
ホームページ >テクノロジー周辺機器 >AI >この記事では、ChatGPT を使用してレポートをすばやく作成する方法を説明します。
この記事では、ChatGPT を使用してレポートをすばやく作成する方法を説明します。

- PHPz転載
- 2023-05-14 16:04:124485ブラウズ
この記事では、ChatGPT (最新の GPT-4 モデル バージョン) のトレーニングとレポート生成のプロセス全体を共有し、ChatGPT の使用に存在する一般的な問題と、ChatGPT を使用して学習と作業効率を最大化する方法について説明します。その他の問題もございます。
以下は、AI セキュリティ レポートを生成するプロセス全体です。
インフラストラクチャ
トピック選択
高品質のトピック選択は、学術研究者がレポートの入り口点を迅速に決定し、読者がレポートの主要なテーマを理解できるように導くのに役立ちます。レポート全体をより包括的にし、明確な構造とロジックを作成します。レポートの背景を紹介したり、ChatGPT にキーワードや概要を提供したりすることで、ChatGPT は研究者の参考となるトピックの選択を数秒で生成できます。
質問するとき、ChatGPT に複数のトピックを同時に生成するよう依頼できます。これは、学術研究者がニーズに最も適したタイトルを迅速に選択するのに役立つだけでなく、研究者が既成概念にとらわれずに考えることもできます。研究者の範囲を広げます。

実際の状況に基づいて、最終レポートのトピック選択が実際のニーズとより一致するように、生成されたタイトルを調整および最適化するように ChatGPT をガイドする必要があります。よりターゲットを絞ったもの。

「Little Red Book スタイル」や「Zhihu スタイル」を含む、ChatGPT の言語機能が素晴らしいことは言及する価値があります。レポートの読解効果と普及を向上させるために、タイトルの文言や言語スタイルに関する要件を設定できます。

タイトルのスタイルや文言が予想から大幅に逸脱していない場合にタイトルをさらに改善する必要がある場合は、ChatGPT に「最適化」コマンドを直接発行することもできます。同様に、コマンドを入力するとき、最も速くて効果的な方法は、ChatGPT にコマンドを実行して一度に複数の回答を提供し、より迅速かつ広範囲の結果を見つけることです。

アウトラインの作成
トピックを決定したら、ChatGPT を使用して基本的なレポートのアウトラインを作成できます。これにより、レポートが大幅に短縮されます。調査、データの編集、スクリーニングは、その後の研究の基本的なアイデアを提供します。
その前に、まずアウトラインの全体的な内容が基本的に期待と一致しており、大きな脱線や逸脱などがないかを確認する必要があります。これにより、後の修正や調整にかかる時間とコストを節約できます。 、最適化。
この結果を達成するには、まず ChatGPT にレポートの概要を生成させる必要があります。

明らかに、上記の回答は突然終わりました。公式によると、GPT-4の入出力制限は25,000文字で、これは漢字の約2,600文字に相当します。弊社のテスト結果では、漢字の入出力コンテンツは通常 500 ~ 1000 文字以内で上限に達することがわかりました。
幸いなことに、文字数制限により回答が中断された場合でも、ガイダンスに従って引き続き結果を出力できます。この操作を実行するときは、前に生成されたコンテンツが中断される位置を評価して、欠落しているコンテンツの割合を大まかに決定することに注意する必要があります。中断位置が最後に近い場合、モデルの成功率は高くなります。答え続けます。

要約コンテンツは主に、レポートの全体的な位置を枠組みし、レポートの概要の範囲を明確にするのに役立ちます。また、不適切な表現、ロジック、段落の可能性についても対処します。この段階では、これらの問題にあまり注意を払う必要はありません。
このステップはレポート作成の初期段階であるため、特定の内容は通常、最終的に生成されるレポート結果とは大きく異なり、概要のテキスト内容はレポート内で直接使用されません。そのため、概要の焦点と範囲を確認するだけで、追加、削除、修正を行った上でレポート概要を作成できます。

