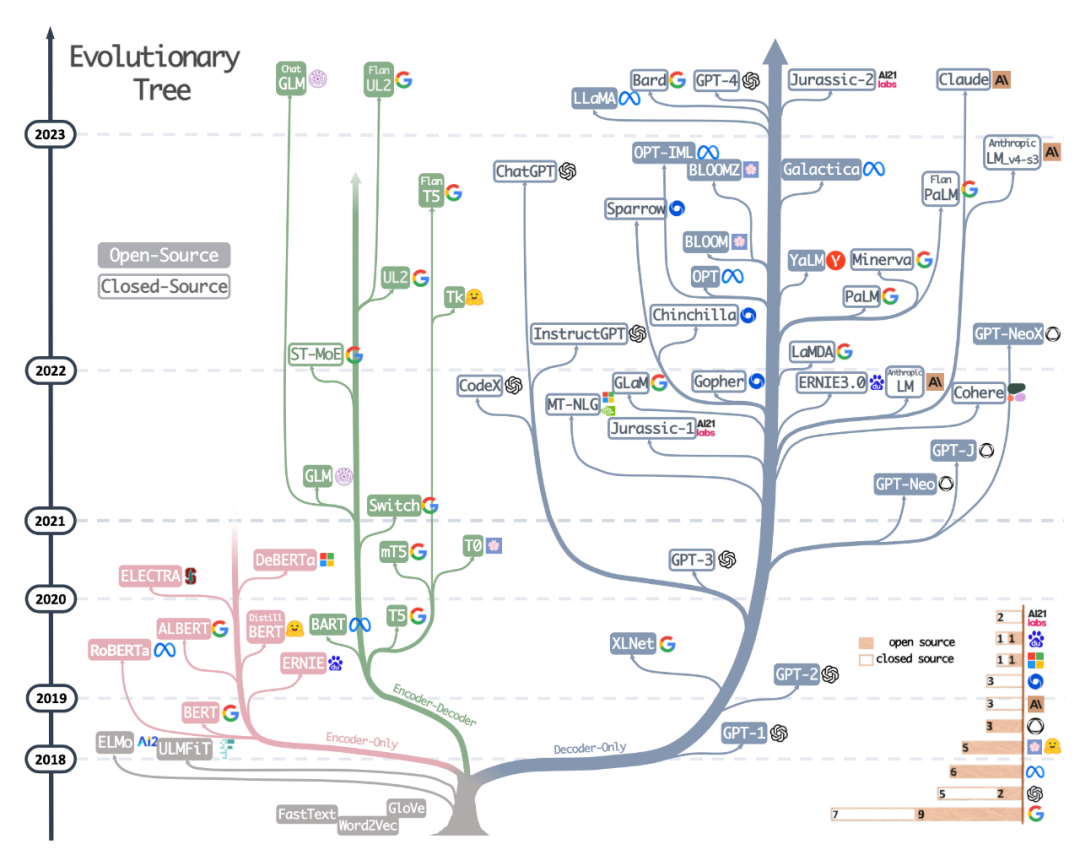
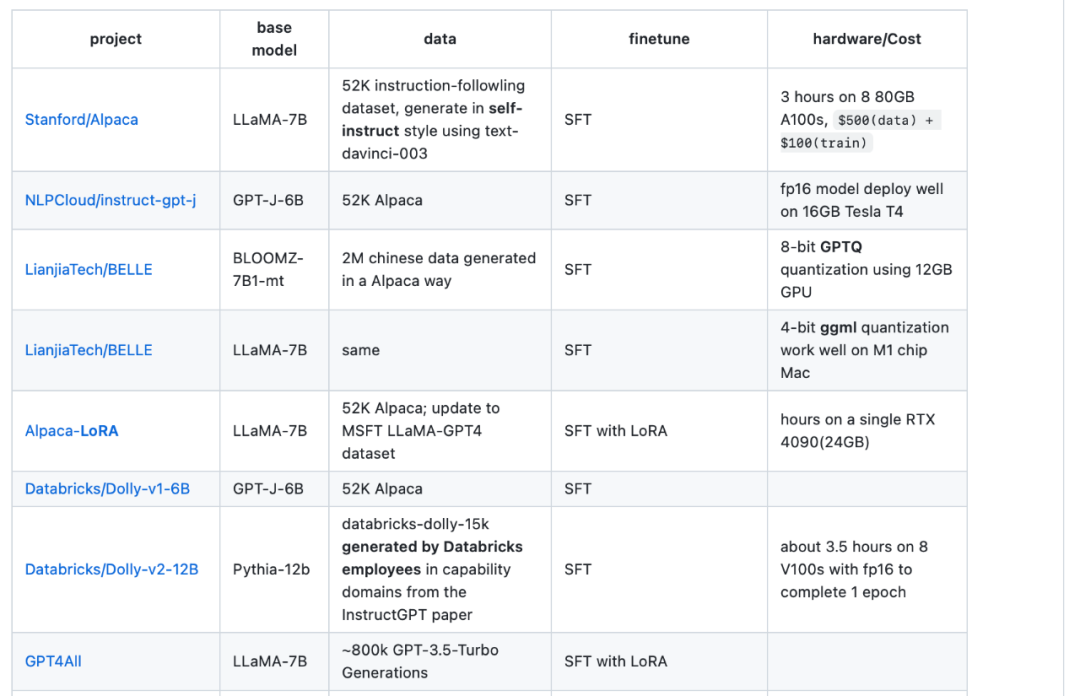
概要テーブルのアドレス: https://github.com/shm007g/LLaMA-Cult-and- More/blob/main/chart.md
LLaMA-Adapter V2 を使用してマルチモーダル LLM
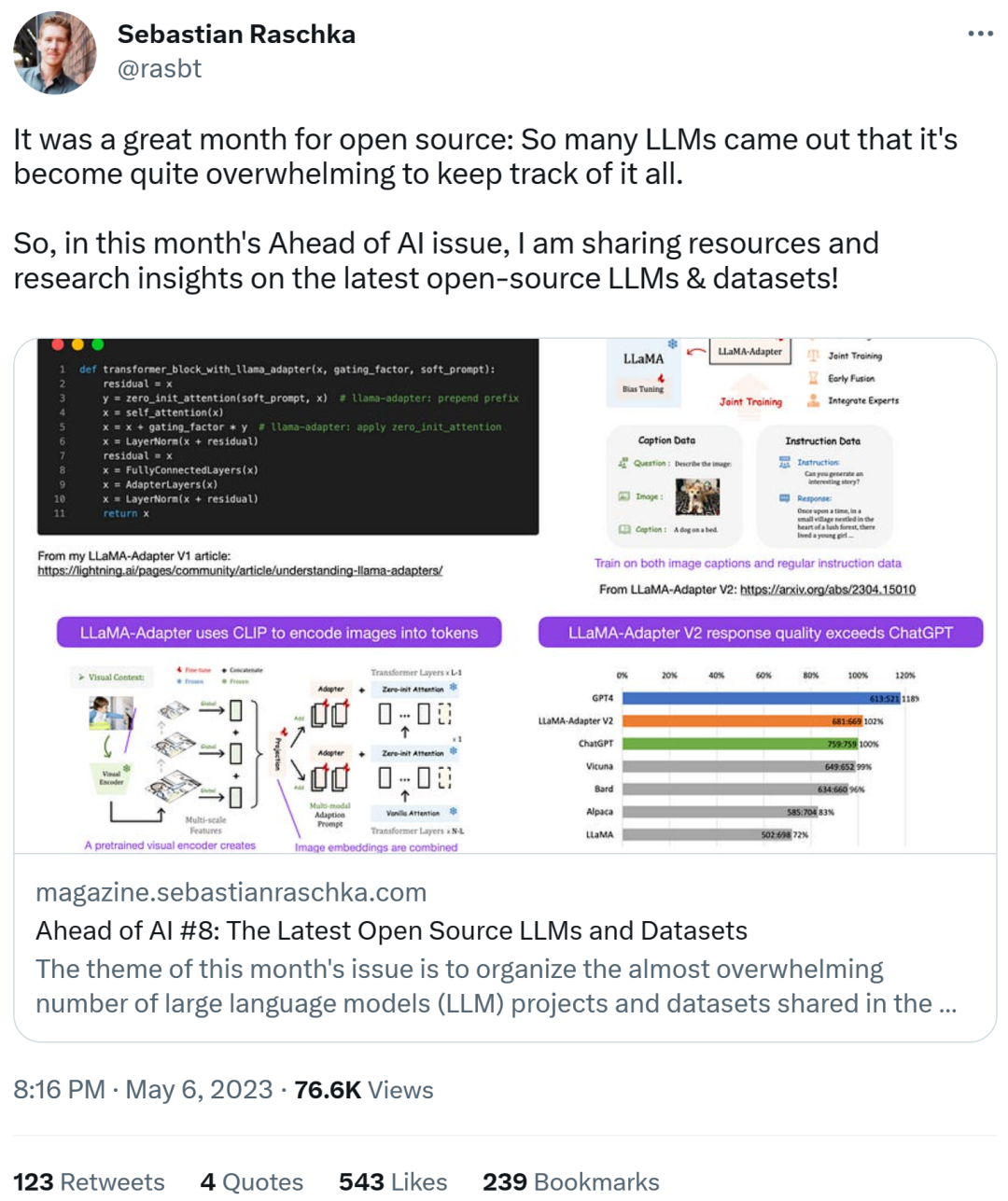
# を微調整する##セバスチャンは、今月はさらにマルチモーダル LLM モデルが登場すると予測しているので、最近リリースされた論文「LLaMA-Adapter V2: Parameter-Efficient Visual struction Model」について話さなければなりません。まず、LLaMA-Adapterとは何なのかをおさらいしましょう。これは、以前のトランスフォーマー ブロックを変更し、トレーニングを安定させるためのゲート メカニズムを導入する、パラメーター効率の高い LLM 微調整手法です。
論文アドレス: https://arxiv.org/abs/2304.15010
LLaMA-Adapter メソッドの使用, 研究者らは、52k 命令ペアで 7B パラメーターの LLaMA モデルをわずか 1 時間 (8 つの A100 GPU) で微調整することができました。新しく追加された 1.2M パラメータ (アダプター層) のみが微調整されましたが、7B LLaMA モデルはまだフリーズしたままです。
