
ホームページ >テクノロジー周辺機器 >AI >プログラマーの未来は「疑似コード」にあり! Nature コラム: ChatGPT を使用して科学研究プログラミングを加速する 3 つの方法
プログラマーの未来は「疑似コード」にあり! Nature コラム: ChatGPT を使用して科学研究プログラミングを加速する 3 つの方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-16 22:19:041372ブラウズ
ChatGPT、Bard などの生成型人工知能ツールに基づくチャットボットの出現と、学術研究での AI ツールの使用方法は大きな論争を引き起こしましたが、同時に、AI によって生成されたコードはさまざまな分野で使用されています。科学 研究の価値は無視されます。
ChatGPT で生成されたテキストによって引き起こされる盗作問題と比較すると、AI を使用してコードをコピーすることは明らかに議論の余地がありません。オープン サイエンスは「コード共有」と「コードの再利用」さえ奨励しています。ソースの追跡も容易で、例えばPythonのimportを使って依存パッケージをインポートするのが参考になるなど便利です。
最近、Nature にレビュー記事が掲載されました。著者チームは、ブレインストーミングや複雑なタスクの分解など、科学プログラミングの分野における ChatGPT の 3 つの潜在的な機能について議論しました。単純だが時間のかかるタスクを処理します。

記事リンク: https://www.nature.com/articles/s41559-023-02063 -3
研究者らは、ChatGPT を使用して自然言語をコンピューター可読コードに変換することで、科学コーディングを強化する生成 AI の機能と限界を調査しました。
実験の例では、生態学、進化、その他の分野に関連する可能性のある一般的なタスクを主に検討しました。研究者らは、コーディング タスクの 80% ~ 90% が次の方法で完了できることを発見しました。チャットGPT 。
ChatGPT は、タスクがクエリとして正確なヒントを使用して、小さく管理しやすいコードの塊に分割されている場合、非常に有用なコードを生成できます。
Google の Bard で同じ実験を行うと、通常は同様の結果が得られますが、コードに多くのエラーが含まれるため、この記事では主に ChatGPT を実験に使用することに注意してください。
筆頭著者の Cory Merow は定量生態学者であり、その主な研究方向は、環境変化に対する個体群やコミュニティの反応を予測するメカニズム モデルを構築することです。最良のデータセットであっても、地球規模の変化に対する反応を予測するには不完全であるため、データソースを組み合わせてデータセットを探索し、生物学的システムで起こり得る変化について洞察を得るツールを開発する必要があります。
ChatGPT は科学的コーディングに役立ちますChatGPT は回帰モデル GPT-3 に基づいており、膨大な Web ページ、書籍、その他のテキストに対して、検索を行わずにフィッティング トレーニングを実行します。生成される。
つまり、ChatGPT は内挿 (トレーニング データに類似したテキストの予測) には優れていますが、外挿 (トレーニング サンプルとは異なる新しいテキストの予測) には向いていません。
トレーニング セットの巨大なサイズは利点であり、GPT-3 が多数の言語パターンを認識していることを意味し、補間して、次のような応答を生成する可能性を高めます。人間にとって役に立つ。
しかし、コード生成タスクの場合、GPT-3 はプログラミング方法を知りません。コードがどのようなものであるか、次にどの単語が出現する可能性が最も高いかを知っているだけです。自動補完に似ています。確率モデルに基づいて次のコード ブロック (チャンク) を予測します。通常、チャンクは単語 (ワード) よりも小さいです。トークン
と呼ぶこともできます。 #正しいトークンが生成される確率 すべてのトークンの確率の積に基づいて、予測されるトークンの数が増加したり、選択されたトークンの確実性が低下したりすると、タスクの難易度が上がり、正しいトークンを取得する確率が低くなります。したがって、正しいトークンの確率を高めたい場合は、生成タスクの長さを短縮するか、より具体的な指示を提供する必要があります。
