


人間の感覚では、写真はさまざまな経験を融合させることができます。たとえば、ビーチの写真は、波の音、砂の質感、顔に吹く風を思い出させ、インスピレーションを刺激することさえあります。詩のために。画像のこの「結合」特性は、視覚的特徴をそれに関連する感覚経験と一致させることにより、視覚的特徴を学習するための大きな監督源となります。
理想的には、単一の関節埋め込み空間に対してすべての感覚を調整することで視覚的特徴を学習する必要があります。ただし、これには、同じ画像セットからすべての感覚タイプおよび組み合わせのペアデータを取得する必要がありますが、これは明らかに実現可能ではありません。
最近では、テキストや音声などに合わせて画像の特徴を学習する手法が多くなっています。これらの方法では、単一のモダリティ ペア、または最大でも複数の視覚モダリティが使用されます。最終的な埋め込みは、トレーニングに使用されるモダリティ ペアに限定されます。したがって、ビデオとオーディオの埋め込みを画像とテキストのタスクに直接使用することはできず、その逆も同様です。真の関節埋め込みを学習する際の主な障害は、すべてのモダリティが融合された大量のマルチモーダル データが不足していることです。
本日、Meta AI は、複数種類の画像ペア データを活用して単一の共有表現空間を学習する ImageBind を提案しました。この研究では、すべてのモダリティが同時に現れるデータ セットは必要ありません。代わりに、画像の結合特性を利用します。各モダリティの埋め込みが画像の埋め込みと一致している限り、すべてのモダリティは を揃えます。メタAIも対応コードを発表した。

- 文書アドレス: https://dl.fbaipublicfiles.com /imagebind/imagebind_final.pdf
- GitHub アドレス: https://github.com/facebookresearch/ImageBind
- 具体的には、ImageBind はネットワーク スケール (画像、テキスト) のマッチング データを利用し、それを自然に発生するペア データ (ビデオ、オーディオ、画像、深度) とペアにします。単一の関節埋め込み空間を学習するために結合されます。これにより、ImageBind はテキスト埋め込みを他のモダリティ (オーディオ、深度など) と暗黙的に調整できるようになり、明示的なセマンティックやテキストのペアリングを行わずに、これらのモダリティでのゼロショット認識が可能になります。
 #下の図 2 は、ImageBind の全体概要を示しています。
#下の図 2 は、ImageBind の全体概要を示しています。
同時に研究者らは、ImageBind は大規模なビジュアル言語モデル (CLIP など) を使用して初期化できるため、これらのモデルの豊富な画像とテキスト表現。したがって、ImageBind はトレーニングをほとんど必要とせず、さまざまなモダリティやタスクに適用できます。 
ImageBind は、関連するすべての種類のデータから学習するマルチモーダル AI システムを作成するという Meta の取り組みの一環です。モダリティの数が増えるにつれ、ImageBind は研究者が 3D センサーと IMU センサーを組み合わせて没入型の仮想世界を設計または体験するなど、新しい総合的なシステムの開発を試みるための水門を開きます。また、テキスト、ビデオ、画像を組み合わせて画像、ビデオ、オーディオ ファイル、またはテキスト情報を検索することで、記憶を探索する豊富な方法も提供します。
コンテンツと画像をバインドし、単一の埋め込みスペースを学習する
人間には、動物の説明を読んだ後など、非常に少ないサンプルを通じて新しい概念を学習する能力があります。実際にそれらを認識することができ、見慣れない車種の写真から、そのエンジンが発するであろう音を予測することができます。これは、1 つの画像が全体的な感覚体験を「束ねる」ことができるためでもあります。しかし、人工知能の分野では、モダリティの数は増加しているものの、多感覚データの不足により、ペアデータを必要とする標準的なマルチモーダル学習が制限されます。理想的には、異なるタイプのデータを含む共同埋め込み空間により、モデルが視覚的特徴を学習しながら他のモダリティを学習できるようになります。以前は、すべてのモダリティが結合埋め込み空間を学習するには、考えられるすべてのペアごとのデータの組み合わせを収集する必要があることがよくありました。