LLaMA-Adapter V2 の焦点はマルチモダリティ、つまり画像入力を受け取ることができるビジュアル コマンド モデルの構築です。元の V1 はテキスト トークンと画像トークンを受信できましたが、画像は完全には調査されていませんでした。
LLaMA アダプター V1 から V2 まで、研究者は次の 3 つの主要な技術を通じてアダプター メソッドを改良しました。
- 初期の視覚的知識の融合: 適応された各レイヤーで視覚的なキューと適応されたキューを融合する代わりに、視覚的なトークンが最初のトランスフォーマー ブロック内の単語トークンに接続されます。 #より多くのパラメーターを使用します。すべての正規化レイヤーをフリーズ解除し、トランスフォーマー ブロックの各線形レイヤーにバイアス ユニットとスケーリング係数を追加します。
- 素のパラメーターを使用したジョイント トレーニング: 字幕データの場合は視覚投影層のみがトレーニングされ、命令が続くデータの場合はアダプテーション層 (および上記で新しく追加されたパラメーター) のみがトレーニングされます。
残念ながら、LLaMA-Adapter V2 の論文では、V1 の論文に含まれている計算パフォーマンスのベンチマークが省略されていますが、V2 は完全に微調整された方法よりもはるかに高速であると想定できます。

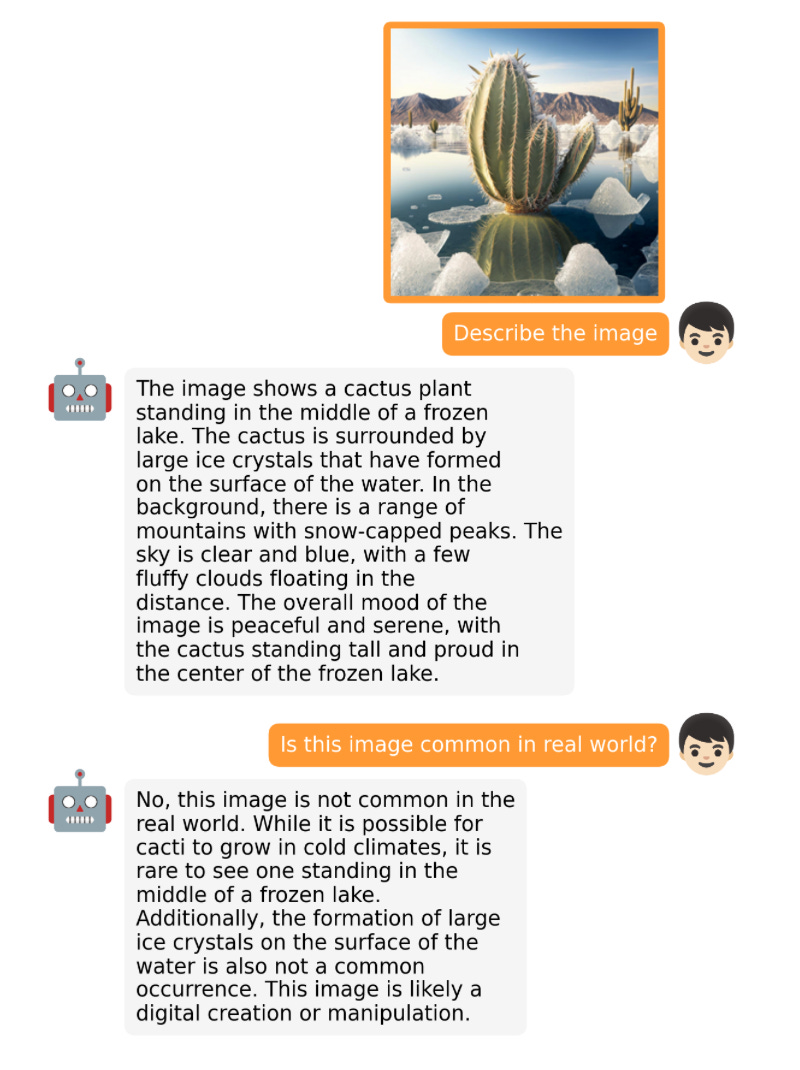
