



この記事では、慣性モーション キャプチャの「目」を開こうとしています。追加の携帯電話カメラを装着することで、私たちのアルゴリズムは「視覚」を獲得します。人の動きを捉えながら環境情報をセンシングすることで、人体の正確な位置決めを実現します。この研究は清華大学のXu Feng氏のチームによるもので、コンピュータグラフィックス分野のトップ国際会議であるSIGGRAPH2023に採択されました。

- 紙のアドレス: https://arxiv.org/abs/2305.01599
- #プロジェクトのホームページ: https://xinyu-yi.github.io/EgoLocate/オープンソース コード: https:/ /github.com/Xinyu-Yi/EgoLocate
- はじめに
これに基づいて、清華大学の Xu Feng のチームは、6 つの慣性センサー (IMU) と 1 つの単眼カラー カメラのみを使用した同時リアルタイム ヒューマン モーション キャプチャを提案しました。測位および環境マッピング技術 (図 1 を参照)。慣性モーション キャプチャ (mocap) テクノロジーは人体の動き信号などの「内部」情報を探索しますが、同時位置特定およびマッピング (SLAM) テクノロジーは主に「外部」情報、つまりカメラでキャプチャされた環境に依存します。前者は安定性は良いが、外部に正確な基準がないため、長期の移動中に全地球位置ドリフトが蓄積され、後者はシーン内の全地球位置を高精度に推定できるが、環境情報が信頼できない場合(例えば、テクスチャがない場合、またはオクルージョンがある場合)、トラッキングを失いやすくなります。
# したがって、この記事では、これら 2 つの相補的なテクノロジ (モーション キャプチャと SLAM) を効果的に組み合わせます。堅牢かつ正確な人間の位置決めと地図の再構築は、人間の動作事前分布と複数の主要なアルゴリズムでの視覚追跡の融合によって実現されます。
#図 1 この記事では、ヒューマン モーション キャプチャと環境マッピングの同時技術を提案します
具体的には、この研究では、人の手足、頭、背中に 6 台の IMU を装着し、頭部に単眼カラーカメラを固定して外側から撮影しました。このデザインは実際の人間の行動からインスピレーションを得ています。人間は新しい環境にいるとき、目を通して環境を観察し、自分の位置を決定し、それによってシーン内での動きを計画します。 
私たちのシステムでは、単眼カメラが人間の目の役割を果たし、リアルタイムのシーン再構成とこの技術の自己位置決めのための視覚信号を提供し、IMU がカメラの動きを測定します。人間の手足と頭スポーツ。このセットアップは既存の VR 機器と互換性があり、VR ヘッドセットのカメラと追加の IMU を使用して、安定したドリフトのない全身モーション キャプチャと環境認識を実行できます。 システム全体は、わずか 6 つの IMU と 1 台のカメラに基づいて、人間のモーション キャプチャと環境の疎点再構築を同時に実現し、実行速度は CPU で 60fps に達し、精度は両方の最高を上回りました。フィールド、先進技術。 このシステムのリアルタイムの例を図 2 と 3 に示します。
図 2 70 メートルの複雑な動きにおいて、このシステムは人体の位置を正確に追跡し、明らかな位置ドリフトなしに人体の動きを捕捉します。

図 3 人の動きとまばらなシーンを同時に再構築するこのシステムのリアルタイムの例ポイント。
#メソッドの紹介
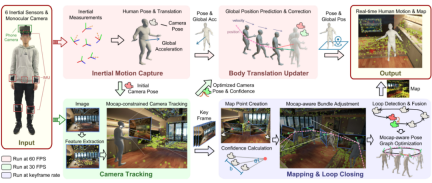
##図 4 全体的なプロセス方法
#システムのタスクは、人間の動きと 3 次元シーンのまばらな点群を、人間の方向と加速度の測定からリアルタイムで再構築することです。 6 つの IMU センサーとカメラで撮影したカラー写真を利用して、シーン内の人の位置を特定します。私たちは、スパース慣性モーション キャプチャと SLAM テクノロジーの相補的な利点を最大限に活用するために、深く結合されたフレームワークを設計します。このフレームワークでは、人間のモーション事前分布が SLAM の複数の主要コンポーネントと結合され、SLAM の測位結果も人間のモーション キャプチャにフィードバックされます。図 4 に示すように、機能に応じてシステムを 4 つのモジュールに分割します。慣性モーション キャプチャ モジュール (Inertial Motion Capture)、カメラ トラッキング モジュール (Camera Tracking)、およびマッピングです。そしてループ検出モジュール (Mapping & Loop Closing) と人間の動作更新モジュール (Body Translation Updater)。以下に各モジュールを紹介します。 慣性モーション キャプチャ
