
ホームページ >テクノロジー周辺機器 >AI >因果的推奨技術のマーケティングと説明可能性への応用
因果的推奨技術のマーケティングと説明可能性への応用

- PHPz転載
- 2023-05-18 13:58:061765ブラウズ

1. Uplift ゲイン感度予測
Uplift ゲインに関して、一般的なビジネス上の問題は次のように要約できます。定義された人々のグループに対して、マーケティング担当者は、元のマーケティング アクション T=0 と比較して、新しいマーケティング アクション T=1 がどのくらいの平均収益 (リフト、ATE、平均治療効果) をもたらすことができるかを知りたいと思うでしょう。新しいマーケティング活動が元のマーケティング活動よりも効果的であるかどうかに誰もが注目するでしょう。
保険シナリオでは、マーケティング活動は主に保険の推奨を指します。たとえば、推奨モジュールで公開されるコピーライティングや商品など、プロモーションを目的としています。さまざまなマーケティング戦略. アクションと制約の制約の下で、マーケティングアクションによって最も利益を上げたグループを見つけて、オーディエンスターゲティングを実行します。

まず、より理想的で完璧な仮定を立てます。各ユーザーについて、次のことを知ることができます。彼はマーケティング活動を買います。購入する場合は、式の Di がプラスであり、その値が比較的大きいと考えることができますが、購入せず、マーケティング活動に嫌悪感を抱いている場合は、Di が比較的小さいか、マイナスになる可能性さえあります。これにより、利用者一人ひとりの個別の治療効果が得られる。
# クラウド分割に関しては、上の図に 4 つのマーケティング象限が表示されます。私たちが最も懸念しているのは、間違いなく上部の説得可能なユーザーの群衆です。左の角。公式と組み合わせると、このグループの人々の特徴は、何らかのマーケティング活動があると非常に購入する、つまり Yi > 0 となり、その値が比較的大きいということです。この人々のグループに対してマーケティング活動が行われない場合、それはマイナスになるか、比較的小さくなり、0 に等しくなります。そのような人々のグループの Di は比較的大きくなります。
他の 2 つの象限の人々を見ると、確かに、マーケティングの有無に関係なく、これらの人々が商品を購入するかどうかがわかります。したがって、マーケティング投資のメリットは次のとおりです。このグループの人々ではその割合は比較的低いです。眠っている犬は、マーケティングが何らかの悪影響を与えることを意味します。この 2 つのグループに対してマーケティングを行わないことが最善です。

しかし、ここには反事実的なジレンマもあります。Di はそれほど完璧ではありません。ユーザーが同時に治療に興味があるかどうかを知ることは不可能です。つまり、同時に異なる治療に対する同じユーザーの反応を知ることはできません。
最も一般的な例は、次のとおりです: 薬があるとします。A がそれを服用した後、その薬に対する A の反応が得られます。しかし、A がすでに薬を服用しているため、A が薬を服用しない場合、これは実際には反事実の存在であることを彼らは知りません。
#反事実については、おおよその見積もりを作成しました。 ITE(個人治療効果)推定手法では、2 つの治療に対する反応を実験するユーザーは見つかりませんが、同じ特性を持つユーザー グループを見つけて反応を推定できます。 Xi は同じ特徴空間ではほぼ人間と同等であると仮定できます。

このように、Di の推定値は 3 つの部分に分割されます。 (1 ) T=1 のマーケティング アクションにおける Xi のコンバージョン率;(2)T=0 のマーケティング アクションにおける Xi のコンバージョン率;(3)リフトは差であり、2 つの条件付き確率の差を計算します。ユーザー グループのリフト値が高いほど、このグループの人々が製品を購入する意欲が高いことを意味します。揚力を高くするにはどうすればよいですか?この式では、T=1 のマーケティング活動では Xi のコンバージョン率が増加し、T=0 のマーケティング活動では Xi のコンバージョン率が小さくなります。
 #
#
モデリング方法に関して、上記の式と組み合わせて、いくつかの一般化を行います。
(1) T 変数の数、マーケティング アクションが 1 つだけではなく、n 個のマーケティング アクションがある場合は、多変数 Uplift モデリングが使用されます。それ以外の場合は、単変量 Uplift モデリングが使用されます。
(2) 条件付き確率 P とリフトの予測方法: ① 差分モデリングにより、予測値を推定します。 P 値を計算してからリフト値を求めます。これは間接モデリングです。 ② ラベル変換モデルなどの直接モデリング、またはツリーベース、LR、GBDT、または一部のディープモデルなどの因果フォレストを介して。
#2. ゲイン感度の適用

