
ホームページ >テクノロジー周辺機器 >AI >トランスフォーマー レビュー: BERT から GPT4 へ
トランスフォーマー レビュー: BERT から GPT4 へ

- 王林転載
- 2023-05-10 23:25:041385ブラウズ
人工知能は近年最も話題になっているトピックの 1 つであり、かつては純粋に SF の話だと考えられていたサービスが、ニューラル ネットワークの開発により現実のものになりつつあります。会話エージェントからメディア コンテンツ生成まで、人工知能は私たちがテクノロジーと対話する方法を変えています。特に、機械学習 (ML) モデルは、自然言語処理 (NLP) の分野で大きな進歩を遂げました。重要なブレークスルーは、シーケンス処理のための「セルフアテンション」とトランスフォーマー アーキテクチャの導入であり、これにより、以前はこの分野を支配していたいくつかの重要な問題が解決できるようになりました。
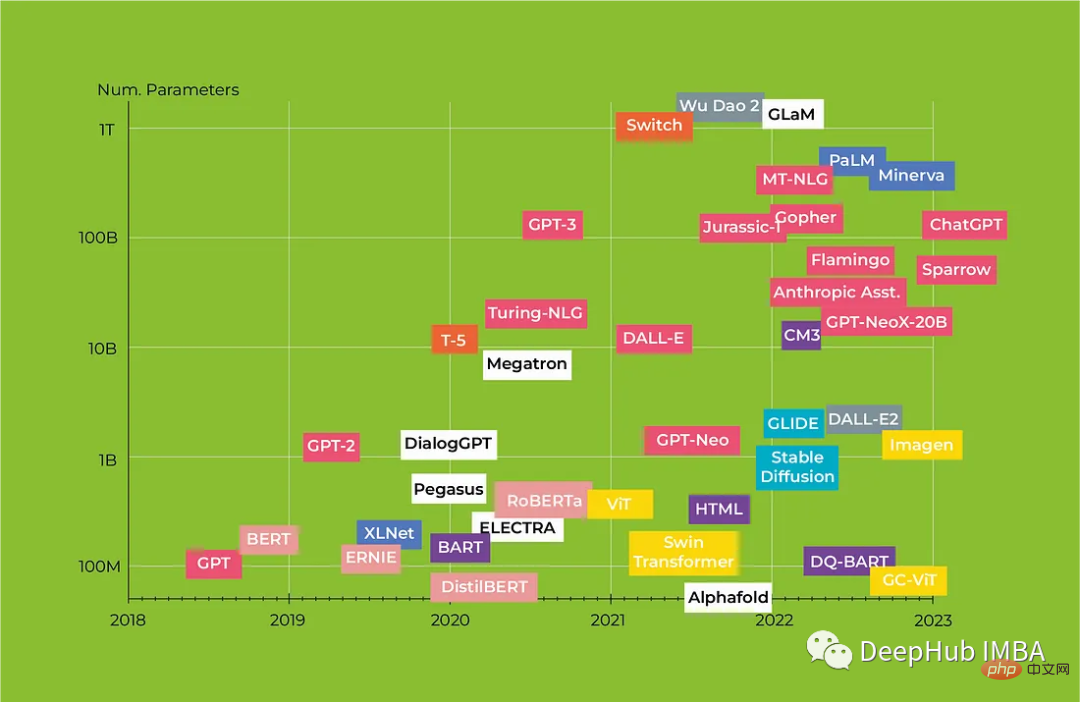
この記事では、革新的な Transformers アーキテクチャと、それが NLP にどのような変化をもたらしているかを見ていきます。また、Transformers の包括的なレビューも取り上げます。 BERT から Alpaca モデルまでを紹介し、各モデルの主な特徴とその潜在的な用途を強調します。
Bert 風のテキスト モデル
最初の部分は、ベクトル化、分類、シーケンスのラベル付け、QA (質問と回答)、NER (名前付き) に使用される Transformer エンコーダーに基づくモデルです。エンティティ認識)など
1. BERT Google / 2018
トランスフォーマー エンコーダー、単語単位のトークン化 (30,000 語彙)。入力埋め込みは、ラベル ベクトル、トレーニング可能な位置ベクトル、フラグメント ベクトル (第 1 テキストまたは第 2 テキスト) の 3 つのベクトルで構成されます。モデルの入力は、CLS トークンの埋め込み、最初のテキストの埋め込み、および 2 番目のテキストの埋め込みです。
BERT には、マスク言語モデリング (MLM) と次文予測 (NSP) という 2 つのトレーニング タスクがあります。 MLM では、トークンの 15% がマスクされ、80% が MASK トークンに置き換えられ、10% がランダム トークンに置き換えられ、10% は変更されません。モデルは正しいトークンを予測し、損失はブロックされたトークンの 15% についてのみ計算されます。 NSP では、モデルは 2 番目のテキストが最初のテキストに続くかどうかを予測します。予測は CLS トークンの出力ベクトルに対して行われます。
トレーニングを高速化するために、最初の 90% のトレーニングは 128 トークンのシーケンス長で実行され、残りの 10% の時間は、より効果的な位置埋め込みを取得するために 512 トークンでのモデルのトレーニングに費やされます。 。
2、RoBERTa Facebook / 2019
BERT の改良版。MLM でのみトレーニングされ (NSP はあまり有用ではないと考えられているため)、トレーニング シーケンスは長くなります (512 トークン)。動的マスキング (同じデータが再度処理されるときに異なるトークンがマスクされる) を使用して、トレーニング ハイパーパラメーターが慎重に選択されます。
3.オリジナルの XLM では、すべての言語に共通の BPE 語彙がありました。
