
ホームページ >Java >&#&チュートリアル >Java マルチスレッドは CompletableFuture を通じて非同期コンピューティング ユニットをどのように組み立てるのでしょうか?
Java マルチスレッドは CompletableFuture を通じて非同期コンピューティング ユニットをどのように組み立てるのでしょうか?

- 王林転載
- 2023-05-11 19:04:041319ブラウズ
CompletableFuture の概要
CompletableFuture は 1.8 で導入された新機能で、より複雑な非同期コンピューティング シナリオ、特に複数の非同期コンピューティングを必要とするシナリオに使用されます。ユニットを直列に接続する場合は、CompletableFuture を使用して実装することを検討できます。
現実の世界では、解決する必要がある複雑な問題はいくつかのステップに分かれています。私たちのコードと同様に、複雑な論理メソッドでは、それを段階的に実装するために複数のメソッドが呼び出されます。
次のシナリオを想像してください。植樹祭は次のステップに分かれて行われます。
10 分間穴を掘ります
5 分間苗木を入手
20 分間苗木を植える
5 分間水やり
このうち 1 と 2 は並行して実行できますが、1 と 2 の両方が完了してからステップ 3 を完了し、その後ステップ 4 を実行できます。
次のような実装方法があります。
1 人だけが木を植える
今、木を植えている人が 1 人だけで、100 本の木を植える場合、次のようになります。順序は実行のみに従うことができます:
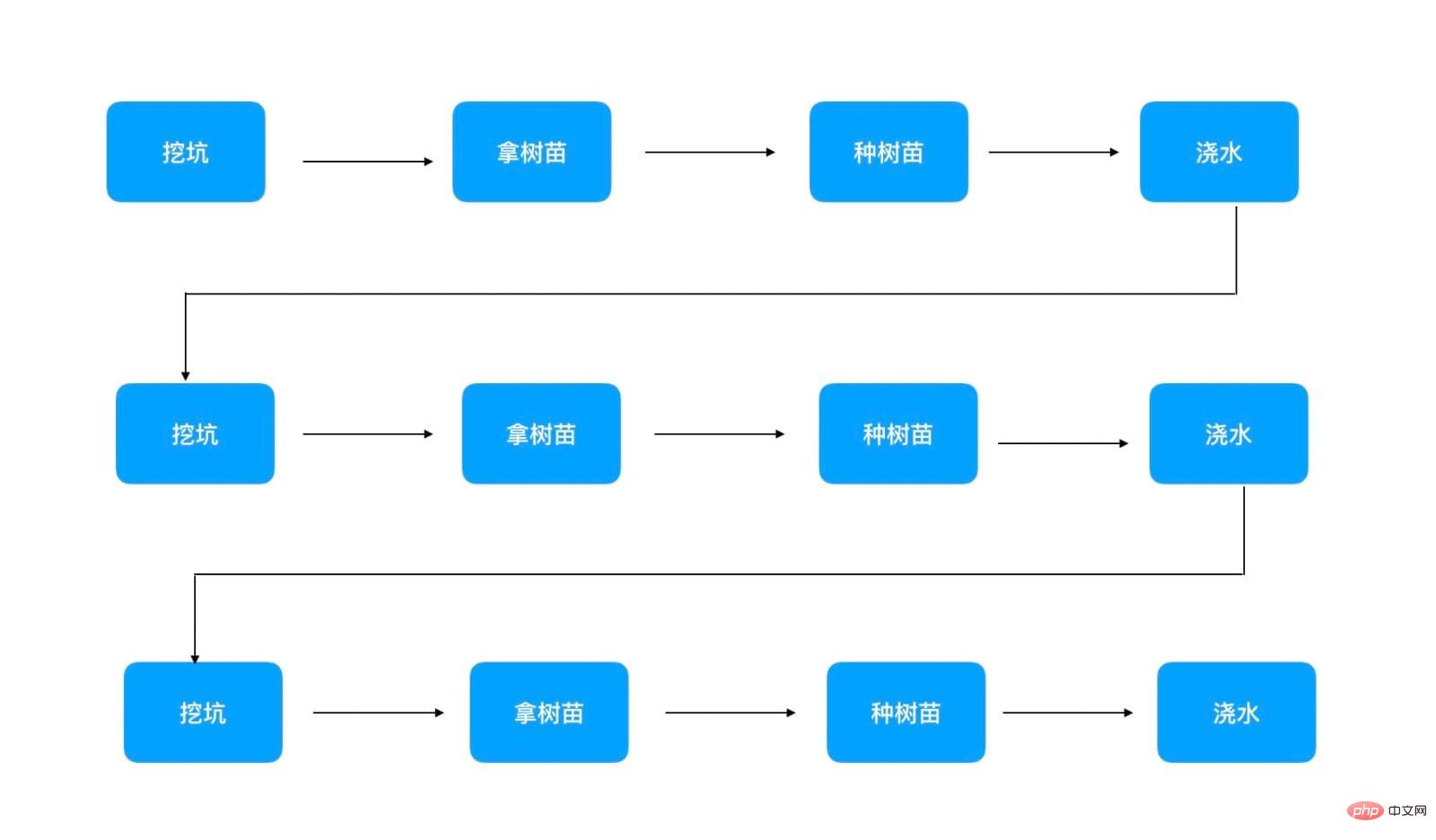
#図には 3 つの木だけが表示されています。シリアル実行では、1 つの木を植えてから別の木しか植えることができないため、100 本の木を植えるには 40 * 100 = 4000 分 かかることがわかります。このメソッドは、シングルスレッド同期実行のプログラムに対応します。
3 人が同時に植樹します。各自が植樹を担当します。
植樹の時間を短縮するにはどうすればよいですか?これは簡単ではないと思われるかもしれませんが、私にとってこれは、長い間並行性について研究してきたので、決して問題ではありません。 100本の木を植えてみませんか?それから私は一緒に植えてくれる100人を見つけて、それぞれが木を植えます。 100 本の木を植えるのにかかる時間はわずか 40 分です。
はい、プログラムに plantTree というメソッドがあり、上記の 4 つの部分が含まれている場合は、100 個のスレッドを作成するだけで済みます。ただし、100 個のスレッドの作成と破棄はシステム リソースを大量に消費することに注意してください。また、スレッドの作成と破棄には時間がかかります。さらに、CPU のコア数では、実際には 100 スレッドを同時にサポートできません。 10,000 本の木を植えたい場合はどうすればよいでしょうか?スレッドを 10,000 個にすることはできませんね。
つまり、これは単なる理想的な状況であり、通常はスレッド プールを通じて実行し、実際に 100 個のスレッドを開始することはありません。
複数の人が同時に植樹します
それぞれの木を植えるとき、独立した手順を別の人が並行して行うことができます
この方法により、植樹時間をさらに短縮できます植え付け 穴を掘る第1段階と苗木を採取する第2段階は2人で並行して行えるため、1本の木にかかる時間はわずか35分です。以下に示すように:
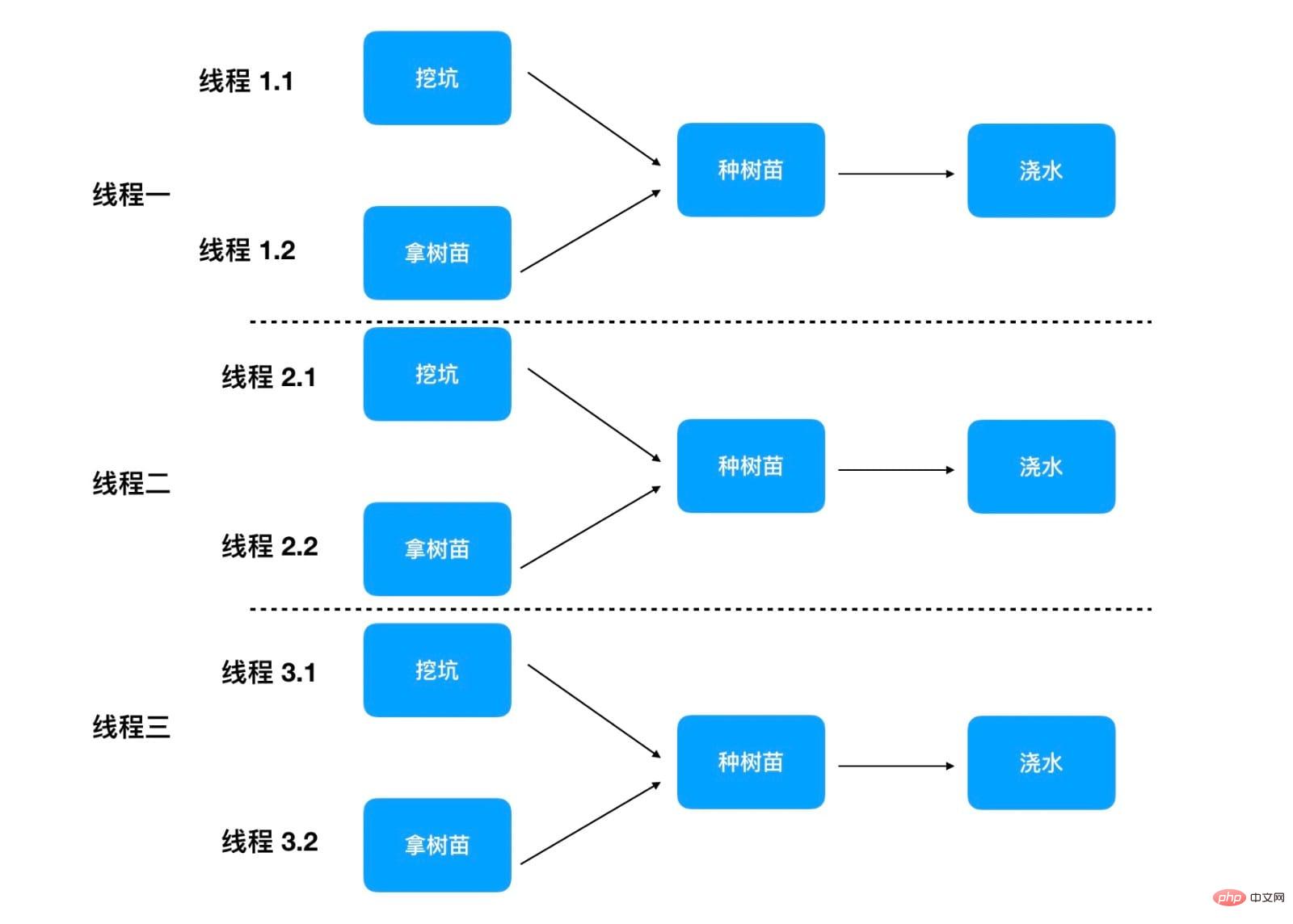
#プログラムで plantTree メソッドを同時に実行するメイン スレッドが 100 個ある場合、100 本の木を植えるのにかかる時間はわずか 35 分です。ここでは、ステップ 1 と 2 を同時に実行する 2 つのスレッドがあるため、各スレッドに注意する必要があります。実際の運用では、100 x 3 = 300 のスレッドが植樹に参加します。ただし、ステップ 1 と 2 を担当するスレッドは一時的にのみ参加し、その後アイドル状態になります。
この方法と 2 番目の方法にも、大量のスレッドが作成されるという問題があります。したがって、それはまさに理想的な状況です。
木を植えている人が 4 人だけの場合、各人は自分のステップにのみ責任を負います
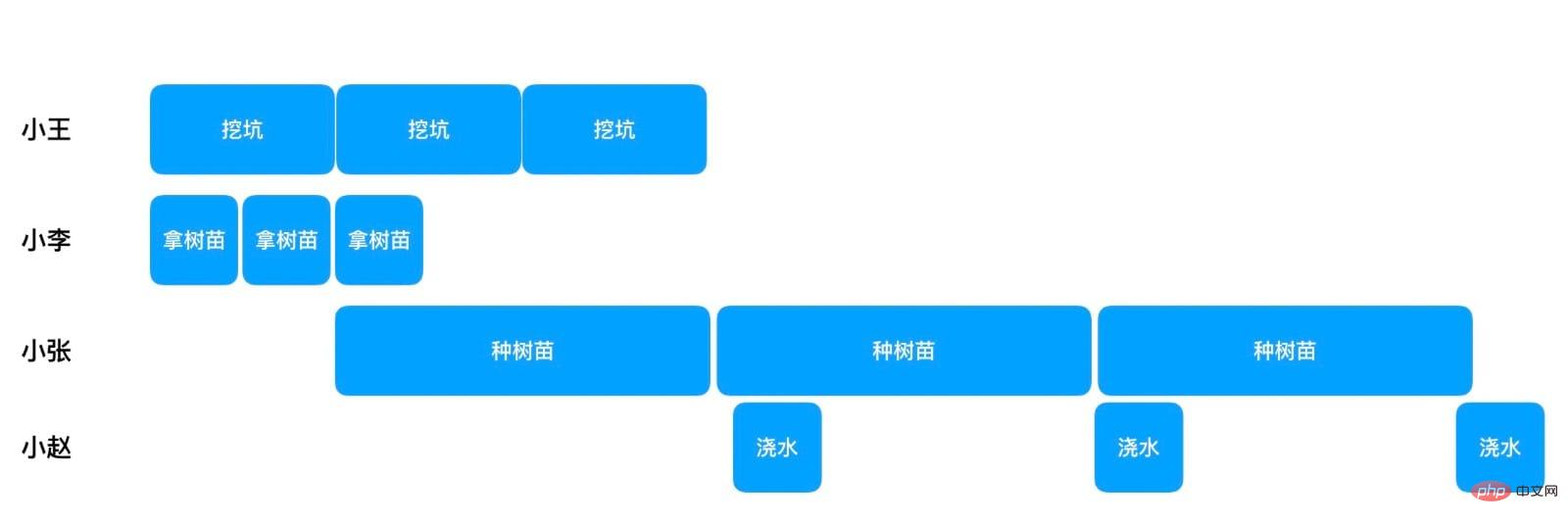
シャオ ワンが最初の穴を掘った後にそれがわかります。最初、Xiao Wang Li は 2 本の苗木を回収しましたが、今度は Xiao Zhang が最初の苗木の植え付けを開始できるようになりました。それ以降、Xiao Zhang は苗木を 1 本ずつ植えることができ、苗木を植えるときに並行して水やりを行うことができます。このプロセスに従うと、100 本の苗木を植えるには 10 20x100 5=2015 分かかります。これは、単一スレッドの 4000 分よりははるかに優れていますが、100 個のスレッドが同時に木を植える速度にははるかに劣ります。ただし、100 スレッドの同時実行は理想的な状況にすぎず、この方法では 4 つのスレッドしか使用しないことを忘れないでください。
役割分担を少し調整しましょう。誰もが自分の仕事をするだけでなく、自分の仕事が終わったら、他にできる仕事はないかを考えます。たとえば、シャオ・ワンが穴を掘って苗木を植えられることがわかったら、苗木を植えます。シャオ・リーは苗木を採取し終わった後、穴を掘ったり、苗木を植えたりすることもできます。このようにして、全体的な効率が高くなります。この考えに基づくと、実際にはタスクを 4 つのカテゴリに分け、各カテゴリに 100 個のタスクがあり、合計 400 個のタスクになります。 400 個のタスクがすべて完了すると、タスク全体が完了したことになります。そうすれば、タスクの参加者はタスクの依存関係を知るだけで済み、その後は実行可能なタスクを継続的に受け取り、実行することができます。この効率が最も高くなります。
前述したように、100 個のスレッドでタスクを同時に実行することは不可能なので、通常の状況ではスレッド プールを使用します。これは上記の設計思想と一致します。スレッド プールを使用した後、4 番目の方法ではステップがより詳細に分割され、同時実行の可能性が高まります。したがって、速度は 2 番目の方法よりも速くなります。では、3 番目のタイプと比較して、どちらが速いのでしょうか?スレッドの数が無限である場合、これら 2 つの方法で達成できる最小時間は同じ 35 分です。ただし、スレッドが制限されている場合は、4 番目の方法の方がスレッドの使用率が高くなります。これは、各ステップを並行して実行できるため (植樹に参加する人は、作業が完了した後に他の人を手伝うことができます)、スレッドのスケジュールがより柔軟であるためです。スレッド プール内のスレッドはアイドル状態になり、実行し続けることが困難になります。そう、怠ける人はいないのです。 3 番目の方法は、plantTree メソッドで同時に使用できるのは、穴を掘って苗木を採取することだけであるため、4 番目の方法ほど柔軟性がありません。