ゲイン感度は主に、保険商品の推奨、赤い封筒の推奨、コピーライティングの推奨という 3 つの アプリケーションで使用されます。
まずは、Fliggyにおける旅行保険の位置づけをご紹介します。旅行保険は旅行商品のカテゴリーですが、主力商品とのタイアップで登場することが多くなります。たとえば、航空券とホテルを予約する場合、主な購入目的はホテル、航空券、電車のチケットですが、このとき、アプリは保険に加入するかどうかを尋ねます。したがって、保険は付随的なビジネスですが、現在では運送業や宿泊業にとって非常に重要な商業収入源となっています。
この記事の主な範囲はポップアップ ページです。ポップアップ ページは、Fliggy APP がレジを引き下げたときにポップアップするページです。 . このページのみ クリエイティブコピーが表示され、表示できる保険商品は 1 つだけです 複数の種類の商品と保険価格を表示できる以前の詳細ページとは異なります。したがって、このページはユーザーの注意を十分に集中させ、ユーザーの教育やトレーニングのための新しいプロモーションやマーケティング活動を行うこともできます。
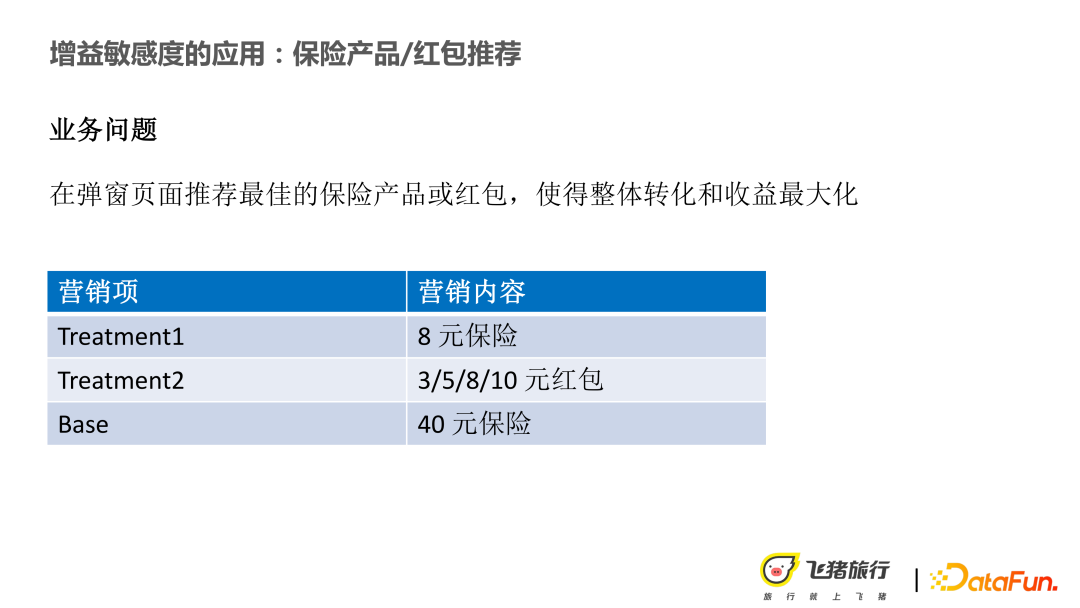
#現在直面しているビジネス上の問題は次のとおりです。ポップアップ ページでは、次のことを行う必要があります。 recommend 最適な保険商品や赤い封筒は、全体的なコンバージョンや収益を最大化することができます。より具体的には、新規顧客を引き付けたり、より高いコンバージョンを達成したりするというビジネス目標を達成することです。ビジネスの収益目標は、収益を減らすことなくコンバージョン率を高めることです。
上記の制約の下では、いくつかのマーケティング項目があります: (1) ユーザーにエントリーレベルの低価格保険を推奨する、(2) 別の治療法、主にいくつかの新しい操作を行うために、いくつかの赤い封筒を推奨します。そしてBaseは保険の元の価格です。

