
ホームページ >バックエンド開発 >Python チュートリアル >Pythonのデータクリーニング方法とは何ですか?
Pythonのデータクリーニング方法とは何ですか?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-05-13 16:19:062207ブラウズ
ここでのデータ クリーニングに必要なライブラリは、pandas ライブラリです。ダウンロード メソッドはまだターミナルで実行中です: pip install pandas.
最初にデータを読み取る必要があります
import pandas as pd data = pd.read_csv(r'E:\PYthon\用户价值分析 RFM模型\data.csv') pd.set_option('display.max_columns', 888) # 大于总列数 pd.set_option('display.width', 1000) print(data.head()) print(data.info())
Line 3 データの読み取りです. pandas ライブラリには read 関数呼び出しがあり、csv 形式が最も高速に読み書きできます。
4 行目と 5 行目は、読み取り時にすべての列を表示するためのものです。列が多い場合、pycharm は中央の列の一部を非表示にするため、これらの 2 行のコードを追加して、非表示にならないようにします。
6 行目はテーブルのヘッダーを表示します。どのようなフィールドがあるのか、列名がわかります。
7 行目はテーブルの基本情報が表示されます。各列のデータ量が表示されます。それはどのような種類のフィールドですか? データです。空ではないデータがどれだけあるか、最初のステップでどの基本列に null 値があるかを確認できます。
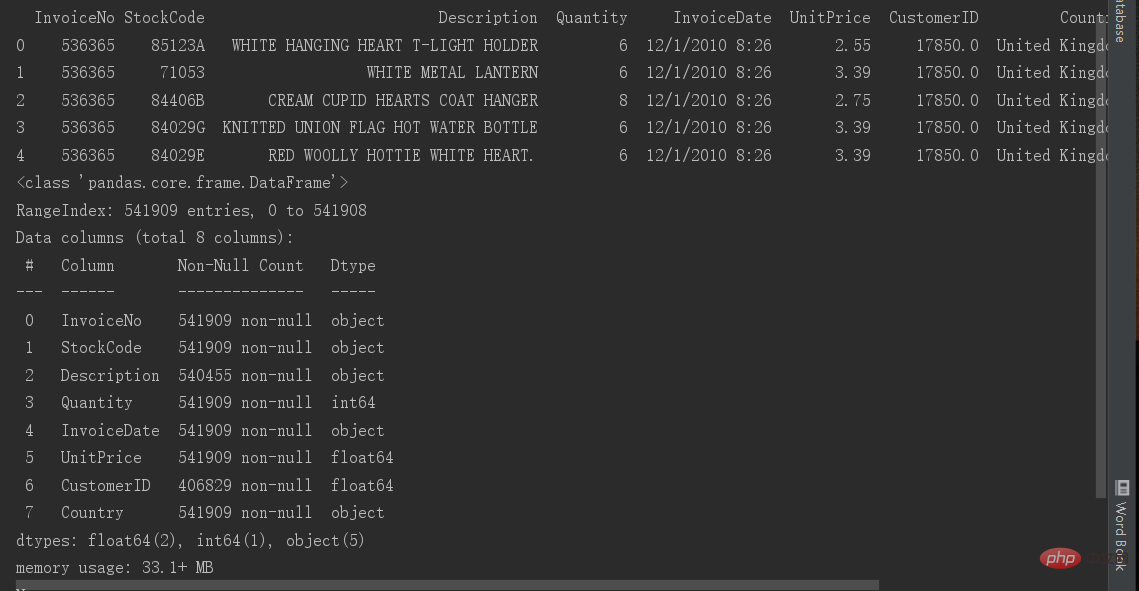
Null 値の処理
data.info() の後、ほとんどのデータに 541909 行があることがわかります。そのため、大まかに説明だと推測します。 CustomerID 列に結果がありません
# 空值处理 print(data.isnull().sum()) # 空值中和,查看每一列的空值 # 空值删除 data.drop(columns=['Description'], inplace=True) print(data.info()) data.isnull()判断是否为空。data.isnumll().sum()计算空值数量。
5 行目で null 値を削除します。ここでは、最初に description 列の null 値を削除します。inplace=True はデータを変更することを意味します。inplace=True がない場合、データは変更されません。印刷データは以前と同じであるか、変数が割り当てのために再定義されます。