ImageBind は、最近の大規模視覚言語モデルを活用することでこの難題を回避し、最近の大規模視覚言語モデルのゼロショット機能を画像に関連する新しいモダリティに拡張します。ビデオとオーディオ、画像と深度データなどの自然なペアリングにより、結合埋め込み空間を学習します。他の 4 つのモダリティ (音声、深度、熱画像、IMU 測定値) については、研究者らは自然にペアになった自己教師ありデータを使用しました。
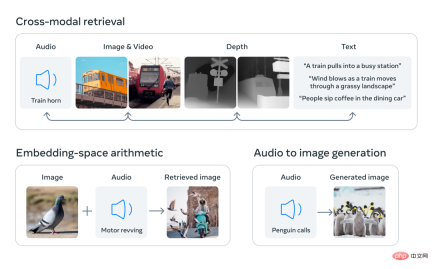
#6 つのモダリティの埋め込みを共通空間に配置することで、ImageBind同時に観察されないさまざまなタイプのコンテンツをクロスモーダルに取得し、さまざまなモダリティの埋め込みを追加してセマンティクスを自然に組み合わせ、Meta AI のオーディオ埋め込みを事前トレーニング済みの DALLE-2 デコーダ (CLIP テキスト埋め込みで使用されるように設計) と使用して実装できます。音声から画像への生成。
#インターネット上にはテキストとともに大量の画像が表示されるため、画像テキスト モデルのトレーニングが広く研究されています。 ImageBind は、ネットワーク データを使用してテキストを画像に接続したり、IMU センサーを備えたウェアラブル カメラでキャプチャされたビデオ データを使用してモーションをビデオに接続したりするなど、さまざまなモダリティに接続できる画像のバインディング プロパティを利用します。大規模なネットワーク データから学習した視覚表現は、さまざまなモーダル特徴を学習するためのターゲットとして使用できます。これにより、ImageBind は、同時に存在する任意のモダリティと画像を位置合わせし、それらのモダリティを自然に互いに位置合わせすることができます。ヒート マップやデプス マップなど、画像との相関性が高いモダリティは位置合わせが容易です。オーディオや IMU (慣性測定装置) などの非視覚的モダリティは相関が弱く、たとえば、赤ちゃんの泣き声などの特定の音は、さまざまな視覚的背景と一致する可能性があります。
ImageBind は、画像ペアリング データがこれら 6 つのモダリティを結合するのに十分であることを示します。このモデルはコンテンツをより完全に説明できるため、異なるモダリティが相互に「対話」し、それらを同時に観察することなくそれらの間の接続を見つけることができます。たとえば、ImageBind はオーディオとテキストを一緒に観察することなくリンクできます。これにより、他のモデルは、リソースを大量に消費するトレーニングを必要とせずに、新しいモダリティを「理解」できるようになります。
ImageBind の強力なスケーリング パフォーマンスにより、このモデルは多くの人工知能モデルを置き換えたり強化したりして、他のモダリティを使用できるようになります。たとえば、Make-A-Scene はテキスト プロンプトを使用して画像を生成できますが、ImageBind はそれをアップグレードして、笑い声や雨の音などの音声を使用して画像を生成できます。
ImageBind の優れたパフォーマンス
Meta の分析では、ImageBind のスケーリング動作が画像エンコーダーの強度によって向上することが示されています。言い換えれば、モダリティを調整する ImageBind の機能は、ビジュアル モデルの能力とサイズに応じて調整されます。これは、より大きな視覚モデルが音声分類などの非視覚タスクに有益であり、そのようなモデルをトレーニングする利点がコンピューター ビジョン タスクを超えて広がることを示唆しています。実験では、Meta は ImageBind のオーディオおよび深度エンコーダーを使用し、ゼロショット検索およびオーディオおよび深度分類タスクに関する以前の研究と比較しました。
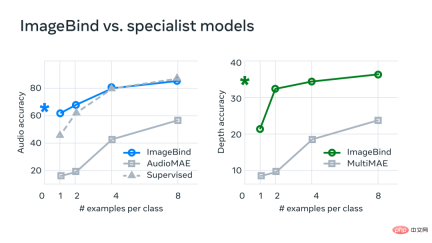
Meta は、ImageBind が数ショットの音声タスクや詳細な分類タスクに使用でき、以前のカスタム メソッドよりも優れたパフォーマンスを発揮できることを発見しました。たとえば、ImageBind は、Audioset でトレーニングされた Meta の自己教師あり AudioMAE モデルや、音声分類で微調整された教師あり AudioMAE モデルよりも大幅に優れています。
さらに、ImageBind は、クロスモーダルのゼロショット認識タスクで新しい SOTA パフォーマンスを達成し、そのモダリティで概念を認識するようにトレーニングされた最先端のモデルさえも上回ります。