#モデル化する際には、条件付き独立性の仮定といういくつかの仮定があります。治療マーケティング アクションを指します。上昇率の収集をモデル化する場合、サンプルは独立性の仮定に従い、ユーザーのさまざまな特性は互いに独立しています。たとえば、赤い封筒の配布を年齢によって変えることはできません。たとえば、若者には配布を減らし、高齢者には配布を増やす必要があります。これにより、サンプルに偏りが生じます。したがって、提案された解決策は、ユーザーが製品をランダムに公開できるようにすることです。同様に、傾向スコアを計算して、比較のために同種のユーザー グループを取得することもできます。
実験計画の観点から、#、AB 実験: A は元の戦略に従って投資します。これは 40 元の保険となります。または、保険を行うための操作の価格設定、または元のモデルの価格設定である可能性があります。バレル B、低価格の保険の配置。
#ラベル: ユーザーがコンバージョンしたかどうか。 モデル: T/S/X 学習者およびさまざまなタイプのメタ モデル。 サンプル構造: アピールは、ユーザーがこの種の低価格商品により興味があるかどうかを特徴付けることです。価格に対するユーザーの敏感度を特徴付ける十分な機能が必要です。しかし実際には、補助製品のように、比較的強い意図はありません。そのため、ユーザーのこれまでの閲覧履歴や購入履歴からは、ユーザーがどれくらいの保険を気に入っているのか、いくらの保険に加入するのかを知ることは困難です。ユーザーが閲覧した本業やその他のFliggy APPのドメイン内のデータのみを見ることができますが、ユーザーの赤い封筒の使用頻度や赤い封筒の消費の割合も調べます。最初の数日で赤い封筒を送りましたか? それから初めて、Fliggy で変革が実行されました。 
#上記の機能サンプルの構成に基づいて、機能の重要性と解釈可能性も次のようになります。分析を実施した。ツリーベースモデルから、時間、価格変動、および年齢変動の特性に比較的敏感であることがわかります。
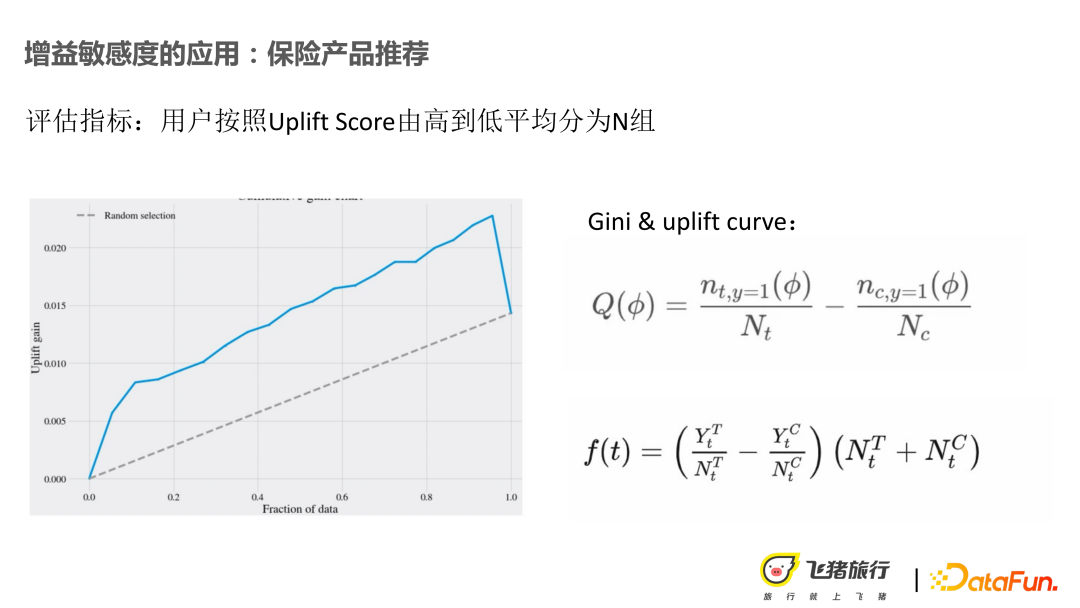