慣性モーション キャプチャ モジュールは、6 つの IMU 測定値から人間の姿勢と動作を推定します。このモジュールの設計は、以前の PIP [1] の作業に基づいていますが、この作業では、シーンが平坦な地面であることを前提とせず、3D 空間で人間の自由な動きをキャプチャすることを考慮しています。この目的のために、この論文では PIP 最適化アルゴリズムに適応的な変更を加えます。
具体的には、このモジュールはまず、多段リカレントニューラルネットワークを通じて、IMUの計測値から人間の関節の回転、速度、足と地面の接地確率を予測します。 PIP が提案するデュアル PD コントローラは、人間の関節の最適制御角加速度
と線形加速度  を解決するために使用されます。続いて、本モジュールは、接触拘束条件
を解決するために使用されます。続いて、本モジュールは、接触拘束条件 C##を満たしながら、PDコントローラから与えられる加速度を達成できるように、人体の姿勢加速度
C##を満たしながら、PDコントローラから与えられる加速度を達成できるように、人体の姿勢加速度 を最適化します。 #:
を最適化します。 #:
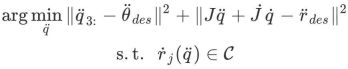
は結合ヤコビ行列
です。 は、地面と接触する足の線形速度であり、制約 C では、地面と接触する足の速度が小さい必要があります (滑りは発生しません)。この二次計画問題を解くには、PIP[1] を参照してください。姿勢加速度積分により人体の姿勢と動作を取得した後、後続のモジュールのために人体にバインドされたカメラの姿勢を取得できます。
では、地面と接触する足の速度が小さい必要があります (滑りは発生しません)。この二次計画問題を解くには、PIP[1] を参照してください。姿勢加速度積分により人体の姿勢と動作を取得した後、後続のモジュールのために人体にバインドされたカメラの姿勢を取得できます。
カメラ追跡
カメラ追跡モジュールは、慣性モーション キャプチャ モジュールによって与えられた初期カメラ ポーズとカメラによってキャプチャされたカラー画像を入力として受け取り、その画像情報を使用してカメラを最適化します。ポーズを設定して位置のドリフトを解消します。具体的には、このモジュールは ORB-SLAM3 [2] に基づいて設計されており、まず画像の ORB 特徴点を抽出し、特徴類似度を使用して再構成されたスパース マップ点 (後述) との特徴マッチングを実行して、一致する 2D-3D 点を取得します。次に、再投影誤差を最適化することでカメラのポーズを最適化します。再投影エラーのみを最適化すると誤った一致の影響を受ける可能性があり、カメラ ポーズの最適化結果が低下する可能性があることに注意してください。したがって、この記事では、人間の動きの事前情報をカメラ追跡の最適化に統合し、慣性モーション キャプチャの結果を制約として使用し、再投影エラーの最適化プロセスを制限し、誤った特徴点とマップの点一致を迅速に発見して排除します。 # ####。
マップ ポイントのワールド座標を
として、一致する 2D 画像特徴点のピクセル座標を  # として覚えてください。 ## は、一致するすべての関係を表します。
# として覚えてください。 ## は、一致するすべての関係を表します。 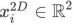

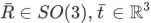 を使用して最適化前の初期カメラ ポーズを表すと、このモジュールがカメラ ポーズ
を使用して最適化前の初期カメラ ポーズを表すと、このモジュールがカメラ ポーズ
:## を最適化します。
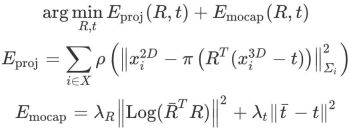
は堅牢な Huber カーネル関数です。  3 次元回転を 3 次元ベクトル空間にマッピングします。
3 次元回転を 3 次元ベクトル空間にマッピングします。 は透視投影操作、
