
ホームページ >テクノロジー周辺機器 >AI >Actor-Critic の DDPG 強化学習アルゴリズムを使用した二重関節ロボット アームの制御
Actor-Critic の DDPG 強化学習アルゴリズムを使用した二重関節ロボット アームの制御

- 王林転載
- 2023-05-12 21:55:17823ブラウズ
この記事では、Unity ML-Agents ツールキットを使用して開発された Unity ベースのシミュレーション プログラムである Reacher 環境で二重関節ロボット アームを制御するインテリジェント エージェントのトレーニングを紹介します。私たちの目標は、高精度でターゲット位置に到達することです。そのため、ここでは、連続状態およびアクション空間用に設計された最先端の Deep Deterministic Policy Gradient (DDPG) アルゴリズムを使用できます。

実世界への応用
ロボット アームは、製造、生産施設、宇宙探査、捜索救助活動において重要な役割を果たします。ロボットアームを高精度かつ柔軟に制御することが非常に重要です。強化学習技術を採用することで、これらのロボット システムはリアルタイムで動作を学習して調整できるようになり、パフォーマンスと柔軟性が向上します。強化学習の進歩は、人工知能の理解に貢献するだけでなく、産業に革命を起こし、社会に有意義な影響を与える可能性があります。
Reacher は、制御アルゴリズムの開発とテストによく使用されるロボット アーム シミュレーターです。ロボット アームの物理的特性と運動法則をシミュレートする仮想環境を提供し、開発者は実際のハードウェアを必要とせずに制御アルゴリズムの研究と実験を行うことができます。
Reacher の環境は主に次の部分で構成されます:
- ロボット アーム: Reacher は、固定ベースと 2 つの可動ジョイントを含む二重関節ロボット アームをシミュレートします。開発者は、ロボット アームの 2 つの関節を制御することで、ロボット アームの姿勢や位置を変更できます。
- 目標点: ロボット アームの移動範囲内で、Reacher が目標点を提供します。目標点の位置はランダムに生成されます。開発者のタスクは、ロボット アームの端が目標点に接触できるようにロボット アームを制御することです。
- 物理エンジン: Reacher は物理エンジンを使用して、ロボット アームの物理的特性と動作パターンをシミュレートします。開発者は、物理エンジンのパラメーターを調整することで、さまざまな物理環境をシミュレートできます。
- ビジュアルインターフェイス: Reacher は、ロボットアームと目標点の位置、ロボットアームの姿勢と移動軌跡を表示できるビジュアルインターフェイスを提供します。開発者は、ビジュアル インターフェイスを通じて制御アルゴリズムをデバッグおよび最適化できます。
Reacher シミュレーターは、開発者が実際のハードウェアを必要とせずに制御アルゴリズムを迅速にテストし、最適化するのに役立つ非常に実用的なツールです。
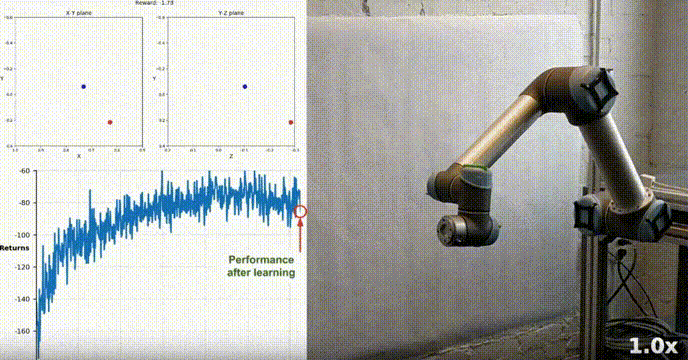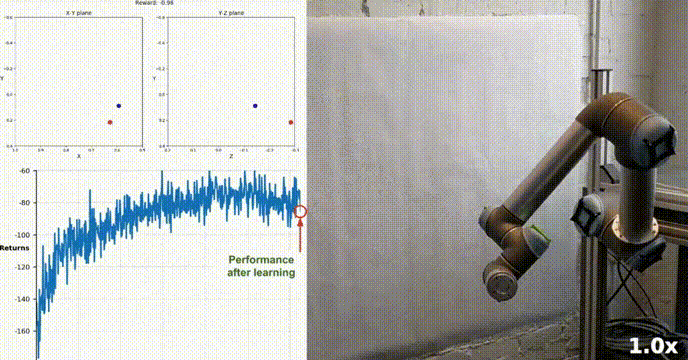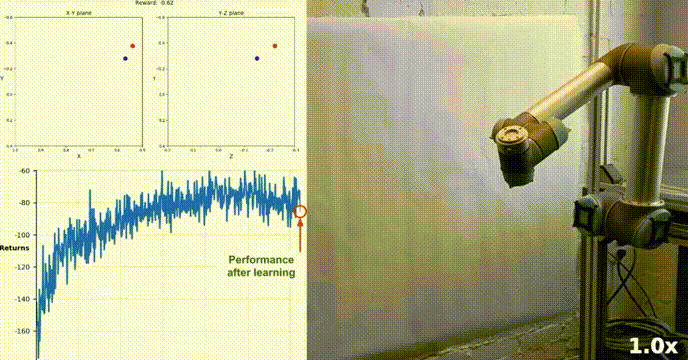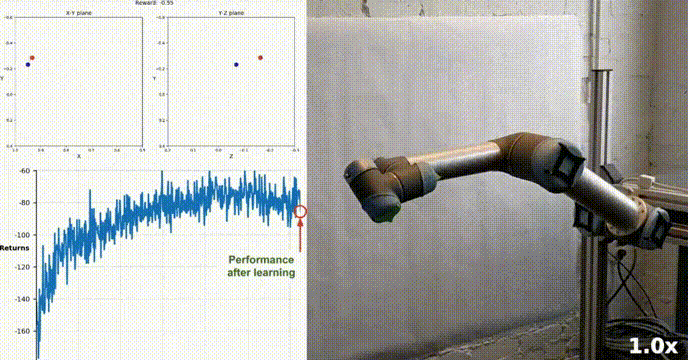
シミュレーション環境
Reacher は Unity ML-Agents ツールキットを使用して構築されており、エージェントは二重関節ロボット アームを制御できます。目標は、アームをターゲット位置に向けてガイドし、ターゲット領域内でその位置をできるだけ長く維持することです。この環境には 20 の同期エージェントがあり、それぞれが独立して実行されるため、トレーニング中の経験を効率的に収集できます。

状態空間とアクション空間
状態空間とアクション空間を理解することは、効果的な強化学習アルゴリズムを設計するために重要です。 Reacher 環境では、状態空間は、ロボット アームの位置、回転、速度、角速度などの情報を提供する 33 の連続変数で構成されます。アクション空間も連続的で、ロボット アームの 2 つの関節にかかるトルクに対応する 4 つの変数があります。各アクション変数は、-1 から 1 までの実数です。
タスク タイプと成功基準
リーチャー タスクは断片化されているとみなされ、各断片には固定数のタイム ステップが含まれます。エージェントの目標は、これらのステップでの合計報酬を最大化することです。アーム エンド エフェクタは、目標位置を維持するために必要なステップごとに 0.1 のボーナスを受け取ります。エージェントが 100 回の連続操作で 30 ポイント以上の平均スコアを達成した場合、成功とみなされます。