オフラインで利用できる、最もパフォーマンスの高いモデルは LR T-Learner ですが、実際には当初の期待を満たしていません。この問題について考えてみると、おそらく問題は、説明では不十分な保険関連の価格特性のユーザーの構築にあるのかもしれません。ユーザーの性格や保険に対する感受性などのユーザー調査も行っているため、APP ドメイン内の一部のユーザーのポートレート データは、非物理的な商品に対するユーザーの関心を示す可能性があります。しかし、最終的には、配布対象のグループを区別するために依然としてこのスコアに基づいており、オンラインのベース バケットは 5.8% 増加しました。

赤い封筒の推奨事項に関しては、40 元の保険をベースにすることもできます。 3/5/8/10元の保険を発行します。

#上記の目標を分解すると、問題は最終的に、次の式に示すように、ユーザーのコンバージョン率と上昇率の推定に変換されます。上の図の下にあります。
#
最後に、一連の変更を経て、実際に上昇値と非購入確率の計算に戻りました。未購入確率とは、クーポンを発行しない場合のユーザーのコンバージョン率を指し、先ほどのROIを高くしたい場合は、ユーザー層を見つける必要があることを意味し、P0は小さいほど良い、高いほど良いUplift 値が大きいほど良いです。
モデルの最初のバージョンは、半インテリジェントな意思決定モデルです。さまざまなクーポン金額に基づいて計算された上昇値に基づいて、その効果を観察します。閾値は固定されており、各閾値は費用をカバーするために設定されています。

#2 番目のバージョンは、インテリジェントな価格設定モデルです。これは、二重の問題の解決策に基づいています。および制約 クーポンの発行は 1 以下、つまり Xij

# 価格モデルを使用して、元の運用バケットでの赤い封筒の配信と比較すると、 ROI の増分は 1.2 に達する可能性があります。

#コピーライティングでの推奨事項は、以前の製品の推奨事項や赤い封筒の推奨事項のアイデアと似ています。 。ユーザーによっては、コピーライティングのスタイルに合わせて異なる好みを持っていることがわかります。そのため、温かい「安全保証付き」や、リスクについての警告など、コピーライティングを構造化します。特徴量の重要性の観点からは、1980 年代生まれや一部の高齢者には温かみのある文章が効果的である一方、理由ベースの性質を持つコピーライティングは効果的である可能性があります。より効果的です。若い人により適しています。細分化されたグループの特性の重要性と、同時にコピーライティングをパーソナライズする試みの観点からは、相対的に 5% ~ 10% の改善が見られます。 ##3. ベイジアン因果ネットワーク

## 主にトランザクション間の因果関係と有向五輪グラフの構造を表現します。まず、ベイジアンネットワークがなぜ使われるのかを簡単に紹介します。さまざまな推奨コピーライティングの下で、ユーザーがなぜそのコピーライティングに興味を持っているのか、なぜコンバートできるのか、その背後に隠れた変数は何かを知りたいと考えています。したがって、解釈可能なネットワークを構築する場合、頂点は主に観測変数または暗黙の変数であり、エッジは 2 つの頂点間の因果関係を指し、その関係はノード間の条件付き確率を通じて計算できます。ベイジアン ネットワークでは、すべての親ノードの条件下で各頂点の確率値を乗算することで、最終的なネットワーク構造が得られます。
ネットワーク構造には 4 種類のモデル学習問題があります。 
① 構造学習: サンプルに基づいて、より良いベイジアン ネットワークを学習する方法は、上の式に示すように、主に事後的に基づいており、構造の確率値が高いほど、そのネットワークは最も学んだ、素晴らしい。 ② 構造を取得した後、ネットワーク内のノードの条件付き確率値とそのパラメーターを知る方法。 ③ 推論: イベント A が発生したとき、イベント B が発生する確率。
④ 帰属: イベント A が発生したとき、それが発生した原因は何ですか。
4. ポートレートの意思決定パスの構築と説明可能性のアプリケーション