大規模なモデルの開発は非常に速いので、すべてをリストすることはできません。今月リリースされた有名なオープンソース LLM とチャットボットには、Open-Assistant、Baize、StableVicuna、ColossalChat、Mosaic の MPT などが含まれます。 。さらに、特に興味深い 2 つのマルチモーダル LLM を以下に示します。 OpenFlamingo OpenFlamingo は、Google DeepMind が昨年リリースした Flamingo モデルのオープンソース コピーです。 OpenFlamingo は、LLM にマルチモーダル画像推論機能を提供し、テキストと画像の入力をインターリーブできるようにすることを目的としています。 #MiniGPT-4
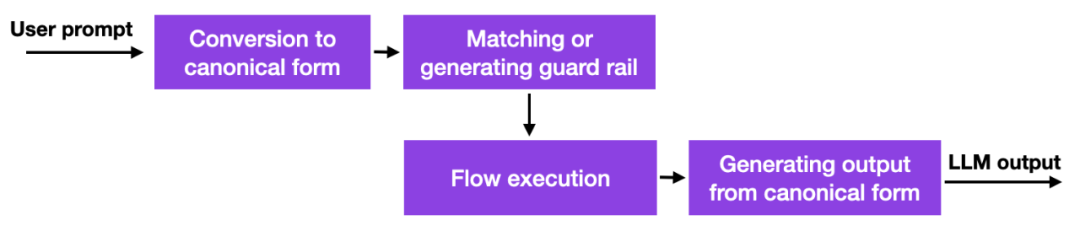
これと大規模な言語モデルの出現により、多くの企業がそれをどのように導入するか、また導入すべきかどうかを検討しており、セキュリティ上の懸念が特に顕著になっています。優れた解決策はまだありませんが、少なくとももう 1 つ有望なアプローチがあります。NVIDIA は、LLM 幻覚問題を解決するツールキットをオープンソース化しました。
簡単に言うと、この方法の仕組みは、手動で管理する必要があるハードコーディングされたプロンプトへのデータベース リンクを使用するということです。その後、ユーザーがプロンプトを入力すると、そのコンテンツは最初にデータベース内の最も類似したエントリと照合されます。その後、データベースはハードコードされたプロンプトを返し、それが LLM に渡されます。したがって、ハードコーディングされたプロンプトを注意深くテストすると、対話が許可されたトピックなどから逸脱していないことを確認できます。