環境を理解したところで、DDPG アルゴリズムとその実装、そしてこの環境で継続的な制御の問題を効果的に解決する方法を見てみましょう。
連続制御のためのアルゴリズムの選択: DDPG
リーチャー問題のような連続制御タスクに関しては、アルゴリズムの選択が最適なパフォーマンスを達成するために重要です。このプロジェクトでは、DDPG アルゴリズムを選択しました。これは、DDPG アルゴリズムが連続状態およびアクション空間を処理するために特別に設計されたアクタークリティカル手法であるためです。
DDPG アルゴリズムは、2 つのニューラル ネットワークを組み合わせることで、ポリシー ベースの手法と値ベースの手法の利点を組み合わせています。アクター ネットワークは現在の状態を考慮して最適な動作を決定し、クリティカル ネットワークは状態の動作を推定します。値関数 (Q 関数)。どちらのタイプのネットワークにも、更新プロセス中に固定ターゲットを提供することで学習プロセスを安定させるターゲット ネットワークがあります。
Critic ネットワークを使用して q 関数を推定し、Actor ネットワークを使用して最適な動作を決定することにより、DDPG アルゴリズムはポリシー勾配法と DQN の利点を効果的に組み合わせます。このハイブリッド アプローチにより、エージェントは継続的な制御環境で効率的に学習できます。
<code>import random from collections import deque import torch import torch.nn as nn import numpy as np from actor_critic import Actor, Critic class ReplayBuffer: def __init__(self, buffer_size, batch_size): self.memory = deque(maxlen=buffer_size) self.batch_size = batch_size def add(self, state, action, reward, next_state, done): self.memory.append((state, action, reward, next_state, done)) def sample(self): batch = random.sample(self.memory, self.batch_size) states, actions, rewards, next_states, dones = zip(*batch) return states, actions, rewards, next_states, dones def __len__(self): return len(self.memory) class DDPG: def __init__(self, state_dim, action_dim, hidden_dim, buffer_size, batch_size, actor_lr, critic_lr, tau, gamma): self.actor = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.actor_target = Actor(state_dim, hidden_dim, action_dim, actor_lr) self.critic = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.critic_target = Critic(state_dim, action_dim, hidden_dim, critic_lr) self.memory = ReplayBuffer(buffer_size, batch_size) self.batch_size = batch_size self.tau = tau self.gamma = gamma self._update_target_networks(tau=1)# initialize target networks def act(self, state, noise=0.0): state = torch.tensor(state, dtype=torch.float32).unsqueeze(0) action = self.actor(state).detach().numpy()[0] return np.clip(action + noise, -1, 1) def store_transition(self, state, action, reward, next_state, done): self.memory.add(state, action, reward, next_state, done) def learn(self): if len(self.memory) </code>