#XLM には、MLM と翻訳という 2 つのトレーニング タスクがあります。翻訳は基本的に 1 対のテキストに対する MLM と同じですが、テキストはランダム マスクとセグメント埋め込みエンコード言語を使用して相互に並行翻訳されます。 4. Transformer-XL カーネギーメロン大学 / 2019このモデルは長いシーケンスを処理するように設計されており、フラグメントのループ処理と相対位置エンコーディングという 2 つの主なアイデアがあります。 長いテキストはセグメントに分割され、一度に 1 セグメントずつ処理されます。前のセグメントの出力はキャッシュされ、現在のセグメントでセルフ アテンションを計算するときに、現在のセグメントと前のセグメント (単に連結されただけ) の出力に基づいてキーと値が計算されます。勾配も現在のセグメント内でのみ計算されます。 このメソッドは絶対位置では機能しません。したがって、注目の重みの式はモデル内で再パラメータ化されます。絶対位置エンコーディング ベクトルは、マーカー位置間の距離の正弦とすべての位置に共通のトレーニング可能なベクトルに基づいた固定行列に置き換えられます。 5. ERNIE 清華大学、ファーウェイ / 2019 ナレッジ グラフ内の名前付きエンティティに関する情報を BERT に埋め込みます。入力は、テキスト トークンのセットとエンティティ トークンのセットで構成されます (各トークンはエンティティ全体を表します)。テキスト トークンは BERT によってエンコードされます。 BERT の上には、K 個のエンコーダ ブロックのセットがあります (ネットワーク パラメータの約 3% を占めます)。これらのブロックでは:テキスト タグの更新ベクトルとエンティティ タグの元のベクトルが最初に個別に計算されます;
- エンティティ ベクトルは最初に出現したときと比較されますテキスト タグの一致;
- は GeLU を使用してアクティブ化され、テキスト タグの新しい非表示表現を取得するために使用されます;
- テキスト タグとエンティティ タグの新しいベクトルは、非表示表現から取得され、次のエンコーダ ブロックへの入力として渡されます。
- 事前トレーニング中に、MLM、NSP、トークンからのエンティティ予測 (オートエンコーダーなど) の 3 つの損失が計算されます。オートエンコーダーは次のルールを使用します:
In 5% のケースでは、エンティティは間違ったエンティティに置き換えられますが、一致は保持されており、モデルは正しいエンティティを予測する必要があります。
- 15% のケースでは、一致は削除され、モデルは次のことを行う必要があります。テキストに基づいてエンティティのみを予測します。その他の場合は
- が正常です。
- 事前トレーニングされたモデルは、通常の BERT モデル (CLS トークンを使用) と同様に微調整できます。追加の手順を使用して、エンティティとそのタイプの間の関係を決定する微調整を行うこともできます。
- トレーニング中、損失計算ではマスク マークのみが計算されます。
- 個々のマーカーのみがマスクされ、マスクされた 1 つのマーカーの予測は他のマーカーの予測には影響しません。
- 実際のアプリケーションには、モデルがトレーニング中にアクティブに認識する MASK トークンはありません。
XLNet は、置換言語モデリング (PLM) タスクを除き、Transformer-XL に基づいています。このタスクでは、MASK を直接使用するのではなく、短いコンテキストでトークンを予測する方法を学習します。これにより、すべてのマーカーに対してグラデーションが確実に計算され、特別なマスク マーカーが不要になります。
コンテキスト内のトークンはスクランブルされています (たとえば、i 番目のトークンは i-2 および i-1 トークンに基づいて予測できます) が、それらの位置はまだわかっています。これは、現在の位置エンコーディング (Transformer-XL を含む) では不可能です。コンテキストの特定の部分でトークンの確率を予測しようとする場合、モデルはトークン自体を知る必要はありませんが、コンテキスト内でのトークンの位置を知る必要があります。この問題を解決するために、セルフ アテンションを 2 つのストリームに分割しました。