前述のとおり、保険の推奨シナリオは、検索の推奨とは異なります。保険の推奨は補助的なビジネスであり、ユーザーは主観的ではありません。つまり、このモジュールに到達する前に、APP ドメインでの閲覧履歴は、保険の種類やユーザーとはまったく関係がありません。ユーザーが加入している保険 コピーライティングは興味深いものですが、均一な関連性はありません。検索で家族向けのホテルを入力すると、ユーザーは親子ラベル付きのホテルに需要があることがわかります。補助キャンプのシナリオでは、どのような治療アクションが効果的かを知るために複雑な推論プロセスが必要です。たとえば、ネットワークマイニングを通じて、天候が悪いときに遅れた保険の販売が良くなることがわかります。

#ネットワーク内のノードとエッジを次のタイプにモデル化して構築する方法:
① ユーザーノードは、年齢や性別などのユーザーポートレートの基本情報を離散変数として使用し、ノードになります。
② イベント ノード。保険シナリオは他の多くの商品推奨事項よりもイベントに敏感であるため、たとえば、天候や祭りの期間中、ユーザーは遅延保険や特定の属性を持つ特定の保険に対してより敏感になる可能性があります。
③ クリエイティブ ノード (温かみのあるガイド コピーライティング、ダイナミックなデジタル コピーライティングなど) にはさまざまな効果があります。 。
上記の 3 つのノード カテゴリに基づいて、条件付き確率計算を実行して、グラフの構築を完了します。
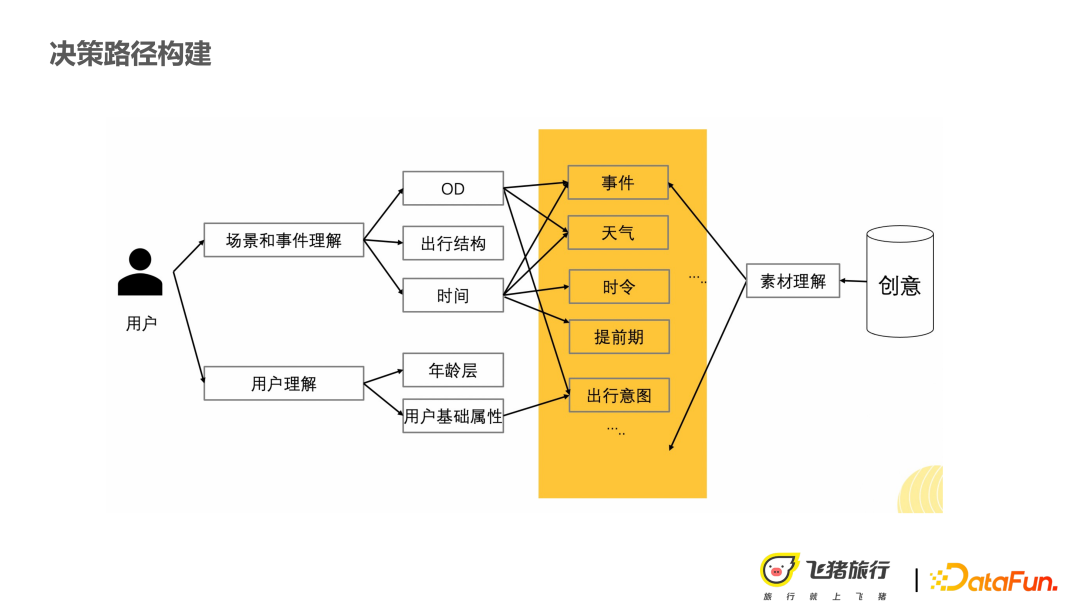
#先ほど述べたユーザーは、シナリオやイベントを構築することで理解と創造的な理解を獲得します。最終的に、すべてのノード タイプは上図に示す構造に統合されます。

ホックマンスコアリング関数を実行する場合、離散または連続の複数の変数が存在する可能性があります。構築されると、それらは離散変数となり、その後の解釈とモデリングが容易になります。各変数がディリクレ分布に準拠していると仮定し、それをサンプルに適用して事後分布を更新し、各ノードの事後値を計算し、ノード間の確率を乗算して、構造のスコアを取得します。これは比較的一般的です。興味があれば、この方法については後ほど詳しく説明します。ネットワーク構造は比較的複雑であるため、ネットワーク全体で貪欲探索手法が使用されます。パラメータの推定は比較的単純で、ノードの条件付き確率テーブルはサンプルに基づいて更新されます。