上記のコードでは再生バッファーも使用されており、学習効率と安定性を向上させることができます。リプレイ バッファは基本的に、ステータス、アクション、報酬、次のステータス、および完了情報で構成される、一定数の過去のエクスペリエンスまたは遷移を保存するメモリ データ構造です。これを使用する主な利点は、エージェントが連続するエクスペリエンス間の相関関係を解除できるため、有害な時間的相関関係の影響が軽減されることです。
バッファからエクスペリエンスのランダムなミニバッチを引き出すことにより、エージェントはさまざまな変換セットから学習でき、学習プロセスの安定化と一般化に役立ちます。また、リプレイ バッファーを使用すると、エージェントは過去のエクスペリエンスを複数回再利用できるため、データ効率が向上し、環境との限られたインタラクションからより効果的な学習が促進されます。
DDPG アルゴリズムは、この環境では重要な要素である連続アクション スペースを効率的に処理できるため、適切な選択です。アルゴリズムの設計により、複数のエージェントによって収集された並列エクスペリエンスを効率的に利用できるようになり、学習が高速化され、収束が向上します。上で紹介した Reacher と同様に、同時に 20 個のエージェントを実行できるため、この 20 個のエージェントを使用して経験を共有し、まとめて学習し、学習速度を向上させることができます。
アルゴリズムが完了したら、以下にハイパーパラメータの選択とトレーニングのプロセスを紹介します。
DDPG アルゴリズムは Reacher 環境で動作します
環境におけるアルゴリズムの有効性をより深く理解するには、学習プロセスに含まれる主要なコンポーネントと手順を詳しく調べる必要があります。
ネットワーク アーキテクチャ
DDPG アルゴリズムは、Actor と Critic という 2 つのニューラル ネットワークを使用します。どちらのネットワークにも 2 つの隠れ層が含まれており、それぞれに 400 のノードが含まれています。隠れ層は ReLU (Rectified Linear Unit) 活性化関数を使用し、アクター ネットワークの出力層は Tanh 活性化関数を使用して -1 から 1 までの範囲のアクションを生成します。クリティカル ネットワークの出力層には、q 関数を直接推定するため、活性化関数がありません。
次はネットワークのコードです:
<code>import numpy as np import torch import torch.nn as nn import torch.optim as optim class Actor(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim, learning_rate=1e-4): super(Actor, self).__init__() self.fc1 = nn.Linear(input_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, output_dim) self.tanh = nn.Tanh() self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(x)) x = self.tanh(self.fc3(x)) return x class Critic(nn.Module): def __init__(self, state_dim, action_dim, hidden_dim, learning_rate=1e-4): super(Critic, self).__init__() self.fc1 = nn.Linear(state_dim, hidden_dim) self.fc2 = nn.Linear(hidden_dim + action_dim, hidden_dim) self.fc3 = nn.Linear(hidden_dim, 1) self.optimizer = optim.Adam(self.parameters(), lr=learning_rate) def forward(self, state, action): x = torch.relu(self.fc1(state)) x = torch.relu(self.fc2(torch.cat([x, action], dim=1))) x = self.fc3(x) return x</code>
ハイパーパラメータの選択