これまで述べてきたのは、主に理由を説明するためです。 CompletableFutureの登場。これは、複雑なタスクを接続された非同期実行ステップに分割するために使用され、それによって全体の効率が向上します。このセクションのトピックに戻りましょう。誰も怠けることはできません。はい、これが CompletableFuture の目標です。コンピューティング ユニットを抽象化することで、スレッドは各ステップに効率的かつ同時に参加できるようになります。同期コードは、CompletableFuture を通じて非同期コードに完全に変換できます。 CompletableFuture の使い方を見てみましょう。
CompletableFuture は、
CompletableFuture を使用します。CompletableFuture は、Future インターフェイスを実装し、CompletionStage インターフェイスを実装します。 Future インターフェイスにはすでに慣れており、CompletionStage インターフェイスは非同期計算ステップ間の仕様を設定して、ステップごとに接続できるようにします。 CompletionStage は、非同期計算ステップ間を接続するための 38 個のパブリック メソッドを定義します。次に、一般的に使用され、比較的頻繁に使用されるメソッドをいくつか選択し、その使用方法を見ていきます。
既知の計算結果
CompletableFuture の計算結果がすでにわかっている場合は、静的メソッド completedFuture を使用できます。計算結果を渡し、CompletableFuture オブジェクトを宣言します。 get メソッドが呼び出されると、次のコードに示すように、受信した計算結果はブロックされずにすぐに返されます。
public static void main(String[] args) throws Exception{
CompletableFuture<String> completableFuture = CompletableFuture.completedFuture("Hello World");
System.out.println("result is " + completableFuture.get());
}
// result is Hello Worldこの使用法は無意味だと思いますか?計算結果がわかったので、それを直接使用するだけですが、なぜ CompletableFuture でパッケージ化する必要があるのでしょうか?これは、非同期コンピューティング ユニットを CompletableFuture 経由で接続する必要があるため、計算結果がすでにわかっている場合でも、それを CompletableFuture にパッケージ化して非同期コンピューティング プロセスに統合する必要がある場合があります。
戻り値を使用した非同期計算ロジックのカプセル化
これは、最も一般的に使用される方法です。非同期計算を必要とするロジックを計算ユニットにカプセル化し、それを CompletableFuture に渡して実行します。次のコードのように:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成ここでは、CompletableFuture の SupplyAsync メソッドを使用し、ラムダ式の形式でサプライヤー インターフェイスの実装を渡します。