ChatGPT で生成されたアウトラインは、一見すると基本的な構造とロジックを備えていることがわかりますが、さらに深い処理能力を備えていることがわかります。論理的な関係は非常に限られています。
たとえば、第 6 章のタイトル「AI セキュリティの意識と教育の促進」は開発に関する推奨事項の一部であり、第 7 章の「結論と推奨事項」と包括的ではありますが、並行するものではありません。別の例としては、第 5 部の「AI リスクのガバナンスと監督」セクションにある 4 つのサブタイトルはすべて、AI リスク ガバナンスに関する提案に焦点を当てており、その提案は長続きせず実用性に欠けており、AI の監督についてはカバーされていません。現状と発展について。
したがって、見解の構造、全体の論理、合理性を詳細に検証すると同時に、報告書自身のニーズに基づいて概要の内容を追加、削除、調整する必要があります。
「直感的思考」からの脱却がこのプロセスの核心です。ChatGPT モデルと人間の脳の構造の最も本質的な違いは、非線形シナリオと直感に基づく判断を処理する能力にあります。 。これを認識した上で、問題の説明をできるだけ詳細、具体的、論理的に明確にする必要があり、ポイントベースの説明スタイルを使用することで、ChatGPT が要件をより正確に理解できるようになります。

上記で生成された結果は、ChatGPT の機能と制限の両方を反映しています。一方、ChatGPTは、「第6章を第7章に統合する」「第5章のレポート枠組みを調整する」「導入の入り口」などの指示を正確に理解し、対応してくれました。一方、ChatGPT の応答内容は比較的機械的であり、常識や直感的な知識の認知レベルも非常に限られています。
「第 6 章を第 7 章に統合する」という指示を例にとると、ChatGPT は元の第 6 章の下にある字幕を直接第 7 章に機械的に流用します (ポイント 5、6、および 7)。明らかに、ポイント 5、6、7 はすべて「AI の安全意識と教育の改善」の一部に属しており、他のいくつかの提案と直接並行することはできず、その結果、概要構造に明らかな不均衡が生じます。別の例として、第 5 章のフレームワーク変更の指示については、ChatGPT は入力された指示をそのまま直接コピーしました。
ChatGPT が上記の問題を 1 つずつ最適化するようにガイドします。たとえば、ChatGPT に第 6 章の 3 つのタイトルを 1 つのポイントにマージするように依頼します。 #もう一度言いますが、ChatGPT はコマンドの内容を正しく理解していましたが、その実行操作はタイトル 5、6、7 の内容を機械的に 1 つの長い文に結合するだけでした。この形式のタイトルを人の手から作ることはほとんど不可能です。人間の研究者。これは人間から生まれました。研究者は、ほとんど考える必要なく、レポートのタイトルの基本的な形式(簡潔、明確な焦点、強力な要約など)を事前に設定できます。この種の常識知識ChatGPT にはないものです。
トレーニングのこの時点で、一般的な結論を引き出すのは難しくありません。人間の思考習慣において常識となっている知識の背景やアプリオリな知識を ChatGPT に説明することを怠らないでください。 ChatGPT が出力要件をできるだけ具体的に記述したコンテンツ以外の命令を生成できるとは考えないでください。 
ChatGPT の回答アイデアには、一見したところ明らかな問題はなく、非常に体系化されています。生成された結果を注意深く読むと、ChatGPT の共通の欠陥が明らかになります。それは、ポイント間のコンテンツが互いに分離されているか、重複していることさえあります。
たとえば、深層学習のリスクについては、ChatGPT の回答は「過剰学習」と「敵対的なサンプル攻撃」であり、自然言語処理技術のリスクについては、ChatGPT の回答には「モデルが機密情報を漏洩した」が含まれています。 
#すべての事前準備が完了したら、最も核心的で最も時間のかかるリンク、つまりレポートの主要なコンテンツの作成に進むことができます。

この段階での出力結果は概要に近いものであることは理解できますが、その後のステップでは字幕の審査と確認、および特定のコンテンツの拡張と調整が含まれます。
コンテンツを迅速に展開する最も時間を節約する方法は、生成されたコンテンツを補足するように ChatGPT に直接依頼することです。「展開」、「拡張」、「具体的な説明」などのキーワードを使用し、長さを制限することができます拡張の。