- 各マーカー位置には、1 つではなく 2 つのベクトル (コンテンツ ベクトルとクエリ ベクトル) があります。
- コンテンツ ベクトルにはトークンに関する完全な情報が含まれますが、クエリ ベクトルには位置情報のみが含まれます。
- トークンのベクトルは両方ともコンテキスト ベクトルに基づいて計算されますが、セルフ アテンションのクエリ ベクトルは過去のコンテンツ ベクトルを使用して計算され、コンテンツ ベクトルは過去のクエリ ベクトルを使用して計算されます。
- クエリ ベクトルは、対応するトークンのコンテンツに関する情報を受け取りませんが、コンテキストに関するすべての情報を知っていますが、コンテンツ ベクトルには完全な情報が含まれています。
微調整中にクエリ ベクトルを無視すると、モデルは通常の Transformer-XL と同様に機能します。
実際には、モデルが正しく学習するにはコンテキストが十分に長い必要があります。 RoBERTa と同じ量のデータを学習し、同様の結果が得られましたが、実装の複雑さのため、このモデルは RoBERTa ほど普及しませんでした。
7、ALBERT Google / 2019
品質を犠牲にすることなく BERT を簡素化:
- 異なるエンコーダ ブロックで共通のパラメーターを使用し、自己注意を共有することはできますが、完全に接続されたレイヤーの重みを分割すると品質の低下につながります。
- BERT と比較すると、より小さな入力埋め込みとより大きな隠れ層ベクトルが使用されます。これは、ネットワーク入力で追加の射影行列を使用することで実現できます。これにより、埋め込みのサイズが隠れた表現のサイズから分離されます。
- モデルのパラメーターは 18 倍減少し、実行速度は 1.7 倍増加します。
モデルは、MLM と文順序予測 (SOP) でトレーニングされています。
8、DistilBERT Google / 2019
BERT を最適化するもう 1 つの方法は蒸留です:
- エンコーダー ブロックの数が半分になります
- 3 つの損失コンポーネント: MLM、教師モデル出力とのクロスエントロピー、および対応するレイヤー出力間のコサイン距離。
- このモデルは、教師モデルより 40% 小さく、60% 高速であり、さまざまなタスクにわたって 97% の品質を維持します。
9、LaBSE Google / 2020
BERT に基づく多言語ベクトル化モデル。 MLM と TLM でトレーニングされ (マーカーの 20% がマスクされます)、微調整されます。 100 以上の言語をサポートし、50 万のタグ付き語彙が含まれています。
10、ELECTRA Google、スタンフォード大学 / 2020
敵対的生成手法を使用して BERT トレーニングを高速化:
- 2 つの BERT のようなモデルをトレーニングしました: 小型ジェネレーターとメインの識別子
- ジェネレーターは MLM でトレーニングされ、マスクされたトークンで満たされます
- ディスクリミネーターは、ジェネレーターによって生成されたテキストのオリジナリティを予測するようにトレーニングされます (置換検出タスク)
- トレーニングが完了したら、ジェネレーターを削除し、ディスクリミネーターで微調整します。
トレーニング データ量は RoBERTa や XLNet と同じで、モデルは BERT、RoBERTa よりも高速ですと ALBERT Learn は同等の品質です。トレーニングが長くなるほど、パフォーマンスが向上します。
11、DeBERTa Microsoft / 2020
マーカー ベクトルの内容と位置を 2 つの別々のベクトルに分離する別のモデル:
- 位置ベクトルは共有にあります。すべてのレイヤー間で、相対的なものです。つまり、マーカー間の可能な距離ごとに 1 つ存在します。