completableFuture.get() 得られる計算結果は、渡した関数の実行後に返される値であることがわかります。非同期計算を必要とするロジックがある場合は、supplyAsync によって渡される関数本体にそれを含めることができます。この関数はどのように非同期で実行されるのでしょうか?コードに従うと、supplyAsync が実際にスレッド プールである Executor を通じてこの関数を実行していることがわかります。 completableFuture は、デフォルトで ForkJoinPool を使用します。もちろん、supplyAsync に他の Excutor を指定し、それを 2 番目のパラメーターを通じて SupplyAsync メソッドに渡すこともできます。
supplyAsync は多くのシナリオで使用されます。簡単な例を挙げると、メイン プログラムはデータを要求するために複数のマイクロサービスのインターフェイスを呼び出す必要があります。その後、複数の CompletableFuture を開始して、supplyAsync を呼び出すことができます。関数本体はほぼ異なります。インターフェイス、呼び出しロジック。このようにして、さまざまなインターフェイス要求を非同期かつ同時に実行でき、最終的にすべてのインターフェイスが返されたときに、後続のロジックが実行されます。
戻り値なしの非同期計算ロジックをカプセル化する
supplyAsync によって受け取られた関数には戻り値があります。場合によっては、単なる計算プロセスであり、値を返す必要がありません。これは、値を返さない Runnable の run メソッドに似ています。この場合、次のコードのような runAsync メソッドを使用できます。
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> System.out.println("挖坑完成"));
completableFuture.get();
}
// 挖坑完成runAsync は、実行可能インターフェイスの関数を受け取ります。したがって、戻り値はありません。 Chestnut のロジックは「Digming completed」を出力するだけです。
非同期で返された結果をさらに処理し、新しい計算結果を返す
supplyAsync を通じて非同期計算を完了し、CompletableFuture を返すと、以下に示すように、この時点で返された結果の処理を続行できます。コード:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenApply(s -> s + ", 并且归还铁锹")
.thenApply(s -> s + ", 全部完成。");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 并且归还铁锹, 全部完成。supplyAsync を呼び出した後、thenApply メソッドを 2 回連鎖呼び出しします。 s は、前の手順で SupplyAsync によって返された計算結果です。計算結果を 2 回再処理しました。 thenApply を通じて計算結果を継続的に処理できます。 thenApply のロジックを非同期で実行する場合は、thenApplyAsync を使用できます。使用方法は同じですが、スレッド プールを通じて非同期で実行されます。