選択したハイパーパラメータは効率的な学習にとって重要です。このプロジェクトでは、再生バッファーのサイズは 200,000、バッチ サイズは 256 です。 Actor の学習率は 5e-4、Critic の学習率は 1e-3、ソフト アップデート パラメーター (タウ) は 5e-3、ガンマは 0.995 です。最後に、初期ノイズ スケール 0.5、ノイズ減衰率 0.998 でアクション ノイズが追加されました。
トレーニング プロセス
トレーニング プロセスには 2 つのネットワーク間の継続的な対話が含まれ、同じネットワークを共有する 20 の並列エージェントにより、モデルはすべてのエージェントによって収集されたエクスペリエンスから集合的に学習します。この設定により、学習プロセスがスピードアップされ、効率が向上します。
<code>from collections import deque import numpy as np import torch from ddpg import DDPG def train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.1, noise_decay=0.99): scores_window = deque(maxlen=100) scores = [] for episode in range(1, episodes + 1): env_info = env.reset(train_mode=True)[brain_name] states = env_info.vector_observations agent_scores = np.zeros(num_agents) for step in range(max_steps): actions = agent.act(states, noise_scale) env_info = env.step(actions)[brain_name] next_states = env_info.vector_observations rewards = env_info.rewards dones = env_info.local_done for i in range(num_agents): agent.store_transition(states[i], actions[i], rewards[i], next_states[i], dones[i]) agent.learn() states = next_states agent_scores += rewards noise_scale *= noise_decay if np.any(dones): break avg_score = np.mean(agent_scores) scores_window.append(avg_score) scores.append(avg_score) if episode % 10 == 0: print(f"Episode: {episode}, Score: {avg_score:.2f}, Avg Score: {np.mean(scores_window):.2f}") # Saving trained Networks torch.save(agent.actor.state_dict(), "actor_final.pth") torch.save(agent.critic.state_dict(), "critic_final.pth") return scores if __name__ == "__main__": env = UnityEnvironment(file_name='Reacher_20.app') brain_name = env.brain_names[0] brain = env.brains[brain_name] state_dim = 33 action_dim = brain.vector_action_space_size num_agents = 20 # Hyperparameter suggestions hidden_dim = 400 batch_size = 256 actor_lr = 5e-4 critic_lr = 1e-3 tau = 5e-3 gamma = 0.995 noise_scale = 0.5 noise_decay = 0.998 agent = DDPG(state_dim, action_dim, hidden_dim=hidden_dim, buffer_size=200000, batch_size=batch_size,actor_lr=actor_lr, critic_lr=critic_lr, tau=tau, gamma=gamma) episodes = 200 max_steps = 1000 scores = train_ddpg(env, agent, episodes, max_steps, num_agents, noise_scale=0.2, noise_decay=0.995)</code>