は透視投影操作、 は制御係数です。モーション キャプチャの回転および移動アイテム。この最適化は 3 回実行され、毎回、再投影誤差に基づいて 2D-3D の一致が正しいか誤っているかに分類され、次の最適化では正しい一致のみが使用され、誤った一致は削除されます。モーション キャプチャの制約によって提供される強力な事前知識により、このアルゴリズムは正しい一致と不正確な一致をより適切に区別できるため、カメラの追跡精度が向上します。カメラ ポーズを解決した後、このモジュールは正しく一致したマップ ポイントのペアの数を抽出し、それをカメラ ポーズの信頼性として使用します。
は制御係数です。モーション キャプチャの回転および移動アイテム。この最適化は 3 回実行され、毎回、再投影誤差に基づいて 2D-3D の一致が正しいか誤っているかに分類され、次の最適化では正しい一致のみが使用され、誤った一致は削除されます。モーション キャプチャの制約によって提供される強力な事前知識により、このアルゴリズムは正しい一致と不正確な一致をより適切に区別できるため、カメラの追跡精度が向上します。カメラ ポーズを解決した後、このモジュールは正しく一致したマップ ポイントのペアの数を抽出し、それをカメラ ポーズの信頼性として使用します。  マッピングとループ クロージャの検出
マッピングとループ クロージャの検出
# を使用することで、結果の精度が向上します。人間の動きで閉ループが発生すると、 モーション キャプチャを利用したポーズ グラフの最適化が実行され、閉ループ エラーが修正されます。最後に、最適化されたスパース マップ ポイントの位置とキー フレーム ポーズが取得され、これらは次のフレームでアルゴリズムを実行するために使用されます。
具体的には、このモジュールはまず、観測状況に基づいてマップ ポイントの信頼度を計算します。これは、その後の BA 最適化に使用されます。以下の図 5 に示すように、このモジュールは、観察されたマップ ポイントのキー フレームの位置に従って、キー フレームのベースラインの長さ bi と観察角度 θi を計算し、マップ ポイント i## の信頼度を決定します。 ##、ここで k は制御係数です。 
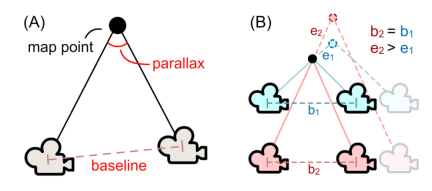
#図 5 (a) マップ ポイントの信頼度の計算。 (b) 同じ基線長 b1=b2 の場合、観察角度 (青) が大きいほど、カメラ ポーズの摂動によく耐えることができ、マップ ポイントの位置誤差 (e1
note
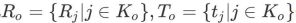 は、最適化する必要があるキーフレームの方向と 3 次元の位置を示します。
は、最適化する必要があるキーフレームの方向と 3 次元の位置を示します。
## はマップ ポイントの位置を表します。次に、モーション キャプチャ コンストレイントのビーム調整の最適化は次のように定義されます。 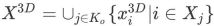
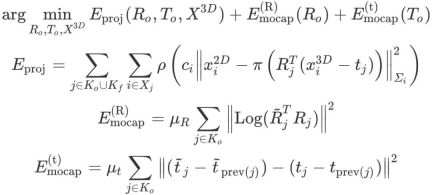
は、キー フレーム j の前のキー フレーム 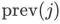
## を表します。
# は、モーション キャプチャ コンストレイント項目の係数です。この最適化では、マップ ポイントの再投影誤差が小さく、各キー フレームの回転と相対位置がモーション キャプチャの結果に近い必要があります。マップ ポイントの信頼度ci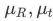 がモーション キャプチャを動的に決定します。制約とマップ ポイント再投影アイテム間の相対的な重みの関係:
がモーション キャプチャを動的に決定します。制約とマップ ポイント再投影アイテム間の相対的な重みの関係:
完全に再構築されていないエリアの場合、システムはモーション キャプチャの結果を信じる可能性が高くなります。逆に、エリアが繰り返し観察されると、システムは視覚追跡をより信頼するようになります。 最適化された因子グラフを以下の図 6 に示します。
#図 6モーション キャプチャの制約に対するビーム調整方法によるファクター グラフ表現の最適化。 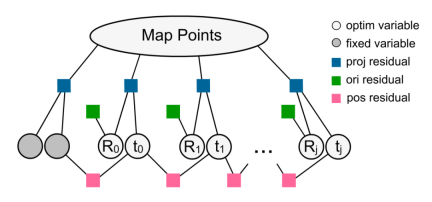