以上が画像を使用してすべてのモダリティを調整し、優れた統合を実現するメタ オープンソースの多感覚 AI 基本モデルの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 ロボット工学者になる方法は?Apr 15, 2025 am 09:41 AM
ロボット工学者になる方法は?Apr 15, 2025 am 09:41 AMロボット工学:急速に拡大するフィールドでのやりがいのあるキャリアパス ロボット工学の分野は、爆発的な成長を経験しており、多くのセクターにわたって革新を促進し、日常生活を送っています。 自動製造から医療ロボットや自動運転車まで、
 Excelで複製を削除する方法は? - 分析VidhyaApr 15, 2025 am 09:20 AM
Excelで複製を削除する方法は? - 分析VidhyaApr 15, 2025 am 09:20 AMデータの整合性:正確な分析のためにExcelで重複を削除します クリーンデータは、効果的な意思決定には非常に重要です。 Excelスプレッドシートの複製エントリは、エラーや信頼できない分析につながる可能性があります。このガイドは、DUPを簡単に削除する方法を示しています
 トップ10の電話インタビューのヒント - 分析VidhyaApr 15, 2025 am 09:19 AM
トップ10の電話インタビューのヒント - 分析VidhyaApr 15, 2025 am 09:19 AM電話インタビューの芸術をマスターする:成功へのあなたのガイド 電話インタビューを成功させると、求人プロセスの次の段階に進む可能性が大幅に増加する可能性があります。 この重要な第一印象は、多くの場合唯一のfacです
 統計学者になる方法は?Apr 15, 2025 am 09:15 AM
統計学者になる方法は?Apr 15, 2025 am 09:15 AM導入 ヘルスケア、金融、スポーツなどの分野で自分とあなたの会社のために情報に基づいた決定を下す力を持っていることを想像してください。それが統計学者の役割です。 組織でのデータの使用の増加に伴い、統計学者の需要
 AIはどのように機能しますか? - 分析VidhyaApr 15, 2025 am 09:14 AM
AIはどのように機能しますか? - 分析VidhyaApr 15, 2025 am 09:14 AM人工知能:包括的なガイド テクノロジーにより、マシンが私たちの好みを理解し、私たちのニーズを予測し、過去の相互作用から学び、より良い結果を提供する世界を想像することができました。これはサイエンスフィクションではありません。その
 Pictogramグラフとは何ですか? - 分析VidhyaApr 15, 2025 am 09:09 AM
Pictogramグラフとは何ですか? - 分析VidhyaApr 15, 2025 am 09:09 AM導入 データ分析の世界では、効果的なコミュニケーションが重要です。 Pictogramグラフは強力なソリューションを提供し、視覚的に魅力的で簡単に消化可能な形式で情報を提示します。複雑なチャートや図、絵文字も異なります
 llama-3.1-storm-8b:8b LLMはメタとエルメスを上回るApr 15, 2025 am 09:08 AM
llama-3.1-storm-8b:8b LLMはメタとエルメスを上回るApr 15, 2025 am 09:08 AMLlama 3.1 Storm 8b:効率的な言語モデルのブレークスルー 効率的で正確な言語モデルの追求により、80億パラメーターモデルカテゴリの大幅な進歩であるLlama 3.1 Storm 8Bの開発が発生しました。 これは洗練されています
 Gitのインストール方法は? - 分析VidhyaApr 15, 2025 am 09:07 AM
Gitのインストール方法は? - 分析VidhyaApr 15, 2025 am 09:07 AMGit:バージョン制御とコラボレーションへの本質的なガイド GITは、開発者にとって重要なツールであり、プロジェクトのコラボレーションとバージョン制御を簡素化します。 このガイドは、Linux、MacOS、およびWindにGitをインストールするための簡単な手順を提供します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

ドリームウィーバー CS6
ビジュアル Web 開発ツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

WebStorm Mac版
便利なJavaScript開発ツール

