
ホームページ >テクノロジー周辺機器 >AI >OpenAI テキスト生成 3D モデルがアップグレードされ、数秒でモデリングが完了し、Point・E よりも使いやすくなりました
OpenAI テキスト生成 3D モデルがアップグレードされ、数秒でモデリングが完了し、Point・E よりも使いやすくなりました

- WBOY転載
- 2023-05-16 10:04:131575ブラウズ
生成 AI ラージ モデルは OpenAI の取り組みの焦点であり、テキスト生成画像モデル DALL-E および DALL-E 2 と、以前にテキストに基づいて 3D モデルを生成する POINT-E をすでにリリースしています。今年。
最近、OpenAI 研究チーム は 3D 生成モデルをアップグレードし、3D アセットを合成するための条件付き生成モデルである Shap・E を新たに開始しました 。現在、関連するモデルの重み、推論コード、サンプルはオープンソース化されています。

- 紙のアドレス : https://arxiv.org/abs/2305.02463
- プロジェクトアドレス: https://github.com/openai/shap-e
まず生成効果を見てみましょう。 Shap・Eが生成する3Dオブジェクトモデルは、テキストをもとに画像を生成するのと同様に「制約のない」ことに重点を置いています。たとえば、バナナのように見える飛行機:


 # もちろん、一般的なオブジェクトの中には、次のようなものもあります。 3D モデルも生成されます。たとえば、野菜ボウル:
# もちろん、一般的なオブジェクトの中には、次のようなものもあります。 3D モデルも生成されます。たとえば、野菜ボウル:
 ドーナツ:
ドーナツ:

同じデータセット、モデルアーキテクチャ、トレーニング計算を仮定すると、Shap・E は同様の明示的生成モデル # よりも優れています。研究者らは、純粋なテキスト条件付きモデルが多様で興味深いオブジェクトを生成できることを発見し、これは暗黙的な表現を生成する可能性も示しています。