进一步处理异步返回的结果,无返回
这种场景你可以使用thenApply。这个方法可以让你处理上一步的返回结果,但无返回值。参照如下代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenAccept(s -> System.out.println(s + ", 并且归还铁锹"));
completableFuture.get();
}这里可以看到 thenAccept 接收的函数没有返回值,只有业务逻辑。处理后返回 CompletableFuture 类型对象。
既不需要返回值,也不需要上一步计算结果,只想在执行结束后再执行一段代码
此时你可以使用 thenRun 方法,他接收 Runnable 的函数,没有输入也没有输出,仅仅是在异步计算结束后回调一段逻辑,比如记录 log 等。参照下面代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenAccept(s -> System.out.println(s + ", 并且归还铁锹"))
.thenRun(() -> System.out.println("挖坑工作已经全部完成"));
completableFuture.get();
}
// 挖坑完成, 并且归还铁锹
// 挖坑工作已经全部完成可以看到在 thenAccept 之后继续调用了 thenRun,仅仅是打印了日志而已
组合 Future 处理逻辑
我们可以把两个 CompletableFuture 组合起来使用,如下面的代码:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenCompose(s -> CompletableFuture.supplyAsync(() -> s + ", 并且归还铁锹"));
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 并且归还铁锹thenApply 和 thenCompose 的关系就像 stream中的 map 和 flatmap。从上面的例子来看,thenApply 和thenCompose 都可以实现同样的功能。但是如果你使用一个第三方的库,有一个API返回的是CompletableFuture 类型,那么你就只能使用 thenCompose方法。
组合Futurue结果
如果你有两个异步操作互相没有依赖,但是第三步操作依赖前两部计算的结果,那么你可以使用 thenCombine 方法来实现,如下面代码:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> "挖坑完成")
.thenCombine(CompletableFuture.supplyAsync(() -> ", 拿树苗完成"), (x, y) -> x + y + "植树完成");
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑完成, 拿树苗完成植树完成挖坑和拿树苗可以同时进行,但是第三步植树则祖尧前两步完成后才能进行。