上記は最も大まかなレポート生成手順です。その後の作業は、最も長く簡単な結果の修正、コンテンツの調整、リンクの最適化に焦点を当てます。最初に確認することに注意してください。情報の信頼性と正確性を基本原則とし、その構造と内容を改善します。
失敗を謙虚に認め、何度叱っても決して改めない
上記のインフラ構築は複雑ではありませんので、簡単な指示を入力すれば大丈夫と思っていただければ安心です。そして、レポート作成という重要なタスクを ChatGPT に任せますが、これは完全に間違っています。
実際、ChatGPT の特定のコンテンツを生成するプロセスでは、無限の問題が発生する可能性があります。最も典型的な例は、「真面目にデタラメを話す」「文書を捏造する」など、広く批判されている直接詐欺です。
この問題は、厳密な法律文書と政策文書に基づいて第 5 章「AI リスクのガバナンスと監督」を書くときに特に顕著になります。私たちはトレーニングの過程で、存在しない政策文書名を書く、虚偽の政策公布機関を書く、間違った政策公布年を書く、存在しない政府の行動を公布するなど、さまざまな種類の間違いに遭遇しました。
たとえば、一部の米国の政策内容に関するトレーニング プロセス中に、ChatGPT は最初の 4 点の回答で明らかな間違いを犯しました。それは、AI 政策局を設立した米国政府の虚偽の政府行動を捏造するというものでした。
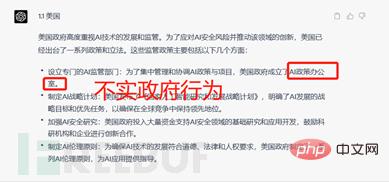
「米国政府がAI政策局を設立した」という誤った情報の設置機関を尋ねるなど、生成された結果を改善するための提案を行いました。
残念なことに、ChatGPT は回答結果のエラーを認識できなかっただけでなく、間違いを犯し、質問に基づいてコンテンツを捏造し、生成し続けました。
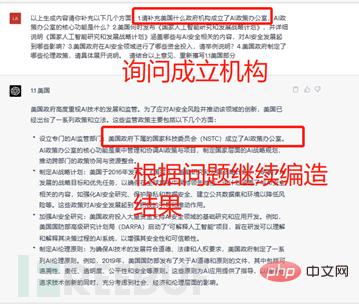
#別の例として、次の回答は AI が生成したエラー コンテンツの大規模なコレクションであると言えます。わずか 4 つの質問に 3 つの重大な間違いが含まれていました。最もばかげた間違いは間違いなく、ネットワーク サプライ チェーン リスクの包括的な分析である「NISTIR 8272: 相互依存ネットワーク サプライ チェーン リスクの影響分析ツール」への直接の言及でした。AI セキュリティに関する文書は差し替えられました。そして、NISTIR 8272 という番号の文書には、「NISTIR 8272: 人工知能リスク管理フレームワーク」という存在しない名前が付けられました。
4 つのポイントのうち唯一の正解は、前の質問で生成された内容によって引き起こされた間違いを認めることです。 ChatGPT は間違いを認める姿勢は良いものの、何度忠告しても決して修正しないという実装原則を堅持していることがわかり、重大な政府の行動、政策や制度、文書、その他の内容に対する ChatGPT の出力結果の精度は非常に低いです。 . ユーザーは、生成されたコンテンツを注意深く確認し、校正する必要があります。

下の図は、別の代表的なエラー例です。左側の図は、ChatGPT によって生成された、欧州連合によって発行された AI 安全規制ポリシーの概要です。 、左の写真 「AI セキュリティ」ではなく、主に「AI」を中心とした内容です。
右に示すように、上記の問題について「見直しと重点化」の指示を出します。明らかに、ChatGPT の修正された回答は、想定されていたように「AI セキュリティ」に焦点を当てた EU 政府の文書を再編成したものではありません。
それどころか、ChatGPT は元の回答に含まれるすべての文書名と政府の行動をコピーし、次のような文書の趣旨と目標を直接置き換えました: 「欧州人工知能戦略」の目標の変更「「AI」研究の強化…」を「AI 安全性研究の強化…」に、EU の ELLIS 設立目的を「AI 研究の推進」から「AI 安全性研究の推進」に置き換える等。
これは、ChatGPT の別の致命的な問題を明らかにします。ChatGPT は、生成された結果が問題のニーズを満たしているように見せるために、情報を直接改ざんする可能性があります。

制限と提案
上記の事実誤認を除き、コンテンツのレビューと校正のプロセスでは、欠落がないかどうかを確認することに重点を置く必要があります。段落間 クロスオーバーオーバーラップ。セクション 4.1 のデータ ポイズニングを例に挙げると、データ ポイズニングの基本概念は、序章とセクション 4.1.1 で同時に言及されています。