 これは興味深いアプローチではありますが、LLM 機能に優れたものや新しいものを提供するものではなく、単に制限するだけであるため、画期的ではありません。ユーザーが LLM と対話できる範囲。それでも、研究者がLLMの幻覚問題や否定的な行動を軽減する代替方法を見つけるまでは、これは実行可能なアプローチである可能性があります。
これは興味深いアプローチではありますが、LLM 機能に優れたものや新しいものを提供するものではなく、単に制限するだけであるため、画期的ではありません。ユーザーが LLM と対話できる範囲。それでも、研究者がLLMの幻覚問題や否定的な行動を軽減する代替方法を見つけるまでは、これは実行可能なアプローチである可能性があります。
ガードレール アプローチは、著者らが「Ahead of AI」の前号で紹介した人気のあるヒューマン フィードバック強化学習トレーニング パラダイムなど、他の調整手法と組み合わせることができます。
一貫性モデル
LLM 以外の興味深いモデルについて話すのは良い試みであり、OpenAI はついにそれらをオープンソース化しました。整合性モデルのコード: https://github.com/openai/consistency_models。
一貫性モデルは、拡散モデルの実現可能かつ効果的な代替手段と考えられています。詳細については、整合性モデルに関する文書を参照してください。
以上が大規模モデルが「オープンソースの季節」の到来を告げ、過去 1 か月間でオープンソース LLM とデータセットを総括の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。