トレーニング プロセスの主な手順は次のとおりです。
ネットワークの初期化: エージェントは、共有アクター ネットワークとクリティック ネットワーク、およびそれぞれのターゲット ネットワークをランダムな重みで初期化します。ターゲット ネットワークは、更新中に安定した学習ターゲットを提供します。
- 環境との対話: 各エージェントは、共有アクター ネットワークを使用して、現在の状態に基づいてアクションを選択することで環境と対話します。探索を促進するために、トレーニングの初期段階でアクションにノイズ項も追加されます。アクションを実行した後、各エージェントは結果として得られる報酬と次の状態を観察します。
- エクスペリエンスの保存: 各エージェントは、観察されたエクスペリエンス (状態、アクション、報酬、next_state) を共有リプレイ バッファーに保存します。このバッファには固定量の最近のエクスペリエンスが含まれているため、各エージェントはすべてのエージェントによって収集されたさまざまな遷移から学習できます。
- 経験から学ぶ: 共有リプレイ バッファからエクスペリエンスのバッチを定期的に抽出します。サンプリングの経験を使用して、予測 Q 値とターゲット Q 値の間の平均二乗誤差を最小限に抑えることにより、共有クリティカル ネットワークを更新します。
- アクター ネットワークの更新: 共有アクター ネットワークは、選択したアクションに関する共有クリティック ネットワークの出力勾配を取得することによって計算されるポリシー勾配を使用して更新されます。共有アクター ネットワークは、期待される Q 値を最大化するアクションを選択することを学習します。
- ターゲット ネットワークの更新: 共有アクター ターゲット ネットワークとクリティック ターゲット ネットワークは、現在のネットワークとターゲット ネットワークの重みを組み合わせてソフト更新されます。これにより、安定した学習プロセスが保証されます。
結果表示
私たちのエージェントは、DDPG アルゴリズムを使用して、Racher 環境で二重関節ロボット アームを制御する方法を学習することに成功しました。トレーニング プロセス全体を通じて、20 人のエージェント全員の平均スコアに基づいてエージェントのパフォーマンスを監視します。エージェントが環境を探索して経験を収集すると、報酬を最大化するための最適な行動を予測する能力が大幅に向上します。
エージェントのパフォーマンスにはばらつきがありましたが、平均スコアが環境を解決するために必要なしきい値 (30) を超え、エージェントがタスクにおいてかなりの習熟度を示したことがわかります。全体的にトレーニング プロセス中に差異はありますが、全体的な傾向は上向きであり、学習プロセスが成功していることを示しています。
以下のグラフは、20 人のエージェントの平均スコアを示しています:
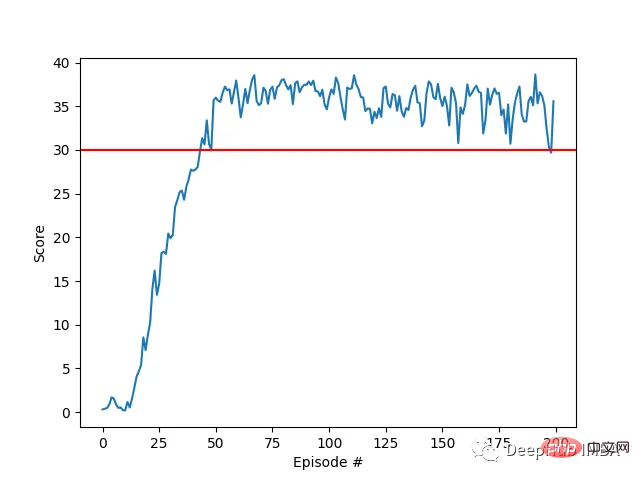
#実装した DDPG アルゴリズムが Racher 環境の問題を効果的に解決したことがわかります。エージェントは自分の動作を調整し、タスクで期待されるパフォーマンスを達成できます。
次のステップ
このプロジェクトのハイパーパラメータは、文献からの推奨事項と経験的テストの組み合わせに基づいて選択されました。システムのハイパーパラメータ調整を通じてさらに最適化すると、パフォーマンスが向上する可能性があります。
マルチエージェントの並行トレーニング: このプロジェクトでは、20 人のエージェントを使用して同時に経験を収集します。より多くのエージェントを使用すると、全体的な学習プロセスに影響が生じ、収束が速くなったり、パフォーマンスが向上したりする可能性があります。
バッチ正規化: 学習プロセスをさらに強化するには、ニューラル ネットワーク アーキテクチャにバッチ正規化を実装することを検討する価値があります。バッチ正規化は、トレーニング中に各層の入力特徴を正規化することで、内部共変量シフトを軽減し、学習を高速化し、一般化を向上させる可能性があります。 Actor ネットワークと Critic ネットワークにバッチ正規化を追加すると、より安定した効率的なトレーニングが得られる可能性がありますが、これにはさらなるテストが必要です。
以上がActor-Critic の DDPG 強化学習アルゴリズムを使用した二重関節ロボット アームの制御の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。