。 研究の背景
この記事では、3D 表現のための 2 つの暗黙的ニューラル表現 (INR) に焦点を当てます:- NeRF 座標と視線方向を密度と RGB カラーにマッピングする関数として 3D シーンを表す INR;
- DMTet とその拡張子 GET3D座標を色、符号付き距離、頂点オフセットに関数としてマッピングするテクスチャ付き 3D メッシュ。この INR により、3D 三角形メッシュを微分可能な方法で構築し、微分可能なラスタライゼーション ライブラリにレンダリングできるようになります。
INR は柔軟で表現力に富んでいますが、データセット内のすべてのサンプルの INR を取得するにはコストがかかります。さらに、各 INR には多くの数値パラメーターが含まれる可能性があるため、下流の生成モデルをトレーニングするときに問題が発生する可能性があります。暗黙的デコーダーを備えたオートエンコーダーを使用してこれらの問題を解決することにより、既存の生成技術で直接モデル化されたより小さな潜在表現を取得できます。別のアプローチは、メタ学習を使用してパラメータの大部分を共有する INR のデータセットを作成し、これらの INR の自由パラメータで拡散モデルまたは正規化されたフローをトレーニングすることです。また、勾配ベースのメタ学習は必要ではなく、代わりに 3D オブジェクトの複数のビューを条件とした NeRF パラメータを生成するように Transformer エンコーダを直接トレーニングする必要があることも示唆されています。
研究者らは、上記の手法を組み合わせて拡張し、最終的にさまざまな複雑な 3D 暗黙的表現の条件付き生成モデルとなる Shap・E を取得しました。まず、Transformer ベースのエンコーダーをトレーニングして 3D アセットの INR パラメーターを生成し、次にエンコーダーの出力で拡散モデルをトレーニングします。以前のアプローチとは異なり、NeRF とメッシュの両方を表す INR が生成されるため、さまざまな方法でレンダリングしたり、ダウンストリーム 3D アプリケーションにインポートしたりできます。
数百万の 3D アセットのデータセットでトレーニングすると、私たちのモデルはテキスト プロンプトの下でさまざまな識別可能なサンプルを生成できます。 Shap-E は、最近提案された明示的 3D 生成モデルである Point・E よりも速く収束します。同じモデル アーキテクチャ、データ セット、コンディショニング メカニズムを使用して、同等以上の結果を達成できます。
方法の概要
研究者は、まずエンコーダーをトレーニングして暗黙的表現を生成し、次にエンコーダーによって生成された潜在表現に基づいて拡散モデルをトレーニングします。これは主に分割されています。次の 2 つのステップに分割 完了:
#1. 既知の 3D アセットの密な明示的表現が与えられた場合に、暗黙的関数のパラメーターを生成するようにエンコーダーをトレーニングします。エンコーダーは 3D アセットの潜在表現を生成し、その後線形投影を行って多層パーセプトロン (MLP) の重みを取得します;
2. エンコーダーをデータセットに適用してからトレーニングしますセット上の拡散プリア。モデルは画像またはテキストの説明に基づいて条件付けされます。
対応するレンダリング、点群、テキスト キャプションを使用して、3D アセットの大規模なデータセットですべてのモデルをトレーニングしました。
3D エンコーダ
エンコーダのアーキテクチャを以下の図 2 に示します。
潜在的な拡散
生成モデルは変圧器に基づいた Point・E 拡散アーキテクチャを採用していますが、代わりに潜在ベクトル シーケンス点群。潜在関数形状のシーケンスは 1024 x 1024 で、1024 個のトークンのシーケンスとしてトランスフォーマーに入力されます。各トークンは MLP 重み行列の異なる行に対応します。したがって、このモデルは計算的には基本の Point・E モデルとほぼ同等です (つまり、コンテキストの長さと幅が同じです)。これに基づいて、入力チャンネルと出力チャンネルが追加され、高次元空間でサンプルが生成されます。
実験結果
エンコーダの評価
研究者はエンコーダのトレーニング プロセス全体を実施しました。トラック 2レンダリングベースのメトリクス。まず、再構成されたイメージと実際のレンダリングされたイメージの間のピーク信号対雑音比 (PSNR) を評価します。さらに、3D アセットの意味的に関連する詳細をキャプチャするエンコーダの能力を測定するために、最大の Point·E モデルによって生成されたメッシュをエンコードすることによって、再構成された NeRF および STF レンダリングの CLIP R-Precision が再評価されました。
以下の表 1 は、さまざまなトレーニング段階でのこれら 2 つの指標の結果を追跡しています。蒸留は NeRF 再構成品質に悪影響を及ぼしますが、微調整により NeRF 品質が復元されるだけでなくわずかに改善され、同時に STF レンダリング品質が大幅に向上することがわかります。
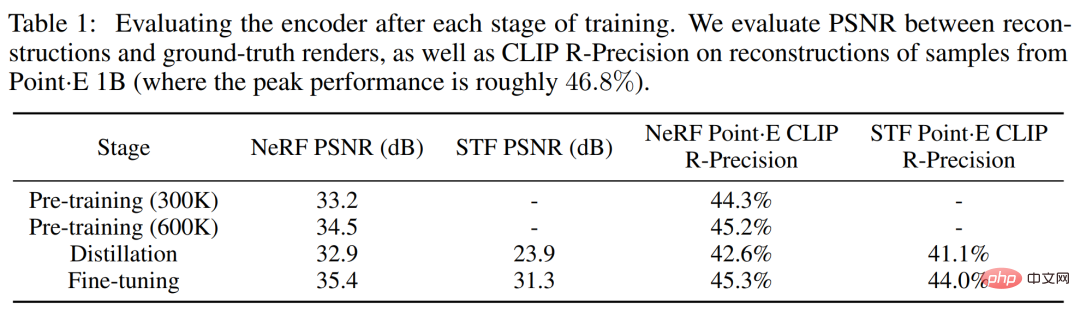
比較ポイント・E
研究者 提案されたもの潜在拡散モデルは、Point・E と同じアーキテクチャ、トレーニング データ セット、および条件付きパターンを持ちます。 Point・E との比較は、明示的な表現ではなく暗黙的なニューラル表現の生成の効果を区別するのに役立ちます。以下の図 4 は、サンプルベースの評価基準に関するこれらの方法を比較しています。
定性サンプルを以下の図 5 に示します。これらのモデルは、同じテキスト プロンプトに対してさまざまな品質のサンプルを生成することが多いことがわかります。学習が終了する前に、テキスト条件 Shap・E の評価が悪化し始めます。 
研究者らは、以下の図 6 (a) に示すように、Shap・E と Point・E が同様の障害ケースを共有する傾向があることを発見しました。これは、トレーニング データ、モデル アーキテクチャ、条件付けされた画像が、選択された表現空間よりも生成されたサンプルに大きな影響を与えることを示唆しています。
2 つの画像条件モデル間には、まだ定性的な違いがあることがわかります。たとえば、以下の図 6(b) の最初の行では、点・E はベンチ小を無視しています。 Shap・E はギャップをモデル化しようとします。この記事では、点群が薄いフィーチャやギャップを適切に表現していないために、この特定の不一致が発生するという仮説を立てています。また、表 1 では、3D エンコーダを Point・E サンプルに適用すると、CLIP R-Precision がわずかに低下することがわかります。