最後に、研究者は、ChatGPT によって生成されたテキストの一部はコードのように見えますが、実行できない可能性があるため、コーディング プロセス中に注意深い観察とデバッグが必要であることを思い出させます。
ブレーンストーミング ツール
ChatGPT は優れた情報取得に役立ちますたとえば、生態学の分野では、植物の形質、種の分布域、気象データを同時に取得できます。ChatGPT によって提供されるデータの一部は正しくありませんが、これらのエラーは、ChatGPT が提供するリンクを通じてすぐに修正できます。 ただし、ChatGPT は、Web サイトからデータをダウンロードするためのクローラーを作成できません。これは、R 言語パッケージと基盤となるアプリケーション プログラム インターフェイス (R が Web サイトにアクセスするためのプロトコルなど) が原因である可能性があります。結局のところ、ChatGPT 訓練データは 2021 年に構築されました。 ChatGPT は、特定の問題が発生したときにさまざまな統計手法を提案し、その後の質問では、ユーザーの仮定に基づいて詳細なガイダンスを生成し、初期コードを提供します。 ただし、合成プロセスはアイデアの提案と伝達にのみ適しており、従来のデータ ソース (論文など) による事実確認が依然として必要です。 一部の Web サイトでは、ChatGPT には書籍の要約を作成する機能があると主張されていますが、研究者のテスト結果から判断すると、この要約の総合的な結果は完全に正確ではありません。おそらくテストに使用された書籍が GPT-3 トレーニング セットに含まれていないため、間違っています。 #難しいタスクにはより多くのデバッグが必要です ChatGPT は非常に便利ですテンプレート コードの生成が得意で、特定の命令に従って少数の関数を含む短いスクリプト コードを提供します。 たとえば、以下の例では、研究者は ChatGPT に、一般的に使用される 4 つの関数の入力と出力をつなぎ合わせるように依頼しました。シミュレートされたデータに対してこの関数を使用するサンプル コードを提供します。 ChatGPT によって生成された結果はほぼ完璧であることがわかります。コードのデバッグには数分しかかかりませんでした。ただし、プロンプトでクエリを非常に具体的に説明する必要があります。関数の名前付けと使用方法の提供を含みます。 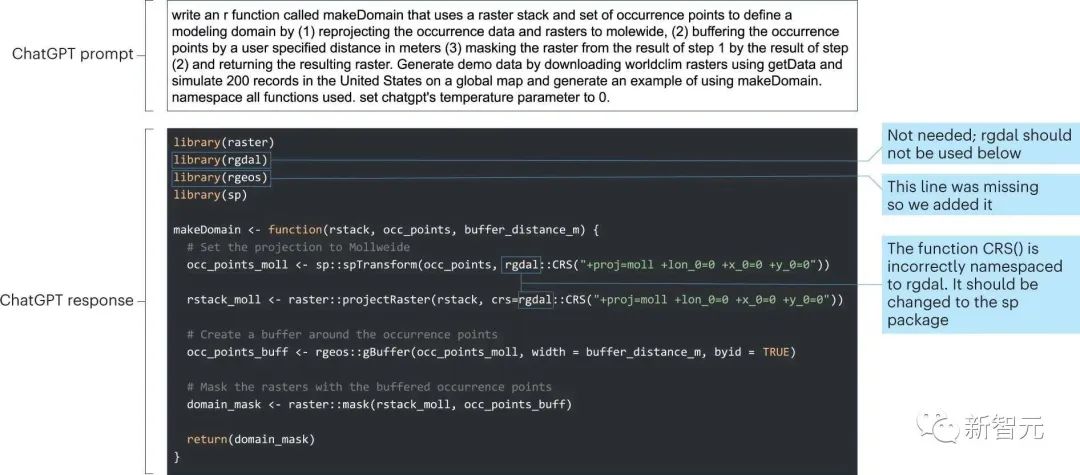
研究者らは、成功の鍵は次のとおりであることを発見しました。
1.複雑なタスクを複数のサブタスクに分解し、各サブタスクの完了に必要な手順は数ステップだけであることが望ましいため、結局のところ、ChatGPT によって生成されたコードは確率的テキスト予測モデルの結果に基づいています。
2. ChatGPT は、外挿ではなく内挿のみを行うため、既存の関数を使用する場合に最高のパフォーマンスを発揮します。
たとえば、正規表現 (regex) を使用してテキストから情報を抽出するコードは、多くの開発者にとって非常に困難ですが、オンラインで多数の情報を提供する通常の正規表現 Web サイトがすでに存在するためです。例 、および ChatGPT の例に出現する可能性があるため、正規表現を記述する ChatGPT のパフォーマンスは依然として良好です。
3. 学者による ChatGPT に対する最大の批判の 1 つは、情報ソースの透明性の欠如です。
コード生成タスクの場合、「名前空間」を指定することによって、つまり関数を使用するときにパッケージ名を明示的に呼び出すことによって、ある程度の透過性を実現できます。
ただし、ChatGPT は個人の公開コードを引用せずに直接コピーする場合があり、研究者は正しいコードの帰属を確認する責任を負います。
同時に、より長いスクリプトを生成する必要がある場合、関数名やパラメータの偽造など、ChatGPT のいくつかの欠陥が露呈することになります。これが、StackOverflow が ChatGPT を無効にする理由です。コードを生成します。