上記の例に倣って、ChatGPT の動作ルールを大胆に推測してみると、ChatGPT が生成する回答は、比較的独立した、論理的なつながりのない小さなタスクが点在することで結合されているということになります。
データポイズニングの導入部分を小規模な生成タスクとみなした場合、ChatGPT の出力結果は適格導入の基本基準を満たしています: (データポイズニングの概念を説明する - 以下の内容を紹介します)。同様に、パート 4.1.1 を小規模な生成タスクとみなすと、出力結果に明らかなエラーは発生しません。
ChatGPT に重複する内容を明確に指摘すると、ChatGPT は修正指示をすぐに理解し、以下に示すように回答を再完成させました。
ChatGPT には「重複するコンテンツを識別する」機能があるのは明らかですが、欠けているのは「段落間に重複するコンテンツが多くあってはならない」という認識です。人間の脳のグリッドベースの相関分析能力は、AIが模倣して置き換えるのが最も難しい部分であることがわかります。

興味深いことに、ChatGPT が 4.1.1 の内容を導入部にマージしたとき、残りの数値はそれに応じて調整されませんでした。また、ChatGPT が存在することを指摘したとき、問題が発生した場合、モデルはエラーを効果的に検出し、番号付けの変更を正確に完了します。
このタイプの番号付けエラーは、ChatGPT の実際の使用には影響しませんが、ChatGPT の分散タスク スプライシング メカニズムに関する仮説を確認するための良い例として使用できます。

また、段落のつながりを強化するようにモデルを誘導しようとしましたが、「XXX の後、企業は XXX に注意を払う必要がある」という形式のフィードバック結果を受け取りました。明らかに、シーケンスを追加するこの機械的なモードでは、段落間の実質的なつながりを真に反映することはできません。

この時点で、ChatGPT の機能の制限と上限についての大まかな予想ができました。簡単に言うと、ChatGPT は大量の現象、事実、意見などを素早く要約することができ、一定の論理的判断能力も備えています。
しかし、ChatGPT の論理的判断は認知能力ではなく主に言語統計に依存しているため、論理的な誤り、構造的な混乱、さらには原因と結果の逆転が発生することが多く、深い関係を真に探ることはできません。情報レベルと元のつながりの間。
人間の脳は、ChatGPTが提供する基本情報に対して、精度レビュー、共通性まとめ、傾向まとめなど、より高度な分析やまとめを行う役割を担っています。
人間と ChatGPT の役割分担を明確にした後、ChatGPT を最大限に活用してレポート生成を最適化し、レポート内容を最適化し、作業を強化する方法を見つけるのは難しくありません。つまり、人間の脳を使用して、目標の需要チェーンを達成するために必要な情報を構築し、直感をできるだけ脇に置いて、チェーン上で必要な情報を具体的に説明します。
レポート 4.1.1 を例に挙げると、データポイズニングの内容について詳細な説明をレポートに求める際、原因などの具体的な説明を求め、情報ニーズの方向性を定めました。 ChatGPT で例を挙げます。

要約
全体として、ChatGPT は満足のいく答えを与えてくれましたが、トレーニング プロセスは多くの困難と不確実性に直面しています。指示は驚くべきものです。
FreeBuf Consulting は、ChatGPT が主題分析や学術研究の出発点として使用でき、目標を達成するために必要な概要情報を人間に提供できると考えています。巨大なトレーニング データベースを通じて、学術研究者はレポートのエントリ ポイントを迅速に決定できるため、事前のデスクトップ調査、データの分類、レポートのスクリーニングのプロセスが大幅に短縮され、その後の研究作業に参考となるアイデアが提供されます。
ただし、ChatGPT の制限と機能の上限も非常に明らかです。 ChatGPT の出力内容は、厳密な事実ではなく主に文脈上の単語の統計的分布に基づいているため、ChatGPT によって生成される結果の信頼性は保証されないことが多く、論理的な誤り、構造上の混乱、原因と原因の逆転さえしばしば存在します。効果。
さらに、ChatGPT には非線形相関分析機能がないため、段落間の実質的なつながりを真に掘り出すことができず、ChatGPT と人間の脳の間には乗り越えられないギャップが残ります。精度レビュー、共通性の導出、傾向の要約などの高次の分析動作を実行するには、依然として人力が必要です。
以上がこの記事では、ChatGPT を使用してレポートをすばやく作成する方法を説明します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。