#軌道閉ループが検出されると、システムは閉ループ最適化を実行します。 ORB-SLAM3[2] に基づいて、ポーズ グラフの頂点のセットは F、エッジのセットは C です。次に、モーション キャプチャ制約のポーズ グラフの最適化は次のように定義されます:
このうち、 はキーフレーム j のポーズ、
はキーフレーム j のポーズ、 はポーズグラフが作成される前のキーフレーム i と j の間です。最適化された の相対ポーズ、
はポーズグラフが作成される前のキーフレーム i と j の間です。最適化された の相対ポーズ、 はモーション キャプチャによって取得されたカメラ ポーズの初期値です。
はモーション キャプチャによって取得されたカメラ ポーズの初期値です。 はポーズを 6 次元ベクトル空間にマッピングします、
はポーズを 6 次元ベクトル空間にマッピングします、 は、モーション キャプチャ コンストレイント項目の相対係数です。 この最適化は、事前のモーション キャプチャによってガイドされ、閉ループ エラーを各キー フレームに分散します。
は、モーション キャプチャ コンストレイント項目の相対係数です。 この最適化は、事前のモーション キャプチャによってガイドされ、閉ループ エラーを各キー フレームに分散します。
ヒューマン モーション アップデート
ヒューマン モーション アップデート モジュールは、最適化されたカメラ ポーズとカメラ追跡モジュールの信頼性を使用して、モーション キャプチャ モジュールによって与えられる人体の全体的な位置。このモジュールは、カルマン フィルターの予測補正アルゴリズムを使用して実装されています。その中で、モーション キャプチャ モジュールは、人体の全体的な位置 (事前分布) を予測するために使用できる人体の動きの加速度の一定の変化を提供し、カメラ追跡モジュールは、カメラの位置の観察と信頼性を提供します。人体の全体的な位置 (事後分布) を修正します。)このうち、カメラ位置観測の共分散行列  は、次の対角行列として、一致するマップ点の数によって近似的に計算されます。
は、次の対角行列として、一致するマップ点の数によって近似的に計算されます。
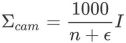
は、除数が 0 になることを避けるための 10 進数です。つまり、カメラ追跡で一致したマップ ポイントの数が多いほど、カメラの姿勢の観測値の分散は小さくなります。カルマン フィルター アルゴリズムは、人体の全体的な位置を最終的に予測するために使用されます。  メソッドの紹介と式の導出の詳細については、論文の原文と付録を参照してください。
メソッドの紹介と式の導出の詳細については、論文の原文と付録を参照してください。
Mocap との比較
この方法は主に、スパース慣性モーション キャプチャ (Mocap) におけるグローバル位置ドリフトの問題を解決します。テストが選択されている場合、指標は人体のグローバル位置誤差です。 2 つの公開データ セット (TotalCapture および HPS) における SOTA モーション キャプチャ メソッド TransPose[3]、TIP[4]、および PIP[1] との定量的テスト結果の比較を以下の表 1 に示します。以下の図 7 と図 8 を参照してください。この記事の方法は、全地球測位精度の点で以前の慣性モーション キャプチャ方法を大幅に上回っており (TotalCapture と HPS でそれぞれ 41% と 38% 向上)、軌道は真の値との類似性が最も高いことがわかります。

#
図 7 慣性モーション キャプチャ作業によるグローバル位置誤差の定性的比較。真の値は緑色で表示され、さまざまな手法の予測結果は青色で表示されます。各画像の隅に人体の移動軌跡と現在位置(オレンジ色の点)が表示されます。
図 8 慣性モーション キャプチャ作業によるグローバル位置誤差の定性的比較 (ビデオ)。真の値は緑色で示され、この文書のメソッドは白色で示され、以前の研究のメソッドは他の異なる色を使用しています (凡例を参照)。
SLAM との比較
この記事では、SOTA SLAM 作品 ORB-SLAM3[2] を測位精度と地図再構成精度の 2 つの観点から比較します。単眼バージョンと単眼慣性バージョンを比較しました。位置決め精度の定量的な比較結果を表2に示します。地図再構成精度の定量的な比較結果を表 3 に、定性的な比較結果を図 9 に示します。 SLAM と比較して、この論文の方法はシステムの堅牢性、測位精度、およびマップ再構成精度を大幅に向上させていることがわかります。