- 2 つの新しい重み行列 K_pos と Q_pos を追加しました。
- 注意の重みの計算を変更し、次の 3 つの積の合計に単純化します。 Q_cont * K_cont Q_cont * K_pos K_cont * Q_pos
- ALBERT と同様に、射影行列を使用して埋め込みサイズと埋め込みサイズを結合します。非表示サイズ マーカーはベクトルのサイズ分離を表します。
GPT および T5 に類似したモデル
完全なトランスフォーマーに基づいたモデル。そのアプリケーションの範囲は非常に幅広く、前のセクションのタスクに加えて、会話エージェント、機械翻訳、論理的および数学的推論、コード分析と生成、そして基本的にテキスト生成が含まれます。最大かつ「最もスマートな」モデルは通常、デコーダ アーキテクチャに基づいています。このようなモデルは、多くの場合、微調整を行わなくても、少数ショット モードやゼロショット モードで良好なパフォーマンスを発揮します。
1、GPT-2 OpenAI / 2018
デコーダーは、因果的 LM (左側のコンテキストに基づいて次のトークンを予測する) のタスクでトレーニングされます。アーキテクチャの観点からは、いくつかの小さな変更があります。各デコーダ ブロックからクロスアテンション レイヤーを削除し、LayerNorm
を使用します。使用されるトークナイザーはバイトレベルの BPE (50K 語彙) であり、("dog"、"dog!"、"dog.") などの類似の部分文字列は使用されません。シーケンスの最大長は 1024 です。レイヤー出力は、以前に生成されたすべてのタグをキャッシュします。
2、T5 Google / 2019
MLM に関する完全な事前トレーニング (トークンの 15% がマスクされる)、コードによってマスクされるスパン (
トークン マスキング
トークンの削除
- トークン充填
- 文内のトークンの順序を逆にする
- #ランダムなトークンをシーケンスの先頭にします
- ##バイトレベルの BPE を使用します (語彙サイズは 50K)
- #4. CTRL Salesforce / 2019
- プレフィックス コード トークン (例:
6 および mT5 Google / 2020
は T5 モデルに基づいており、同様のトレーニングを受けていますが、多言語を使用していますデータ。 ReLU アクティベーションは GeGLU に置き換えられ、語彙は 250K トークンに拡張されました。 7、GLAM Google / 2021このモデルは概念的には Switch Transformer に似ていますが、微調整よりも少数サンプル モードでの作業に重点を置いています。さまざまなサイズのモデルは、32 ~ 256 のエキスパート レイヤー (K=2) を使用します。 Transformer-XL の相対位置エンコーディングを使用します。トークンの処理時にアクティブになるネットワーク パラメーターは 10% 未満です。 8、LaMDA Google / 2021gpt に似たモデル。このモデルは、因果的 LM で事前トレーニングされ、生成タスクと識別タスクで微調整された会話モデルです。モデルは外部システム (検索、翻訳) を呼び出すこともできます。 9、GPT-NeoX-20B EleutherAI / 2022このモデルは GPT-J に似ており、回転位置エンコーディングも使用します。モデルの重みは float16 で表されます。シーケンスの最大長は 2048 です。 10. BLOOM BigScience / 2022 これは、46 の言語と 13 のプログラミング言語で構成される最大のオープンソース モデルです。モデルをトレーニングするには、ROOTS と呼ばれる大規模な集約データセットが使用されます。これには、約 500 のオープン データセットが含まれます。 