
URLの入力からページコンテンツの最終的なブラウザレンダリングまでのプロセス分析

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-16 11:28:121659ブラウズ
準備
ブラウザに URL (www.coder.com など) を入力して Enter キーを押すと、ブラウザは最初に coder.com のコードを取得します。 IP アドレス、具体的な方法は、DNS サーバーに UDP パケットを送信し、DNS サーバーは coder.com の IP を返します。このとき、通常、ブラウザーは IP アドレスをキャッシュするため、次回のアクセスが速くなります。 。
たとえば、Chrome では、chrome://net-internals/#dns を通じて表示できます。
サーバーの IP を使用して、ブラウザは HTTP リクエストを開始できますが、HTTP リクエスト/レスポンスは TCP の「仮想接続」で送受信される必要があります。
「仮想」 TCP 接続を確立するには、TCP Postman は 4 つのことを知る必要があります: (ローカル IP、ローカル ポート、サーバー IP、サーバー ポート)。現在は、ローカル IP とサーバー IP のみを知っています。 2つのポートと関係があるのでしょうか?
ローカル ポートは非常に単純です。オペレーティング システムはブラウザにポートをランダムに割り当てることができます。サーバー ポートはさらに単純です。「既知の」ポートを使用します。HTTP サービスは 80 です。 TCP ポストマンを直接。
3 ウェイ ハンドシェイクの後、クライアントとサーバー間の TCP 接続が確立されます。最後に、HTTP リクエストを送信できるようになります。

Web サーバー
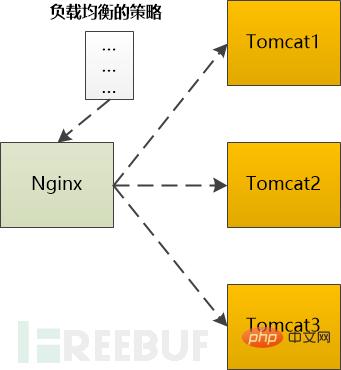
HTTP GET リクエストは数千マイルを通過し、最終的にサーバーに到達するまでに複数のルーターによって転送されます (HTTP パケットは断片化され、下位層によって送信される場合がありますが、これは省略されています)。 Web サーバーは処理を開始する必要があります。これを処理するには 3 つの方法があります:(1) 1 つのスレッドを使用してすべてのリクエストを処理できますが、処理できるのは 1 つのスレッドだけですこの構造は実装が簡単ですが、パフォーマンスに重大な問題を引き起こす可能性があります。非常に人気のある Web サーバーである Nginx を使用して、次の話を続けます。 HTTP GET リクエストの場合、Nginx は epoll を使用してそれを読み取ります。次に、Nginx はこれが静的リクエストであるか動的リクエストであるかを判断する必要があります。 静的なリクエスト (HTML ファイル、JavaScript ファイル、CSS ファイル、画像など) の場合は、自分で処理できる場合があります (もちろん、Nginx の構成に依存し、次のアドレスに転送される可能性があります)。他のキャッシュ サーバー)、読み取りローカル ハード ディスク上の関連ファイルが直接返されます。 それが返される前にバックエンド サーバー (Tomcat など) で処理する必要がある動的リクエストの場合は、Tomcat に転送する必要があります。バックエンドの場合は、特定の戦略に従って選択する必要があります。 たとえば、Ngnix は次のタイプをサポートします。(2) リクエストごとにプロセス/スレッドを割り当てることができますが、接続が多すぎるとサーバー側のプロセス/スレッドが大量のメモリリソースを消費し、プロセス/スレッドの切り替えが発生します。プロセス/スレッドも CPU に過剰な負荷を与える可能性があります。 (3) I/O を再利用するために、多くの Web サーバーは再利用構造を採用しています。たとえば、すべての接続は epoll を通じて監視され、接続の状態が変化した場合 (データが読み取れる場合)、1 つのみを使用します。 process/thread を使用してその接続を処理します。処理後は監視を続け、次のステータスの変化を待ちます。このようにして、数千の接続リクエストを少数のプロセス/スレッドで処理できます。
ポーリング: 順番にバックエンド サーバーに 1 つずつ転送します。 Weight: 各バックエンドに重みを割り当てます。これは、バックエンド サーバーに転送する確率に相当します。 ip_hash: IP に基づいてハッシュ操作を実行し、それを転送するサーバーを見つけます。この方法では、同じクライアント IP が常に同じバックエンド サーバーに転送されます。 fair: バックエンド サーバーの応答時間に基づいてリクエストを割り当て、応答時間帯を優先します。