① 上記の例のように、さまざまな種類の証拠に基づいて、ユーザーがどのような決定を下す可能性があるかを推測します。尤度重み付けまたはループ信念伝播を使用できます。これらはより一般的な方法の一部です。
② 帰属、上の図に示されているのは健康保険です。たとえば、傷害保険が突然売れています。その背後にある理由を本当に知りたいのです。それは、一部の人々が好んで販売しているためです。ユーザーの消費量が多いのは、ユーザーが初心者でほとんど飛行機に乗ったことがない、あるいはユーザーの目的地が高原属性であるため、恐怖から購入に至っていることが考えられます。 最後にまとめると、因果推論は、保険商品の推奨、赤い封筒、コピーライティング マーケティングなどの群集戦略や推奨戦略において大きな役割を果たします。同時に、ベイズ因果関係図の構築や視覚的な説明と組み合わせることで、ビジネスにとってより有意義な意思決定を行うことができ、戦略やコピーライティングを継続的に更新したり、方向性を変更したりすることが可能になります。ベイズ因果関係図は、特徴選択のための新しいアイデアも提供します。 A1: ①オンラインABで効果が上がったので検証あり。 ② 因果モデルをインポートする前に、たとえば、赤いエンベロープ シナリオの最初の戦略はコンバージョン率の推定です。本来コンバージョンに至らないユーザー層を予測し、マーケティング運用を行うことができれば、マーケティングコストを確実にコントロールすることができます。 ③ 制限事項: ユーザーのコンバージョン率は高くない可能性があります。つまり、赤い封筒を渡してもコンバージョンにならない可能性があります。これらは、私たちが以前に遭遇した問題の一部です。 ④ 因果モデル推論をインポートした後、最も明らかな改善はユーザーの柔軟性です。因果推論テクノロジーを使用すると、ユーザーをより明確に理解し、ユーザー グループのシードをより明確に判断できるようになります。 #A2: 最初のステップで多数の機能を選択すると、効果があまり良くない可能性があります。最初の選択では、単一の変数を使用して、その変数とゲインの間に特に強い相関関係があるかどうかを確認してから、それを入力します。もちろん、後ほどツリー モデルで特徴がスコア付けされてからフィルター処理されることがわかります。これが判断の基礎となります。 #A3: ① 差分モデリング。誤差の蓄積につながります。 ② T-learner は主にオフライン評価に合格します。当時私たちはこの問題についてかなり混乱していましたが、要約すると、ゲインを直接特徴づける非常に強力な特徴がなかったためではないかと考えました。したがって、一部の従来のモデルで後で得られる結果はそれほど悪くありません。これは複雑なモデルと単純なモデルの評価にすぎず、単純なモデルの方が堅牢である可能性があります。 ③ AUUC 実は私たちも使っていますが、実はあまり変わりません。 ④ 観測変数はデータ内で観測可能な変数を指しますが、隠れ変数は観測データで説明できる暗黙の変数を指します。 。例えば、人格はもちろんインターネットでは活用されていません。 A4: まだ試していません。 #A5: 因果推論は昨年の課題の 1 つでしたが、今年は主にクリエイティブなコピーライティングの推奨が課題です。 5. Q&A セッション
Q1: Fliggy Insurance Marketing が採用した Uplift モデルは導入後に検証されましたか?因果推論モデルを導入する前に、飛秀保険はマーケティングにどのようなテクノロジーを使用していましたか?制限は何ですか?この因果推論モデルをインポートした後の最も明らかな改善は何ですか?
#Q2: 因果推論モデルの機能はどのように選択すればよいですか?シナリオで最も重要な機能はどれですか?
#Q3: 差分モデリング中にデータに選択バイアスが現れますか? T-Learner ではこの種の問題に対処できないのでしょうか?評価時に AUUC が使用されないのはなぜですか?ベイジアン因果ネットワークの潜在変数は何ですか?
#Q4: 実際に、マッチング手法に続いて回帰手法を使用してみたことがありますか?もしそうなら、その効果は何ですか?
Q5: 今後の探求の方向性は何ですか?例えば、私たちは現在、保険の推奨の方向性を模索しています。
以上が因果的推奨技術のマーケティングと説明可能性への応用の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。