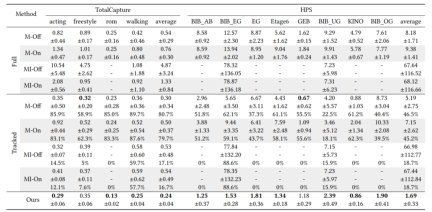
#表 2 SLAM 作業による位置決め誤差の定量的比較 (誤差単位: メートル)。 M/MI はそれぞれ ORB-SLAM3 の単眼/単眼慣性バージョンを表し、On/Off は SLAM のリアルタイムおよびオフラインの結果を表します。 SLAM は追跡を失うことが多いため、SLAM の完全なシーケンス (フル) と正常に追跡されたフレーム (追跡) の平均測位誤差をそれぞれ報告します。この方法では追跡損失がないため、完全なシーケンスの結果を報告します。各方法を 9 回テストし、中央値と標準偏差を報告しました。正常に追跡されたフレームのエラーについては、成功の割合も追加で報告します。メソッドが複数回失敗した場合、失敗としてマークされます (「-」で示されます)。

表 3 マップ再構成エラーと SLAM 作業の定量的比較 (誤差単位:メートル)。 M/MI はそれぞれ、ORB-SLAM3 の単眼/単眼慣性バージョンを表します。 3 つの異なるシーン (オフィス、屋外、工場) について、シーンの表面ジオメトリから再構築されたすべての 3D マップ ポイントの平均誤差をテストします。各方法を 9 回テストし、中央値と標準偏差を報告しました。メソッドが複数回失敗した場合、失敗としてマークされます (「-」で示されます)。

図 9 マップ再構成エラーと SLAM 作業の定性的比較。さまざまな方法で再構成されたシーン ポイントを、各ポイントのエラーを色で示して示します。 # さらに、このシステムは人間の動作を事前に導入することにより、視覚追跡損失に対する堅牢性を大幅に向上させます。視覚的特徴が乏しい場合、このシステムは人間の事前動作を利用して、他の SLAM システムのように追跡やリセット、新しいマップの作成を失うことなく追跡を継続できます。以下の図 10 に示すように。

図 10 オクルージョンの堅牢性と SLAM 作業の比較。グランド トゥルース軌道リファレンスは右上隅に表示されます。 SLAM 初期化のランダム性により、グローバル座標系とタイムスタンプは完全には一致しません。 #その他の実験結果については、論文の原文、プロジェクトのホームページ、および論文のビデオを参照してください。
概要
この記事では、人間のモーション キャプチャ、位置決め、マッピングをリアルタイムで同時に実行するための、慣性モーキャップと SLAM の最初の組み合わせを提案します。このシステムは十分に軽量であるため、6 つの慣性測定ユニットと携帯電話のカメラを含む、人体に装着するセンサーのまばらなセットのみが必要です。オンライン トラッキングでは、モーキャップと SLAM が制約付き最適化とカルマン フィルター技術によって融合され、より正確な人間の位置決めが実現されます。バックエンドの最適化では、SLAM のビーム調整の最適化と閉ループの最適化に人間の動きを統合することで、位置決めとマッピングのエラーがさらに削減されます。
この研究は、人体の知覚と環境の知覚を統合することを目的としています。この研究は主に位置特定の側面に焦点を当てていますが、この研究は関節モーション キャプチャと詳細な環境認識と再構築に向けた第一歩となると考えています。
以上が6つの慣性センサーと携帯電話で人体のモーションキャプチャ、測位、環境再構築を実現の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIゲーム開発は、激動の夢想家ポータルでエージェントの時代に入りますMay 02, 2025 am 11:17 AM
AIゲーム開発は、激動の夢想家ポータルでエージェントの時代に入りますMay 02, 2025 am 11:17 AM激動ゲーム:AIエージェントとのゲーム開発に革命をもたらします BlizzardやObsidianなどの業界の巨人の退役軍人で構成されるゲーム開発スタジオであるUpheavalは、革新的なAIを搭載したPlatforでゲームの作成に革命をもたらす態勢を整えています。
 UberはあなたのRobotaxiショップになりたいと思っています、プロバイダーはそれらを許可しますか?May 02, 2025 am 11:16 AM