アプリケーション サーバー
HTTP リクエストが最終的に Tomcat に届きました。Tomcat は Java で書かれており、サーブレット/JSP コンテナを処理できます。コードはこのコンテナ内で実行されます。 Web サーバーと同様に、Tomcat も処理するリクエストごとにスレッドを割り当てることがあります。これは一般に BIO モード (ブロッキング I/O モード) として知られています。 I/O 多重化テクノロジを使用し、少数のスレッドのみを使用してすべてのリクエストを処理することも可能です (つまり、NIO モード)。 どのメソッドが使用されるかに関係なく、HTTP リクエストは処理のためにサーブレットに渡されます。このサーブレットは、HTTP リクエストをフレームワークで使用されるパラメータ形式に変換してから、コントローラ ( Spring を使用している場合)、または Action (Struts を使用している場合)。剩下的故事就比較簡單了(不,對碼農來說,其實是最複雜的部分),就是執行碼農經常寫的增刪改查邏輯,在這個過程中很有可能和緩存、資料庫等後端元件打交道,最終返回HTTP Response,由於細節依賴業務邏輯,略去不表。
根據我們的例子,這個HTTP Response應該是一個HTML頁面。
歸途
Tomcat很高興地把Http Response寄給了Ngnix 。
Ngnix也很高興地把Http Response 發給了瀏覽器。

發完以後TCP連線能關閉嗎?
如果使用的是HTTP1.1, 這個連線預設是keep-alive,也就是說不能關閉;
如果是HTTP1.0,要看之前的HTTP Request Header中有沒有Connetion:keep-alive,如果有,那也不能關閉。
瀏覽器再次工作
瀏覽器收到了Http Response,從其中讀取了HTML頁面,開始準備顯示這個頁面。
但這個HTML頁面中可能引用了大量其他資源,例如js文件,CSS文件,圖片等,這些資源也位於伺服器端,並且可能位於另一個網域下面,例如static.coder.com。
瀏覽器沒辦法,只好一個個下載,從使用DNS取得IP開始,之前做過的事情還要再來一次。不同之處在於不會再有應用伺服器如Tomcat的介入了。
如果需要下載的外部資源太多,瀏覽器會建立多個TCP連接,並行地去下載。
但是同一時間對同一網域下的請求數量也不能太多,要不然伺服器存取量太大,受不了。所以瀏覽器要限制一下, 例如Chrome在Http1.1下只能並行地下載6個資源。
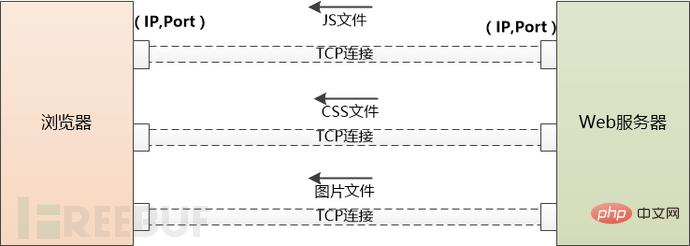
當伺服器給瀏覽器發送JS,CSS這些檔案時,會告訴瀏覽器這些檔案什麼時候過期(使用Cache-Control或Expire),瀏覽器可以把檔案快取到本地,當第二次請求同樣的檔案時,如果不過期,直接從本地取就可以了。
如果過期了,瀏覽器就可以詢問伺服器端,檔案有沒有修改過? (依據是上一次伺服器傳送的Last-Modified和ETag),如果沒有修改過(304 Not Modified),也可以使用快取。否則的話伺服器就會被最新的檔案傳回瀏覽器。
當然如果你按了Ctrl F5,會強制地發出GET請求,完全無視快取。
附註:在Chrome下,可以透過 chrome://view-http-cache/ 指令來查看快取。
現在瀏覽器得到了三個重要的東西:
1.HTML ,瀏覽器把它變成DOM Tree
2. CSS, 瀏覽器把它變成CSS Rule Tree
3. JavaScript, 它可以修改DOM Tree
#瀏覽器會透過DOM Tree和CSS Rule Tree產生所謂“Render Tree”,計算每個元素的位置/大小,進行佈局,然後呼叫作業系統的API進行繪製,這是一個非常複雜的過程,略去不表。
到目前為止,我們終於在瀏覽器中看到了www.coder.com的內容。
以上がURLの入力からページコンテンツの最終的なブラウザレンダリングまでのプロセス分析の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。