この列には null 値が比較的少ないため、このデータ列はデータ分析にとってそれほど重要ではないため、この列全体を削除することにします。
このテーブルは顧客をフィルタリングするために使用されるため、CustomerID が標準として使用され、他の列は強制的に削除されます。
# CustomerID有空值 # 删除所有列的空值 data.dropna(inplace=True) # print(data.info()) print(data.isnull().sum()) # 由于CustomerID为必须字段,所以强制删除其他列,以CustomerID为准
ここでは、最初に他のフィールドに対して型変換を実行します
型変換
# 转换为日期类型 data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate']) # CustomerID 转换为整型 data['CustomerID'] = data['CustomerID'].astype('int') print(data.info())
上ではnull値を扱いましたが、次は異常値を扱います。
異常値処理
テーブルの基本的なデータ分布を表示するには、describe
print(data.describe())
を使用します。データ数量列の最小値が - であることがわかります。 80995。この列には明らかに異常な値があるため、この列をフィルターして外れ値を除去する必要があります。
0 より大きい値のみが必要です。
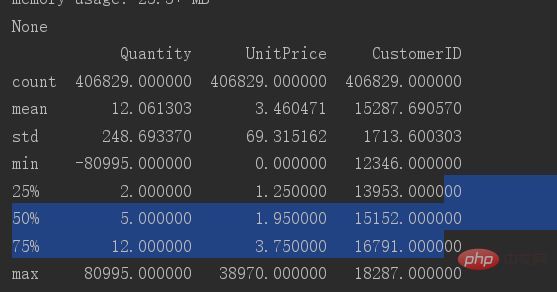
data = data[data['Quantity'] > 0] print(data)
印刷すると、行数は 397924 行のみになります。
重複値の処理
# 查看重复值 print(data[data.duplicated()])
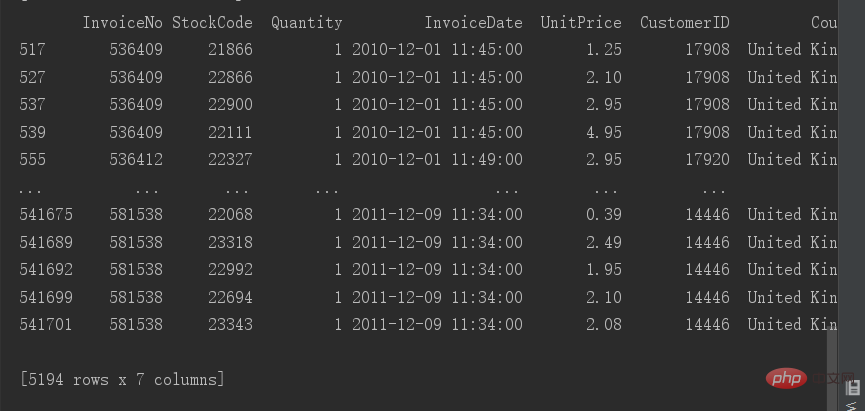
重複値は 5194 行あります。ここでの重複値は完全に重複しているため、不要なものとして削除できます。データ。 。
重複した値を削除
# 删除重复值 data.drop_duplicates(inplace=True) print(data.info())
削除後に元のテーブルを保存し、テーブルの基本情報を確認してください
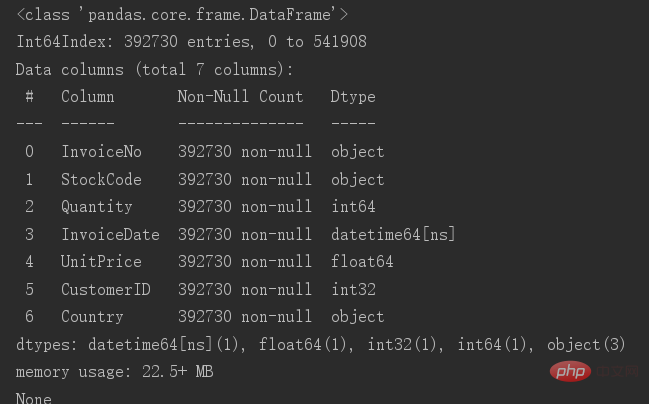
まだ残っています現在 392730 個のデータが残っています。このステップでデータのクリーニングが完了します。
以上がPythonのデータクリーニング方法とは何ですか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。