UberはあなたのRobotaxiショップになりたいと思っています、プロバイダーはそれらを許可しますか?May 02, 2025 am 11:16 AMUberのRobotaxi戦略:自動運転車用の乗車エコシステム 最近のCurbivore Conferenceで、UberのRichard Willderは、Robotaxiプロバイダーの乗車プラットフォームになるための戦略を発表しました。 で支配的な位置を活用します
 ビデオゲームをプレイするAIエージェントは、将来のロボットを変革しますMay 02, 2025 am 11:15 AM
ビデオゲームをプレイするAIエージェントは、将来のロボットを変革しますMay 02, 2025 am 11:15 AMビデオゲームは、特に自律的なエージェントと現実世界のロボットの開発において、最先端のAI研究のための非常に貴重なテストの根拠であることが証明されています。 a
 スタートアップインダストリアルコンプレックス、VC 3.0、およびジェームズクーリエのマニフェストMay 02, 2025 am 11:14 AM
スタートアップインダストリアルコンプレックス、VC 3.0、およびジェームズクーリエのマニフェストMay 02, 2025 am 11:14 AM進化するベンチャーキャピタルの景観の影響は、メディア、財務報告、日常の会話で明らかです。 ただし、投資家、スタートアップ、資金に対する特定の結果はしばしば見落とされています。 ベンチャーキャピタル3.0:パラダイム
 AdobeはAdobe Max London 2025でクリエイティブクラウドとホタルを更新しますMay 02, 2025 am 11:13 AM
AdobeはAdobe Max London 2025でクリエイティブクラウドとホタルを更新しますMay 02, 2025 am 11:13 AMAdobe Max London 2025は、アクセシビリティと生成AIへの戦略的シフトを反映して、Creative Cloud and Fireflyに大幅な更新を提供しました。 この分析には、イベント以前のブリーフィングからの洞察がAdobeのリーダーシップを取り入れています。 (注:ADOB
 すべてのメタがラマコンで発表しましたMay 02, 2025 am 11:12 AM
すべてのメタがラマコンで発表しましたMay 02, 2025 am 11:12 AMMetaのLlamaconアナウンスは、Openaiのような閉じたAIシステムと直接競合するように設計された包括的なAI戦略を紹介し、同時にオープンソースモデルの新しい収益ストリームを作成します。 この多面的なアプローチはBOをターゲットにします
 AIは単なる通常のテクノロジーに過ぎないという提案に関する醸造論争May 02, 2025 am 11:10 AM
AIは単なる通常のテクノロジーに過ぎないという提案に関する醸造論争May 02, 2025 am 11:10 AMこの結論に関して、人工知能の分野には深刻な違いがあります。 「皇帝の新しい服」を暴露する時が来たと主張する人もいれば、人工知能は普通の技術であるという考えに強く反対する人もいます。 それについて議論しましょう。 この革新的なAIブレークスルーの分析は、AIの分野での最新の進歩をカバーする私の進行中のForbesコラムの一部です。 一般的な技術としての人工知能 第一に、この重要な議論の基礎を築くためには、いくつかの基本的な知識が必要です。 現在、人工知能をさらに発展させることに専念する大量の研究があります。全体的な目標は、人工的な一般情報(AGI)を達成し、さらには可能な人工スーパーインテリジェンス(AS)を達成することです
 モデル市民、なぜAI価値が次のビジネスヤードスティックであるのかMay 02, 2025 am 11:09 AM
モデル市民、なぜAI価値が次のビジネスヤードスティックであるのかMay 02, 2025 am 11:09 AM企業のAIモデルの有効性は、現在、重要なパフォーマンス指標になっています。 AIブーム以来、生成AIは、誕生日の招待状の作成からソフトウェアコードの作成まで、すべてに使用されてきました。 これにより、言語modが急増しました


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

WebStorm Mac版
便利なJavaScript開発ツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター
ホットトピック
 7907
7907 15165214141152130325124829
15165214141152130325124829