
ホームページ >バックエンド開発 >Python チュートリアル >Pythonでnp.random.permutation関数を使用する方法
Pythonでnp.random.permutation関数を使用する方法

- PHPz転載
- 2023-05-17 13:43:062028ブラウズ
1: 関数の紹介
np.random.permutation() 一般的に言えば、これはランダムな置換関数です。へ 入力データはランダムに配置されます 公式ドキュメントには、この関数は 1 次元のデータのみをランダムに配置でき、多次元データの場合は 1 次元のデータのみをランダムに配置できると記載されています。
要するに: np.random.permutation 関数の機能は、指定されたリストに従ってスクランブルされたランダム リストを生成することです
データを処理するときデータ セットを設定する場合、通常、この関数を使用してデータ セットの内部順序をシャッフルし、ラベル シーケンスを同じ順序でシャッフルします。
2: 例
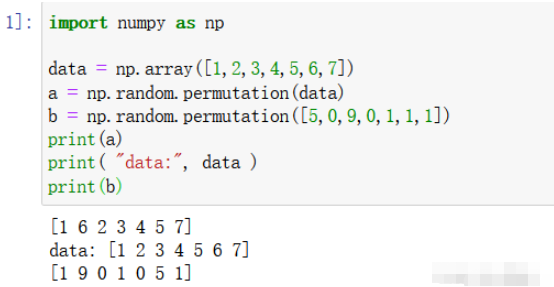
2.1 配列またはリストの数値を直接処理する
import numpy as np data = np.array([1,2,3,4,5,6,7]) a = np.random.permutation(data) b = np.random.permutation([5,0,9,0,1,1,1]) print(a) print( "data:", data ) print(b)
2.2 間接的な処理: 元のデータを変更しません (配列インデックス処理)
label = np.array([1,2,3,4,5,6,7])
a = np.random.permutation(np.arange(len(label)))
print("Label[a] :" ,label[a] )
##補足: 一般に、N 次元配列にのみ使用でき、整数スカラー配列をスカラー インデックスにのみ変換できます
why?label1[a1] label1 はリスト、a1 はリストの添え字をランダムに並べたものですが、!リスト構造にはスカラー インデックス label1[a1] がありません。エラー
label1=[1,2,3,4,5,6,7]
print(len(label1))
a1 = np.random.permutation(np.arange(len(label1)))#有结果
print(a1)
print("Label1[a1] :" ,label1[a1] )#这列表结构没有标量索引 所以会报错

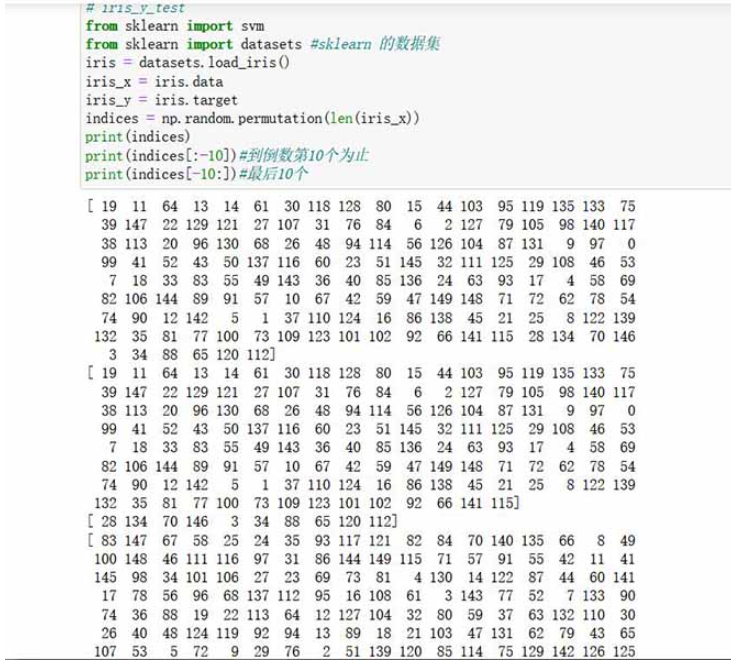
from sklearn import svm
from sklearn import datasets #sklearn 的数据集
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
indices = np.random.permutation(len(iris_x))
#此时 打乱的是数组的下标的排序
print(indices)
print(indices[:-10])#到倒数第10个为止
print(indices[-10:])#最后10个
# print(type(iris_x)) <class 'numpy.ndarray'>
#9:1分类
#iris_x_train = iris_x[indices[:-10]]#使用的数组打乱后的下标
#iris_y_train = iris_y[indices[:-10]]
#iris_x_test= iris_x[indices[-10:]]
#iris_y_test= iris_y[indices[-10:]]
配列の添字はスカラー インデックスの再配布です: 添字は 0
 から始まります
から始まります
以上がPythonでnp.random.permutation関数を使用する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。
声明:
この記事はyisu.comで複製されています。侵害がある場合は、admin@php.cn までご連絡ください。