11、PaLM Google / 2022これは大規模な多言語デコーダー モデルであり、Adafactor を使用してトレーニングされ、事前トレーニング中にドロップアウトを無効にし、微調整中に 0.1 を使用します。 12、LLaMA Meta / 2023科学研究に使用されるオープンソースの大規模な gpt のような LM であり、複数の命令モデルのトレーニングに使用されています。このモデルは、pre-LayerNorm、SwiGLU アクティベーション、および RoPE 位置埋め込みを使用します。オープンソースであるため、これはコーナー追い越し用の主要モデルの 1 つです。 テキストのガイダンス モデルこれらのモデル キャプチャは、モデル出力 (RLHF など) を調整して、対話およびタスク解決時の応答品質を向上させるために使用されます。 1、InstructGPT OpenAI / 2022この作品は、効率的に命令に従うように GPT-3 を適応させます。このモデルは、一連の基準に基づいて人間が良いと考えるヒントと回答で構成されるデータセットに基づいて微調整されます。 InstructGPT に基づいて、OpenAI は現在 ChatGPT として知られるモデルを作成しました。 2. Flan-T5 Google / 2022T5 に適したガイダンス モデル。一部のタスクでは、この微調整を行わなくても、Flan-T5 11B が PaLM 62B を上回りました。これらのモデルはオープンソースとしてリリースされています。 3、Sparrow DeepMind / 2022基本モデルは、レイヤーの最初の 80% がフリーズされた状態で、選択された高品質の会話でチンチラを微調整することによって取得されます。その後、モデルは、会話を通じてモデルをガイドする大きなプロンプトを使用してさらにトレーニングされました。いくつかの報酬モデルもチンチラの上で訓練されています。このモデルは検索エンジンにアクセスし、応答となる最大 500 文字のスニペットを取得できます。 推論プロセス中に、報酬モデルを使用して候補をランク付けします。候補はモデルによって生成されるか、検索から取得され、最適なものが応答となります。4, Alpaca Stanford University / 2023
LLaMA の上記の指導モデル。主な焦点は、GPT-3 を使用してデータセットを構築するプロセスにあります。
- 目標は、タスク - 入力 - 出力トリプルのセットを取得することです (入力は空にすることができます)。
- 人間は、回答を含む 175 のタスク プロンプトを生成し、それが GPT-3 に入力され、GPT-3 が新しいタスクを生成します。
- 生成プロセスは反復的であり、各ステップで人間によるいくつかのタスク例と、以前に生成されたタスク例からのいくつかが提供されます。
- GPT-3は、生成されたタスクを分類タスクと非分類タスクに分け、これに基づいて異なる入出力を生成します。
- トリプルは、品質とデータベース内の既存のトリプルとの類似性に基づいてフィルタリングされます。
合計 52,000 個の一意のトリプルが生成され、LLaMA 7B 用に微調整されました。
5、コアラ バークレー大学 / 2023
これは、命令データに関する LLaMA の微調整ですが、上記の Alpaca とは異なり、GPT などの大規模なモデルによってのみ生成されるわけではありません。 3 データを微調整します。データセットの構成は次のとおりです:
- 数学、詩、会話に関する 30,000 個の説明と回答のサンプル;
- アルパカ データセットからの 52,000 個のサンプル;
- に対する 160,000 個の回答有用性と有害性に関するユーザーの好みを含むモデル;
- ユーザーの質問と評価を含むモデルへの 20,000 の回答;
- 品質に関するユーザーの評価を含む 93,000 の概要;