可以看到符合我们的预期。使用场景之前也提到过。我们调用多个微服务的接口时,可以使用这种方式进行组合。处理接口调用间的依赖关系。 当你需要两个 Future 的结果,但是不需要再加工后向下游传递计算结果时,可以使用 thenAcceptBoth,用法一样,只不过接收的函数没有返回值。
并行处理多个 Future
假如我们对微服务接口的调用不止两个,并且还有一些其它可以异步执行的逻辑。主流程需要等待这些所有的异步操作都返回时,才能继续往下执行。此时我们可以使用 CompletableFuture.allOf 方法。它接收 n 个 CompletableFuture,返回一个 CompletableFuture。对其调用 get 方法后,只有所有的 CompletableFuture 全完成时才会继续后面的逻辑。我们看下面示例代码:
public static void main(String[] args) throws Exception {
CompletableFuture<Void> future1 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("挖坑完成");
});
CompletableFuture<Void> future2 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("取树苗完成");
});
CompletableFuture<Void> future3 = CompletableFuture.runAsync(() -> {
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("取肥料完成");
});
CompletableFuture.allOf(future1, future2, future3).get();
System.out.println("植树准备工作完成!");
}
// 挖坑完成
// 取肥料完成
// 取树苗完成
// 植树准备工作完成!异常处理
在异步计算链中的异常处理可以采用 handle 方法,它接收两个参数,第一个参数是计算及过,第二个参数是异步计算链中抛出的异常。使用方法如下:
public static void main(String[] args) throws Exception {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
if (1 == 1) {
throw new RuntimeException("Computation error");
}
return "挖坑完成";
}).handle((result, throwable) -> {
if (result == null) {
return "挖坑异常";
}
return result;
});
System.out.println("result is " + completableFuture.get());
}
// result is 挖坑异常代码中会抛出一个 RuntimeException,抛出这个异常时 result 为 null,而 throwable 不为null。根据这些信息你可以在 handle 中进行处理,如果抛出的异常种类很多,你可以判断 throwable 的类型,来选择不同的处理逻辑。
以上がJava マルチスレッドは CompletableFuture を通じて非同期コンピューティング ユニットをどのように組み立てるのでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。