他の方法との比較 ##以下の表 2 では、研究者は、CLIP R-Precision メトリックに関して、shape・E をより広範囲の 3D 生成技術と比較しています。
##限界と展望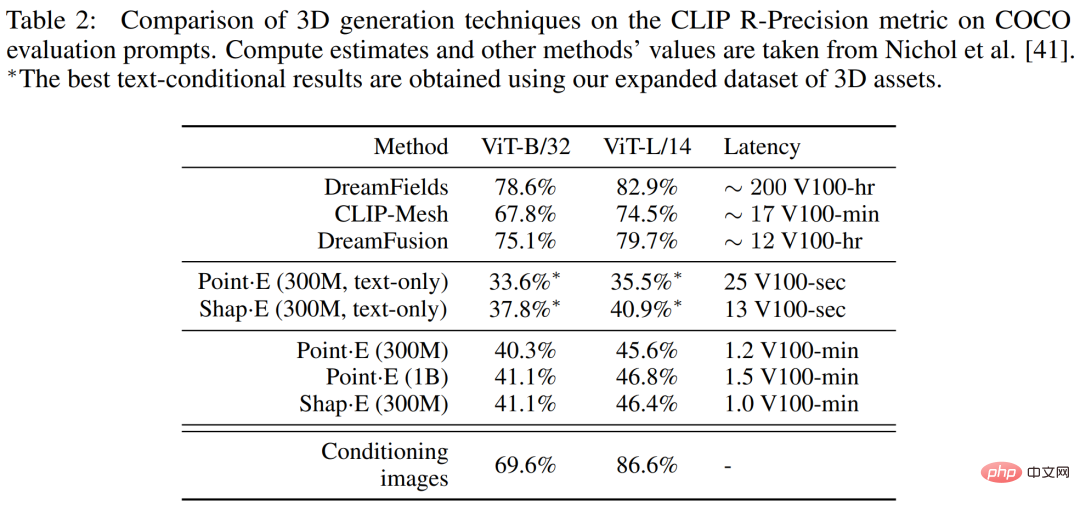
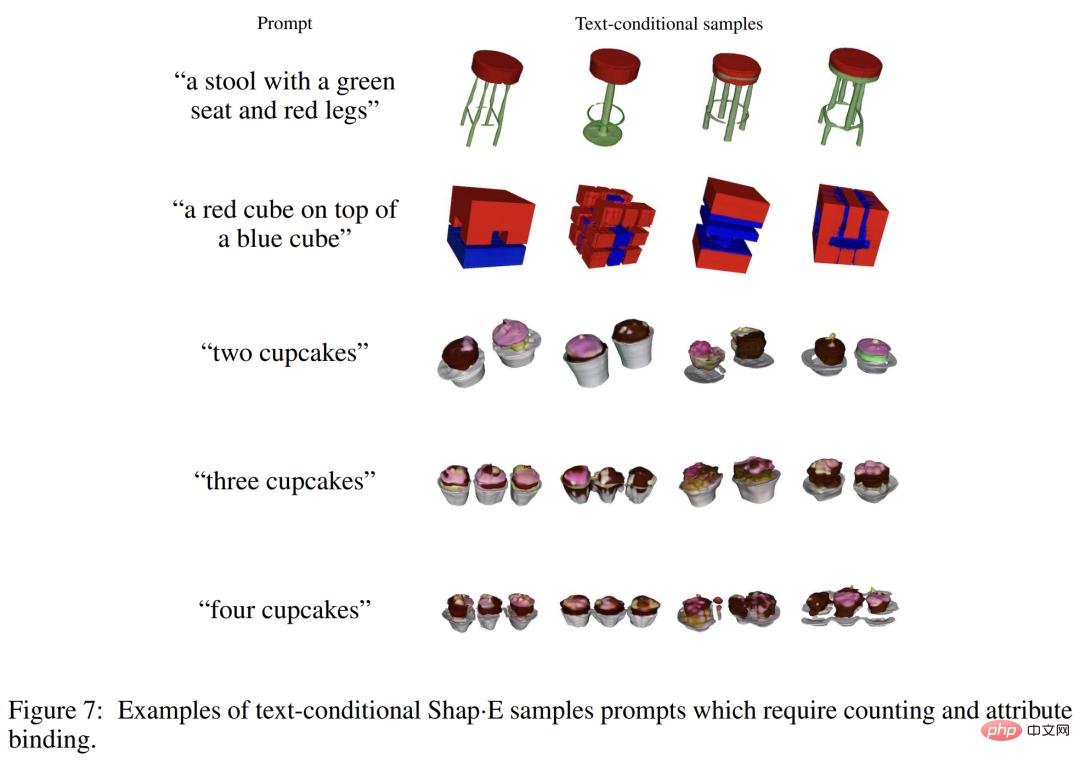 さらに、Shap・E は認識可能な 3D アセットを生成しますが、これらは粗く見えたり、詳細が欠けていることがよくあります。以下の図 3 は、エンコーダーが詳細なテクスチャ (サボテンの縞模様など) を失う場合があることを示しており、改良されたエンコーダーによって失われた世代の品質の一部が復元される可能性があることを示唆しています。
さらに、Shap・E は認識可能な 3D アセットを生成しますが、これらは粗く見えたり、詳細が欠けていることがよくあります。以下の図 3 は、エンコーダーが詳細なテクスチャ (サボテンの縞模様など) を失う場合があることを示しており、改良されたエンコーダーによって失われた世代の品質の一部が復元される可能性があることを示唆しています。
 技術的および実験的な詳細については、元の論文を参照してください。
技術的および実験的な詳細については、元の論文を参照してください。
以上がOpenAI テキスト生成 3D モデルがアップグレードされ、数秒でモデリングが完了し、Point・E よりも使いやすくなりましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。