しかし、ユーザーが明確な実行ステップのセットを提供した場合でも、ChatGPT は、ステップ間の入力と出力間の接続を定義する便利なワークフロー テンプレートを生成できます。これが最も便利な方法である可能性があります。 GPT-3 外挿を使用して新しいコードを生成します。
現時点では、ChatGPT は疑似コード (単純な言語で記述されたアルゴリズム ステップ) を完全なコンピューター実行可能コードに変換できませんが、これは現実からそう遠くないかもしれません。
ChatGPT は、初心者や不慣れなプログラミング言語にとって特に役立ちます。初心者は短いスクリプトしか記述できないため、デバッグがより便利になります。
ChatGPT は非クリエイティブなタスクに優れています
ChatGPT は解決時間に優れています-消費タスク コード内のエラーをデバッグ、検出、説明するための定式化されたタスク。
ChatGPT は、関数ドキュメントを記述するときにも非常に効果的です。たとえば、roxygen 2 のインライン ドキュメント構文を使用すると、すべてのパラメータとクラスを識別するのに非常に効率的ですが、その使用方法についてはほとんど説明されていません。関数。
重要な制限は、ChatGPT の生成が約 500 ワードに制限されており、コードの機能を自動的に確認するための単体テストも生成しながら、より小さなコード ブロックの生成にのみ焦点を当てることができることです。
ChatGPT によって提供されるアドバイスのほとんどは、テストの構造を定義し、予想されるオブジェクト クラスを確認するのに役立ちます。
最後に、ChatGPT は、標準化された (Google など) コード スタイルに従うようにコードを再フォーマットするのに非常に効果的です。
未来は疑似コードに属します
ChatGPT やその他の AI 駆動の自然言語処理ツールは、短い関数の作成、構文のデバッグなど、開発者の単純なタスクを自動化する準備ができています。 、注釈と書式設定、拡張機能の複雑さはユーザーのデバッグ意欲 (および熟練度) によって異なります。
研究者らは、科学分野でのコード作成プロセスを簡素化できるコード生成における ChatGPT の機能を要約しました。ただし、手作業による検査は依然として必要であり、実行可能なコードが必ずしも意味するわけではありません。コードは意図したタスクを実行できるため、単体テストまたは非公式の対話型テストは依然として重要です。

ソリューションが人間によって開発され、単純なコピーによって生成された可能性がある場合は、正しいコードの帰属を確認してください。 ChhatGPT 人は重要です。
すでに、ソース (Microsoft の Bing など) へのリンクを自動的に提供し始めているチャットボットがありますが、このステップはまだ初期段階にあります。
ChatGPT は、従来の方法と比較してコーディング スキルを学習するための代替方法を提供し、擬似コードをコードに直接変換することで最初の作成タスクのハードルを軽減します。
研究者らは、将来の進歩では、ChatGPT などのツールを使用して、書かれたコードを自動的にデバッグし、実験中に発生したエラーに基づいて新しいコードを繰り返し生成、実行、提案するようになるのではないかと考えています。コードを修正する能力は限られており、非常に特殊な命令がコードの小さなブロックを対象とした場合にのみ成功することがあり、デバッグ プロセスは手動デバッグよりもはるかに効率が悪いことがわかりました。
研究者らは、技術の進歩に応じて自動デバッグが改善されるのではないかと考えています (最近リリースされた GPT-4 モデルは、GPT-3 モデルの 10 倍と言われています)。
未来はもうすぐそこまで来ており、開発者は今こそ、新しい AI ツールを活用するための迅速なエンジニアリング スキルを学ぶ時期です。研究者は、人工知能を使用して生成されたコードはますます重要になると予測していますソフトウェア開発のあらゆる側面に組み込まれており、科学的な発見と理解の基礎となる貴重なスキルがますます重要になっています。
以上がプログラマーの未来は「疑似コード」にあり! Nature コラム: ChatGPT を使用して科学研究プログラミングを加速する 3 つの方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。