GPT-3 と比較して品質の向上はありません。しかしブラインドテストでは、ユーザーはアルパカの回答よりもコアラの回答を好んだ。
テキストから画像を生成するモデル
テキストの説明に基づいた画像ジェネレーター。変換器と組み合わせた拡散モデルがこの分野を支配しており、画像生成だけでなくコンテンツ操作や解像度向上も可能にします。
1、DALL-E OpenAI / 2021
この作業は 2 つの段階で実行されます。画像のラベル付けに関するトレーニングと、テキストと画像の共同生成モデルの学習です。
最初のステージでは、dVAE がトレーニングされ、画像が 256x256x3 空間から 32x32xdim に変換され、またその逆に変換されます。dim は隠れた表現ベクトルの次元です。このようなマーカー ベクトルは合計 8,192 個あり、モデル内でさらに使用されます。
使用される主なモデルは、スパース トランスフォーマー デコーダです。テキスト トークンと画像トークンを入力として受け取り、モデルは同時分布 (Causal LM) を学習し、その後、テキストに基づいて画像トークンを生成できます。 dVAE は、これらと同じトークンに基づいてイメージを生成します。テキストタグの重量減少は 1/8、イメージタグの重量減少は 7/8 です。
テキスト タグの場合は、通常の埋め込みと位置による埋め込みがあり、イメージ タグの場合は、通常、列位置および行位置の埋め込みがあります。テキスト トークン シーケンスの最大長は 256 で、トークン化は BPE (16K 語彙) です。
2、GLIDE OpenAI / 2021
ピクセル レベルで動作し、テキストによって制御される拡散モデル (DM)。これは、畳み込み、アテンション、および残差接続を備えた U-Net アーキテクチャに基づいています。さまざまな方法を使用して生成を制御します。 CLIP
3 を使用して取得された画像ベクトルとテキスト ベクトルの内積、Latent Diffusion [Stable Diffusion] CompVis [Stability AI] / 2021 [2022]
ピクセル空間で動作する拡散モデル、主に次のものが含まれます2 つのモデル:
- 次元削減と潜在空間からの VAE オートエンコーダーの生成のための DM
- 内部表現
オートエンコーダーはガンでトレーニングされます。同様に、結果に弁別器を使用し、追加の正則化を適用して標準正規分布への近さを表します。
結果は潜在空間での DM デコードに入ります。条件がベクトルの場合、ステップの入力で潜在ベクトルと連結されます。ベクトルのシーケンスの場合、それは次の目的で使用されます。異なる U-Net レイヤーのクロスアテンション。テキスト ヒントには CLIP ベクトルを使用します。
この一般的なモデルは、テキストから画像への変換、カラー化、ペイント、超解像度など、さまざまなタスクに合わせてトレーニングできます。
4. Imagen Google / 2022
Imagen の背後にある主なアイデアは、テキスト エンコーダーのサイズを大きくすると、DM のサイズを大きくするよりも生成モデルにより多くのメリットをもたらすことができるということです。そこでCLIPをT5-XXLに置き換えました。
画像からテキストを生成するモデル
このセクションのモデルは、さまざまな性質のデータを分析しながらテキストを生成できるため、マルチモーダル モデルと呼ばれることがよくあります。生成されるテキストは、自然言語またはロボット用のコマンドなどの一連のコマンドです。
1、CoCa Google / 2022
別個の画像エンコーダー (ViT または CNN) 共有デコーダー。前半はテキストを処理し、後半は画像エンコーダーの出力と共通です。テキストを処理します。
288x288 の画像は 18x18 ブロックに分割され、エンコーダーはこれらすべてのベクトルの共有アテンション プールに基づいてそれをベクトルに変換します。
デコーダーの前半の出力は、テキスト ベクトルとシーケンスの最後にある CLS トークン ベクトルであり、sentencepece (64K 語彙) を使用してトークン化されます。テキストと画像のベクトルは、クロスアテンションを介してデコーダの後半でマージされます。
2 つの損失の重みは次のとおりです。
- 画像のアテンション プール ベクトルと画像説明ペアのテキストの CLS タグ ベクトルの間の類似性。
- デコーダ出力全体の自己回帰損失 (画像に応じて)。
微調整プロセス中、画像エンコーダをフリーズし、アテンション プールのみを微調整できます。
2. PaLM-E Google / 2023
画像は ViT によってエンコードされ、出力ベクトルおよびテキスト トークンとコマンドが PaLM に供給され、PaLM が出力テキストを生成します。
PaLM-E は、VQA、物体検出、ロボット操作などのすべてのタスクに使用されます。
3、GPT-4 OpenAI / 2023
これは、詳細がほとんど知られていない非公開モデルです。おそらく、スパースアテンションとマルチモーダル入力を備えたデコーダを備えていると思われます。自己回帰トレーニングと 8K ~ 32K のシーケンス長の RLHF 微調整を使用します。
人間の試験ではサンプルがゼロ、またはサンプルが少ない状態でテストされており、人間と同等のレベルに達しています。画像ベースの問題 (数学的問題を含む) を即座に段階的に解決し、画像を理解して解釈し、コードを分析して生成できます。少数言語を含むさまざまな言語にも適しています。
要約
以下は簡単な結論です。これらは不完全であるか、単に間違っている可能性があり、参考のためにのみ提供されています。
自動グラフィックス カードがマイニングできなくなってから、さまざまな大規模モデルが殺到し、モデルの裾野は拡大してきましたが、単純なレイヤーの増加とデータ セットの増大により、さまざまなモデルが置き換えられてきました。これらのテクノロジーにより、品質の向上が可能になります (外部データとツールの使用、ネットワーク構造の改善、新しい微調整技術)。しかし、一連の研究は、トレーニング データの量よりも質が重要であることを示しています。データ セットを正しく選択して形成することで、トレーニング時間を短縮し、結果の品質を向上させることができます。
OpenAI は現在、クローズド ソースに移行しており、GPT-2 の重みを解放しようとしましたが、成功しませんでした。しかし GPT4 はブラックボックスです. オープンソース モデルの微調整コストと推論速度を改善し最適化するここ数カ月の傾向により, 製品としての大規模なプライベート モデルの価値は大幅に低下しています. オープンソース モデルも急速に追い付いています品質的には巨人であり、コーナーでの追い越しが可能になります。
オープン ソース モデルの最終的な概要は次のとおりです。
- エンコーダー モデル ブロックでは、XLM-RoBERTa モデルと LaBSE モデルが信頼できる多言語ソリューションとみなされます。
- オープンな生成モデルの中で最も興味深いものは、LLaMA と EleutherAI のモデル (すべて微調整されたバージョンがあります)、Dolly-2、BLOOM (命令の微調整オプションもあります);
- コードの点では、SantaCoder のモデルは悪くありませんが、全体的な品質は ChatGPT/GPT-4 に比べて明らかに遅れています。
- Transformer-XL と Sparse Transformer は他のモデルで使用されているテクノロジを実装しており、慎重に検討してください。
上記は参考用です。
以上がトランスフォーマー レビュー: BERT から GPT4 への詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。